搜索引擎早期重要论文推荐系列【6】
AlphaSort: A Cache-Sensitive Parallel External Sort
Chris Nyberg, Tom Barclay, Zarka Cvetanovic, Jim Gray, Dave Lomet
这篇论文严格来说和搜索引擎关系不大,这里做推荐,只是因为这是我刚刚搞搜索引擎的时候阅读的一片论文。这篇文章写得非常易懂,其中对编程过程中特别需要考虑的cache line等细节问题,关于外排序不同key/value存储方案的分析,都非常有趣,其中prefix-key/value的方案,记得在某一期pennysort的比赛中也有用到过,是非常不错的cache-sensitive的想法。文章的实验做得也很不错,堪称论文典范。特别请大家注意这是一篇1995年的论文,阅读时请考虑时代背景。
以下就其精彩部分做简要分析
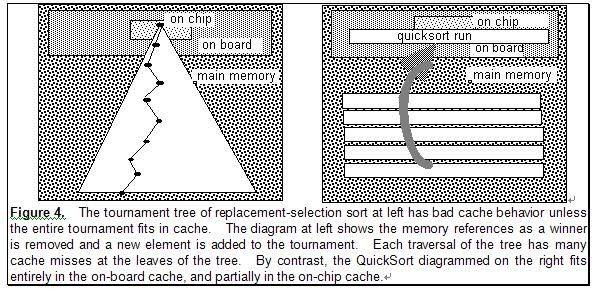
本文特别之处转换选择排序,除非整个排序树能放在cache中,否则就没有QuickSort的局部性好,排序段大部分在二级缓存,部分在芯片缓存中。(在当时,on-board cache指得就是L2 cache,就像内存一样插在板卡上的,因此得名,而L1 Cache是集成在芯片中的)。
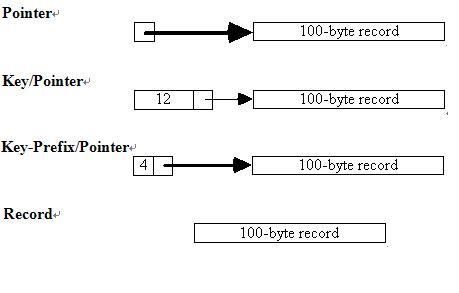
快排时,key value的四种存储方案,作者作了分析和测试,其中cache最友好的方案key/pointer和keyprefix/pointer最好,这两种方案还是普遍被采用的。
文中提出了key array需要在cache line size上对齐。
linux可以通过如下命令,获得cache line size
size_t L1_Cache = sysconf(_SC_LEVEL1_CACHE_SIZE)
并且代码编译时使用#pragma DATA_ALIGN(array, 32) //假定检测的结果cache line size为32
编译器会自动将该数组的地址放在末5尾为0的地址上。
(3)文中提到了这样一个多核计算的方(其中CPU affinity在此前的博客中有介绍)
作者使用的是6核CPU共享内存的方式,作者没有交代,我想应该是mmap的方式。
其中root process affinity到0号处理器,另外的5个worker分别affinity到各自编号的处理器上。
root process负责文件的读写(排序文件的读入,有序文件的merge和写入)。worker从事的是memory-intensive的工作。
(4)文件读写瓶颈的处理
作者提到了Raid0加速磁盘读写,异步IO读写,有助于提高磁盘读写效率,将可能合并的IO进行合并。
下载地址:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.81.9593&rep=rep1&type=pdf
其他推荐阅读:http://www.rosoo.net/a/embedded_o/201003/8635.html