Hadoop经典案例Spark实现(六)——求最大的K个值并排序
Hadoop经典案例Spark实现(六)——求最大的K个值并排序
一、需求分析
b.txt
预测结果:(求 Top N=5 的结果)
Map任务代码
Reduce代码
Job提交
三、Spark实现-Scala版本
spark排序传入false参数即可倒序
一、需求分析
#orderid,userid,payment,productid
求topN的payment值
a.txt1,9819,100,121 2,8918,2000,111 3,2813,1234,22 4,9100,10,1101 5,3210,490,111 6,1298,28,1211 7,1010,281,90 8,1818,9000,20
b.txt
100,3333,10,100 101,9321,1000,293 102,3881,701,20 103,6791,910,30 104,8888,11,39
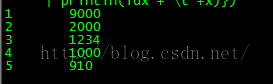
预测结果:(求 Top N=5 的结果)
1 9000 2 2000 3 1234 4 1000 5 910
二、MapReduce实现
因为MR默认是升序的因此要自定义输入类型
自定义倒充的整型输入
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class MyIntWritable implements WritableComparable<MyIntWritable> {
private Integer num;
public MyIntWritable(Integer num) {
this.num = num;
}
public MyIntWritable() {
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(num);
}
@Override
public void readFields(DataInput in) throws IOException {
this.num = in.readInt();
}
@Override
public int compareTo(MyIntWritable o) {
int minus = this.num - o.num;
return minus * (-1);
}
@Override
public int hashCode() {
return this.num.hashCode();
}
@Override
public boolean equals(Object obj) {
if (obj instanceof MyIntWritable) {
return false;
}
MyIntWritable ok2 = (MyIntWritable) obj;
return (this.num == ok2.num);
}
@Override
public String toString() {
return num + "";
}
}
Map任务代码
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TopNMapper extends Mapper<LongWritable, Text, MyIntWritable, Text> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString().trim();
if (line.length() > 0) {// 1,9819,100,121
String[] arr = line.split(",");
if (arr.length == 4) {
int payment = Integer.parseInt(arr[2]);
context.write(new MyIntWritable(payment), new Text(""));
}
}
}
}
Reduce代码
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class TopNReducer extends Reducer<MyIntWritable, Text, Text, MyIntWritable> {
private int idx = 0;
@Override
protected void reduce(MyIntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
idx++;
if (idx <= 5) {
context.write(new Text(idx + ""), key);
}
}
}
Job提交
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class JobMain {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = new Job(configuration, "topn_job");
job.setJarByClass(JobMain.class);
job.setMapperClass(TopNMapper.class);
job.setMapOutputKeyClass(MyIntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(TopNReducer.class);
job.setOutputKeyClass(MyIntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
Path path = new Path(args[1]);
FileSystem fs = FileSystem.get(configuration);
if (fs.exists(path)) {
fs.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
job.setNumReduceTasks(1);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
三、Spark实现-Scala版本
val six = sc.textFile("/tmp/spark/six")
var idx = 0;
val res = six.filter(x => (x.trim().length>0) && (x.split(",").length==4)).map(_.split(",")(2)).map(x => (x.toInt,"")).sortByKey(false).map(x=>x._1).take(5)
.foreach(x => {
idx = idx+1
println(idx +"\t"+x)})
spark排序传入false参数即可倒序