实时嵌入式软件开发的25个常见错误(二)
#24 基于单一架构的归纳
嵌入式软件的设计者可能需要开发能运用在不同的处理器上的软件。在此情况下,编程人员通常会先在其中的一种开发平台开始编软件,但是会在晚些时候为包装代码而做大量的准备工作。
不幸的是,这样做通常弊大于利。这种设计试图过份的归纳出不同架构下的相同点,而不是不同点,但是设计者并不能预见到这些不同点。
一种比较好的设计策略是在多个架构下同步设计和开发代码,归纳出那些不同架构下的差别,有意地挑选3到4种差别较大的处理器(比如不同开发厂商的产品或是采用不同架构设计的产品)
#23 一个大循环
当实时操作系统的代码被设计成一个单独的大的循环体,我们就无法独立地修改不同部分代码的执行时间了。很少有实时系统需要所有的模块都以同样的速率运行。如果CPU超负荷,其中一项可以利用来降低CPU占用率的方法是减慢部分非关键代码的运行速度。然而这种方法只对RTOS的多任务操作系统奏效,否则代码就是设计成基于灵活风格或商业实时运行环境中。
#22 超负荷设计系统
如果处理器和存储器的平均利用率小于90%,而峰值利用率小于100%,那么我们就说这个系统属于超负荷设计。对于设计者而言,写程序使用过多的资源实在是一种奢侈的行为。在某种情况下,这种奢侈能直接导致盈利和破产的区别!软件工程师有责任尽量减少一个嵌入式系统的价格和能源消耗。如果CPU的利用率只有45%,那么就可以使用运行速度只有一半的处理器,因而减少了4倍的能量,而且可能每个处理器还能省下1美元或者更多的钱。
如果这个产品大批量生产,每个处理器省下1美元,仅这一项整个产品就能省下100万美元。如果该产品是电池驱动的,电池就可以延长寿命,从而提升该产品的市场上的需求量。作为一种计算机家族中电源消耗的一种极端例子——便携机,一般使用一种很沉的电池,最多能使用3个小时。而一块手表,重量轻,电池便宜,却能使用3年!尽管软件通常和能量消耗没有直接的关系,但它确实扮演了一个重要的角色。
使用快速的处理器和更多的内存确实导致设计者懒于考虑这方面的设计。建议开始设计时先考虑低速的处理器和少一些的内存,而只有在实际需要的情况下再升级处理器。如果我们的软件能利用更高效的硬件就更好一些,我们就不会是采用一个高速的处理器,然后却要尽量删除一些周边部件来降低系统成本。
#21 在开始软件设计之前没有分析硬件特性
两个8-bit数相加需要多少时间?16-bit?32-bit?两个浮点数相加呢?还有一个8-bit数加上一个浮点数呢?如果软件设计者不能在头脑中立即反应,针对他使用的处理器回答出上述问题,说明他还没有为设计和编制实时软件做好充分的准备。
下面是一个6MHZ的Z180处理器的例子,针对以上问题的答案是(us为单位):7,12,28,137,308!值得注意的是:浮点数加一个字节的时间要比浮点数加一个浮点数的时间多出250%,主要原因是中间增加了很多从字节转换到浮点数的时间。这种不规则操作往往是导致处理器过载的源头。
另一个例子,一种专用来处理浮点数的加法器处理浮点加法/乘法的速度比33MHZ处理器68882快将近10倍,但是sin()和cos()函数的处理时间相同。主要原因是68882处理器有一个内置于硬件的三角函数处理器,而浮点数加法器只能通过软件处理。
当需要为一个实时系统编写软件时,首先要考虑的是键入计算机的 每一行代码相关的实时性问题。要理解使用的处理器的性能和限制,并且如果执行代码使用了大量的长指令,最好重新设计应用程序。比如说,对于Z180,最好全部使用浮点数运算,而不要采用部分变量使用浮点数,而另一部分为整数的设计,因为这样会带来大量的混合运算。
#20 第一次设计时过度优化
与第21个问题相反的一个问题也是一种通用的错误。一些编程者预见到了这种不规则现象(有些是很实际的,有些则有些奇怪)有一种奇怪的不规则现象的例子就是乘法比加法要长得多。一些设计者会将3*x写成x+x+x.而在有些嵌入式处理器中,乘法比加法处理时间的两倍要少一些,因此x+x+x的处理时间比3*x要慢一些。
一个能预见所有的不规则现象的编程人员可能会为了优化代码,将第一个版本的代码编得可读性很差。那是因为他并不知道是否真正需要优化。一般的原则是,在实现过程中不要使用完全优化。
以后,如果已经证明优化后性能提高,再对代码实施优化。如果不需要优化,则还是保留可读性较好的代码。如果CPU过载,那么最好知道,代码中仍有很多地方可以采用直接优化的方式就能使性能得到明显提高。
#19 “只不过是小故障而已”
有些编程人员往往一次又一次地使用同一个工作区,因为系统有一处小BUG。编程人员的典型的反应是,只要是使用过的工作区就能一直运行正常。殊不知,影响一个工作区的错误可能在不同时候表现出不同的形式。不管任何时候,只要存在“小故障”,它就说明系统中确实存在一些问题。最好的方法是按照适当的方法一步一步将问题的本质理解清楚。使用一个工作区可能可以保证按时交差,但是如果多花一点时间,查出问题,保证问题在任何时候都不重现,如下一次重要演示会,可能意义更大,虽然可能会比期限时间晚一些完成。
#18 模块间耦合性太强
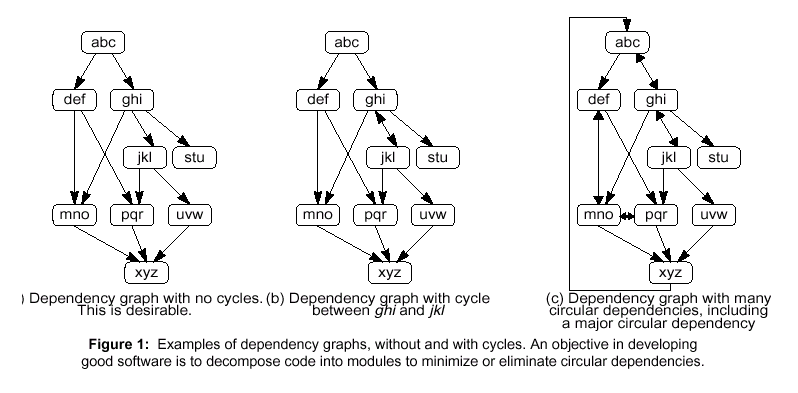
好的软件设计中,模块之间的耦合关系可以被描述成一个树状结构,就象图1(a)中所示。从属关系图是由节点和箭头组成,每一个节点代表一个模块(例如:一个源代码文件),而每个箭头标明这个模块所依赖的其他模块。位于最底层一行的模块不依赖于任何其他的软件模块。为使软件重用性最大化,箭头方向应当是向下,而不是向上或双向的。例如:图中abc模块如果在其代码中有:#include "def.h" 或在abc.c文件中有用extern声明的def.c文件中所定义的变量或者是函数,那么它就依赖于def模块。
模块的耦合关系图是一项非常有价值的软件工程工具。通过这张图,可以轻易地做以下工作:
(1)识别软件的哪些部分可以被重用;
(2)为模块的测试工作建立一种策略;
(3)为限制错误在整个系统中的传播提供一种方法。
每一个环状的依赖关系(例如:在图中的环状连接)都会降低软件模块的重用能力。测试工作只能针对相互关联的模块集,问题将很难被孤立到一个独立的模块中。如果在从属关系图中有太多这样的环状连接,或者在图中最底层模块与最高层模块之间存在这样的环状连接,那么整个软件将没有一个独立的模块是可以重用的。
图1(b)和(c)都包含这种环状的依赖关系。如果这样的循环依赖关系是不可避免的,那么宁愿选择(b)而不是选择(c),因为在(b)中仍有部分模块是可以重用的。图1(b)中的限制是模块pqr和xyz只有接合在一起才能被重用。而在图1(c)中,由于在模块之间耦合性太强,没有一个子模块是可以重用的。还有,由于有一个大的环状依赖关系,即使是模块xyz,本来它位于关系图中的最底层,应该不依赖于任何其他模块,现在却要依赖于模块abc。仅仅是因为这样一个大环,就导致整个应用程序的所有模块都不可以重用。不幸的是,目前绝大多数应用程序都更类似于(c),而不是(a)和(b),因此也导致我们现存应用程序中软件模块重用的困难。
要更好的使用依赖关系图来分析软件的可重用性和可维护性。在编写代码的时候就注意使代码更容易生成关系图。这意味着,在模块xxx中,函数中用extern声明的所有外部变量都要在文件xxx.h中定义。在模块yyy中,只要简单的察看一下有哪些头文件用#include包含了,就可以明确所依赖的模块。如果不遵守上面的规则,yyy.c中存在extern声明而不是用#include包含相应的文件,那么将导致依赖关系图的错误,同时导致试图重用那些看起来似乎是独立于其他模块的代码将非常困难。
#17 “最后期限临近”!没有时间休息
很多程序员会为一个问题,连续工作几个小时而废寝忘食。他们连续工作的主要原因是因为有“最后期限”,这样的最后期限可能是公司里产品开发的截止时间,或学校布置的家庭作业完成时间。但事实上,如果你在连续工作了一个小时而没有任何进展的时候稍做休息,往往可以“节省”很多的时间。你可以沿着湖边转转、来杯啤酒、打个盹什么的...
清醒的大脑来部分源于精神的放松,它使你更容易分析发生了什么,更快的找出问题解决的方案。即使是在“最后期限临近”的时候,也不要忘了两个小时的休息,可能节省一整天的时间;离开电脑10分钟的短暂休息,往往会节省一个小时的时间。
续篇:http://blog.csdn.net/myaccella/article/details/7007132