稀疏编码及其改进(ScSPM,LLC,super-vector coding)
1 稀疏表达说起
http://blog.sciencenet.cn/blog-261330-808758.html
这里面追本溯源的介绍为什么要进行稀疏表达以及数学优化表达式的推导过程,通俗易懂,适合入门。
稀疏编码的改进
2 深入稀疏编码
http://www.cnblogs.com/tornadomeet/archive/2013/04/14/3019885.html
系列文章Deep learning:二十六(Sparse coding简单理解)
Deep learning:二十七(Sparse coding中关于矩阵的范数求导)
Deep learning:二十八(使用BP算法思想求解Sparse coding中矩阵范数导数)
Deep learning:二十九(Sparse coding练习)
4 改进
4.1 ScSPM
Linear Spatial PyramidMatchingusing Sparse Coding for Image Classification (CVPR'09)
An extension of the SPMmethod, bygeneralizing vector quantization to sparse coding followed bymulti-scalespatial {max pooling}, and propose a linear SPM kernel based onSIFT sparsecodes. This new approach remarkably reduces the complexity of SVMsto O(n) intraining and a constant in testing. In a number of imagecategorizationexperiments, we find that, in terms of classification accuracy,the suggestedlinear SPM based on sparse coding of SIFT descriptors alwayssignificantlyoutperforms the linear SPM kernel on histograms, and is evenbetter than thenonlinear SPM kernels, leading to state-of-the-art performanceon severalbenchmarks by using a single type of descriptors.
The algorithm is composed of the following parts:
a. SIFTdescriptorextraction.
b. Sparse coding. WeintegratedHonglak Lee's Matlabcodes fordictionary learning.
d. Linear SVMclassification. Weimplemented an efficient linear SVM with squared hinge lossfunction.
Combining sparse coding with spatial max pooling, thealgorithmleads to state-of-the-art performance on Caltech 101 based on SIFTdescriptor.The most encouraging part of this algorithm is that the extractedfeaturefavors linear model,andthus can be easily scaled up to large dataset. Currently, the sparsecodingprocess is kind of slow. However, it can be easily speeded up byparallelcomputing or approximation using neural networks to real-applicationlevel.
Download
Matlab codes
Paper
4.2 LCC
Kai Yu等发在NIPS09上面的文章《Nonlinear learning using local coordinate coding》,作者做实验发现,稀疏编码的结果往往具有局部性,也就是说非零系数往往属于与编码数据比较接近的基。作者提出的局部坐标编码(LCC)鼓励编码满足局部性,同时从理论上指出在一些特定的假设下,局部性比稀疏性更加必要,对于一些非线性学习能够获得非常成功的结果。

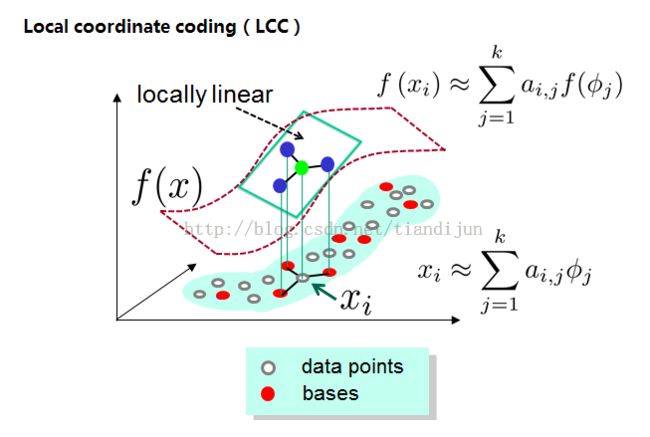
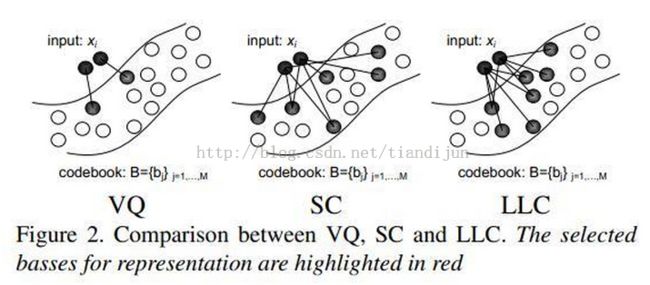
相比于前两个算法,其优势有:可以获得非常小的重构误差,能够获得局部平滑的稀疏性,由于码本过完备,稀疏编码为了满足稀疏性,对于相似的patch可能会选择一些完全不同的基,这样丢掉了编码之间的相关性。而LLC很明显对于相似的patch其编码肯定会是相似的。
4.3 LLC http://www.ifp.illinois.edu/~jyang29/LLC.htm
文章来源于CVPR10,即《Locality-constrained Linear Coding for Image Classification》,在其前一篇的基础上再次做出改进。前一篇引入了稀疏编码和最大化pooling技术,采用线性SVM对空间金字塔特征集分类,本文则引入了局部约束的概念,更进一步提高了计算效率和准确性。
The traditional SPM approachbased on bag-of-features (BoF) requires nonlinear classifiers to achieve goodimage classification performance. This paper presents a simple but effectivecoding scheme calledLocality-constrained LinearCoding (LLC) in place of VQ coding in traditional SPM. LLC utilizes the localityconstraints to project each descriptor into itslocal-coordinate system, and the projected coordinates are integrated bymax pooling to generate thefinal representation. With linear classifier, the proposed approach performsremarkably better than the traditional nonlinear SPM, achievingstate-of-the-art performance on several benchmarks. Compared with the sparsecoding strategy, the objective function used by LLC has an analytical solution.In addition, the paper proposesa fast approximatedLLC method by first performing aK-nearest neighbor search and then solving a smallconstrained least square fitting problem, bearing computationalcomplexity of O(M+K^2). Hence even with very largecodebooks, our system can still process multiple frames per second. Thisefficiency significantly adds to the practical values of LLC for realapplications.
The locality-constrained linear coding (LLC) algorithm follows thestandarddescriptor coding + spatial pooling strategy to extract features from the image:
- Local descriptor extraction from a dense grid on the image. We use dHoG (similar to SIFT) descriptors in this work.
- Nonlinear descriptor coding by LLC to transform each local descriptor into a sparse code.
- Multi-scale spatial pyramid max pooling over the sparse codes to get the final feature representation.
The advantages of this method are:simple, fast and scalable,and competitive with ScSPM [1] with linearclassifiers. The following table shows thecomparison of our algorithm with SPM [3] and ScSPM [1] in the literature.
| Table 1: Comparison of LLC with SPM and ScSPM |
|||
| Algorithms |
SPM |
ScSPM |
LLC |
| Local descriptors |
SIFT descriptors extracted from a dense grid on the image |
SIFT descriptors extracted from a dense grid on the image |
SIFT descriptors extracted from a dense grid on the image |
| Descriptor coding |
Vector quantization |
Sparse coding |
LLC |
| Sparse codes pooling |
Multiscale spatial average pooling (histogram) |
Multiscale spatial max pooling |
Multiscale spatial max pooling |
| Classifier |
Nonlinear (chi-square or intersection kernel) |
Linear |
Linear |
| Speed |
Fast |
Relatively slow |
Fast |
Experiment Results
Experimentresults are reported based on three widely used datasets: Caltech 101, Caltech256, and PASCAL VOC 2007. Only a single descriptor, thedHoG feature (similar toSIFT, but faster), is used throughout the experiments. In our setup, the dHoGfeatures were extracted from patches densely located by every 8 pixels on theimage, under three scales, 16x16, 25x25, and 31x31 respectively. The dimensionof each dHoG descriptor is 128. Please refer to the paper for more details.
Caltech 101 Dataset
Wetrain a codebok with 2048 bases, and used 4x4, 2x2, and 1x1 sub-regions forspatial max pooling. The images are resized to be no larger than 300x300 withpreserved aspect ratio. For classification, we use one-vs-all trained linearSVM.
| Table 2: Classification Results on Caltech 101 |
||||||
| Training Images |
5 |
10 |
15 |
20 |
25 |
30 |
| Zhang |
46.6 |
55.8 |
59.1 |
62.0 |
- |
66.20 |
| SPM |
- |
- |
56.40 |
- |
- |
64.60 |
| Griffin |
44.2 |
54.5 |
59.0 |
63.3 |
65.80 |
67.60 |
| Boiman |
- |
- |
65.00 |
- |
- |
70.40 |
| Jain |
- |
- |
61.00 |
- |
- |
69.10 |
| ScSPM |
- |
- |
67.00 |
- |
- |
73.20 |
| LLC |
51.15 |
59.77 |
65.43 |
67.74 |
70.16 |
73.44 |
Caltech 256 Dataset
Theexperiment settings are the same with Caltech 101, except that we use a largercodebook, containing 4096 bases. We do find that using a larger codebook helpsthe performance from what we have tried.
| Table 3: Classification Results on Caltech 256 |
||||
| Training Images |
15 |
30 |
45 |
60 |
| Griffin |
28.30 |
34.10 |
- |
- |
| Gemert |
- |
27.17 |
- |
- |
| ScSPM |
27.73 |
34.02 |
37.46 |
40.14 |
| LLC |
34.36 |
41.19 |
45.31 |
47.68 |
PASCAL 2007
Theresults are reported using the standard Average Precision (AP) for thischallenge competition. Note that our system only use onesingle descriptor and linear SVM.
| Table 4: Classification Results on PASCAL 2007 |
|||||||||||
| Object class |
aero |
bicyc |
bird |
boat |
bottle |
bus |
car |
cat |
chair |
cow |
|
| Obj.+Contex |
80.2 |
61.0 |
49.8 |
69.6 |
21.0 |
66.8 |
80.7 |
51.1 |
51.4 |
35.9 |
|
| Best PASCAL'07 |
77.5 |
63.6 |
56.1 |
71.9 |
33.1 |
60.6 |
78.0 |
58.8 |
53.5 |
42.6 |
|
| LLC |
74.8 |
65.2 |
50.7 |
70.9 |
28.7 |
68.8 |
78.5 |
61.7 |
54.3 |
48.6 |
|
| Object class |
table |
dog |
horse |
mbike |
person |
plant |
sheep |
sofa |
train |
tv |
average |
| Obj.+contex |
62.0 |
38.6 |
69.0 |
61.4 |
84.6 |
28.7 |
53.5 |
61.9 |
81.7 |
59.5 |
58.4 |
| Best of PASCAL'07 |
54.9 |
45.8 |
77.5 |
64.0 |
85.9 |
36.3 |
44.7 |
50.9 |
79.2 |
53.2 |
59.4 |
| LLC |
51.8 |
44.1 |
76.6 |
66.9 |
83.5 |
30.8 |
44.6 |
53.4 |
78.2 |
53.5 |
59.3 |
4.4 super vector coding
来自Image Classification Using Super-Vector Coding of Local Image Descriptors,还在学习中。
推荐一链接:http://www.xuebuyuan.com/2039010.html,详细解释了这几种改进方法的对比。
相关改进文章:
laplacian Sparse Coding
Shenghua Gao 高盛华(Author)
[] Shenghua Gao, Ivor Wai-Hung Tsang, Liang-Tien Chia and Peilin Zhao.Local features are not lonely-Laplacian Sparse Coding for image classification.CVPR 2010.
[] Shenghua Gao, Ivor Wai-Hung Tsang, Liang-Tien Chia. Laplacian sparse coding, Hypergraph Laplacian sparse Coding, and applications. Accepted by T-PAMI (2013,publish).
5 拓展
人脸识别: