数字集成电路设计-16-关于AXI协议
引言
AXI协议有可能是我们平时电路设计时经常遇到的一个协议,也是一个不错的协议,本小节我们就来熟悉一下。
乍一看,AXI协议的信号众多,眼花缭乱,容易发蒙。但其实其基本思想很简单。只要掌握以下几点:
1,valid/ready协议
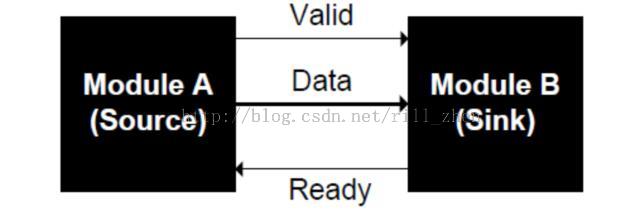
valid/ready协议的优势就是master和slave的相对独立性比较好。
对于一次传输,作为master的发起方不用检查salve是否准备好,就可以将传输内容放到总线上;
同样对于接收方的slave来说,只要可以接收新的数据,就可以将ready信号放到总线上,也不用等待master发起传输。
valid/ready协议可以有效的将master和slave解耦合,也可以有效地减少‘传输握手’的开销。
这和一般的‘request/ack’串行协议不同。比如,AHB,APB,wishbone等片内总线协议。
由于valid/ready协议有上述优势,所以在实际的数字设计时被普遍采用,不仅用于片内总线,各个模块之间的数据交换,也可以采用valid/ready协议。
关于valid/ready协议,有一篇论文可以参考:
EECS150: Interfaces: “FIFO” (a.k.a. Ready/Valid)UC Berkeley College of Engineering
Department of Electrical Engineering and Computer Science
2,乱序
AXI协议是支持乱序传输的协议,也就是说master连续发起了两次传输,对于slave的应答顺序和master的发起顺序可以是不同的。AXI是如何实现乱序传输的呢?有两点非常重要,就是ID和并行。关于ID,我们需要引起足够的重视,在AXI协议的SPEC里面的信号列表里把他放在了第一个,可见这个ID的重要程度。可以这么说,没有ID这个信号,就不能实现乱序。此外,在实际应用中,ID还可以承担除了‘乱序’这一重要任务外,其它重要的任务。比如可以把来自不同CPU的信息放在ID里面等等。。。。。。当然也可以把所有额外的信息放到USER信号来承担,但考虑兼容性,放到ID里面会好一些。3,并行
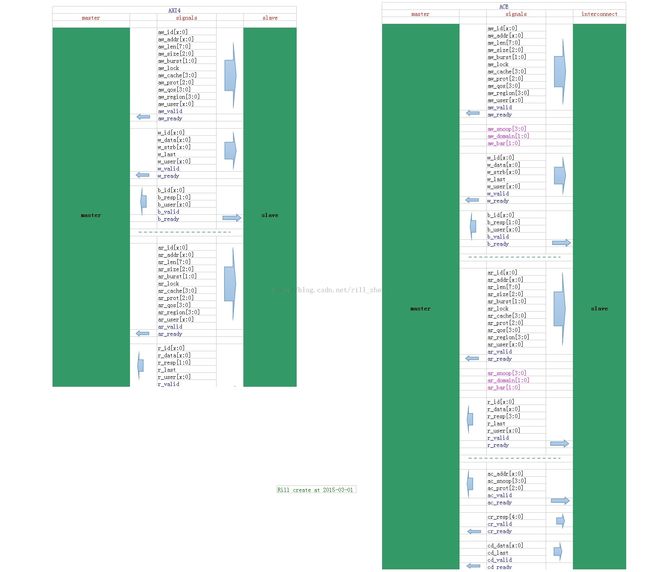
关于并行,‘通道分离’是并行能实现的潜在基础。通道分离,很容易理解,指的是AXI将不仅将读写操作分开了,而且将读写操作用到的信息分成了不同的通道。
写操作分成了3个通道,读操作分成了2个操作。
说到这里,有一点需要提醒一下:从哲学角度来说,读操作和写操作是对称的,是对等的,一写一读,一去一回,没有读哪来写,没有写何必读,就好像太极图里面的一黑一白,多么的和谐与对称。为什么AXI协议里写操作有3个通道,读操作却只有2个通道,这是明目张胆的对读操作的歧视啊!这是为什么呢?
我认为可以从两个角度来解释?
首先,可能和一致性相关。resp通道的一个重要的责任就是解除一致性(WAW,WAR,RAW),试想如果把读操作的rdata和rresp拆分成两个独立的通道,又有什么奇葩的情景下中会出现后面的写操作还没有得到读操作返回的数据就可以解除一致性呢?!!也就是说即使应读操作的强烈要求,将其也分成3个独立的通道,也不会出现rdata和rresp异步的情况,既然拆分出来的两个通道都是同步的,那么就没有必要拆分了。
其次,可能和哲学有关,读写看似平等,实际上却存在不平等,比如有WAW依赖,却没有RAR依赖,世界本来就是不平等的,你读操作何必一定要和写操作处处平等,把你和写操作拆分开就已经是高看你了,实在不爽的话,就把读写放到一起,就变成了低速,高耦合度,串行,不能乱序的协议啦,比如AHB,APB或者wishbone。
合则串行,分则并行,是合是分,合则慢,分则快,自己选吧。
当然也不是说‘合’就一无是处,‘合’会大大降低信号的数量。
是追求传输速度还是追求信号线数目少,自己选吧。
4,依赖
说完并行,再说依赖。并行和依赖也是一对矛盾。从大的角度来看,对于读/写,大多数情况下可以认为是并行的,但是读写的地址存在冲突时,读/写又存在依赖。
从小的角度来看,单纯对于写操作,AW、W、B三个通道从形式上看是独立的并行的,但是三个通道在逻辑上又存在一定的依赖。
比如,master的W通道的写数据允不允许比AW通道的写地址先发到总线呢?允许可以,不允许也可以。
如果不允许,W通道的ID信号是否可以去掉不用呢?答案是可以去掉,只要保证去掉之后WDATA发到总线上的顺序和AW通道的数据发到总线上的顺序一致就可以,而这个保证很容易做到。
slave的B通道上的valid允不允许比AW和W通道上的valid早发出去呢?
很显然是不允许的,试想,slave还没有接收完数据就告诉master你接收完了,不出错才怪。
当然,什么事情都不是绝对的,如果在AXI标准协议的基础上再对master和slave增加一些约束,slave的Bvalid也是允许比AW和W两个通道的valid早发出去的,这就是ARM A9中使用的对于写操作的奇葩的‘Early resp’。
5,barrier传输
其实,标准的AXI4里面并没有barrier传输,在ACE协议里面才有,ACE是针对多核系统的一致性总线协议。但是有时候,单核的系统中对barrier传输的需求也是很迫切的(比如CPU需要和DMA设备同步时),但是有不想全面支持ACE协议,怎么办呢?
可以单纯引入ACE中的‘bar’信号。
对于barrier。需要搞清楚两点即可:
第一,什么是barrier之前的操作,什么是barrier之后的操作;
barrier之前的操作是指,各自通道(AW/AR)上的barrier信号有效之前所发出的操作。barrier之后的操作是指,各自通道上resp(bresp/rresp)返回之后所发出的操作。这里需要注意的是,有一些操作是在‘barrier信号发出之后,resp信号回来之前’发出去的,他们既不属于barrier之前的操作,也不属于barrier之后的操作,属于什么呢?他们就是所谓的‘outstanding 操作’。
第二,memory barrier和synchronization barrier的区别是什么。
关于memory barrier和synchronization barrier,我的理解是:
memory barrier的要求是,以barrier这条命令的resp信号回来为界线(不考虑outstanding的话),保证它后面发的命令能看到前面发的命令的结果即可。
system barrier的要求是,以barrier这条命令的resp信号回来为界线,要保证它前面发出的命令要彻底完成,即不能只被cache下来。
举两个可能的使用场景:
memory barrier:
一个物理CPU(可以多个逻辑核)上面跑了两个线程,其中一个线程(A)更新一个数组,更新完成之后需要告诉另外一个线程(B),线程B读更新之后数组的值。
对于这种场景,线程A更新完数组之后,发一个memory barrier命令就能保证线程B能读到更新后的值。
system barrier:
一个物理CPU(可以多个逻辑核)上面在跑一个线程,这个线程更新一个数组,更新完之后需要告诉VPU,VPU读更新之后的数组的值。
对于这种场景,CPU上面的那个线程更新完数组之后,发一个system barrier命令才能保证VPU读到更新后的值。如果只发一个memory barrier命令,最新的值可能被缓存在L1/L2 cache中,导致VPU读到旧值。
6,小结
总之,AXI是一个很不错的协议,但是在使用过程中要有自己的想法,可以适当做一些变通。毕竟,协议是ARM定的,但电路是你自己设计的。鞋子合不合脚,只有你知道的最清楚。
7,附录 AXI4 Vs ACE