Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
1 Tachyon介绍
1.1 Tachyon简介
随着实时计算的需求日益增多,分布式内存计算也持续升温,怎样将海量数据近乎实时地处理,或者说怎样把离线批处理的速度再提升到一个新的高度是当前研究的重点。近年来,内存的吞吐量成指数倍增长,而磁盘的吞吐量增长缓慢,那么将原有计算框架中文件落地磁盘替换为文件落地内存,也是提高效率的优化点。
目前已经使用基于内存计算的分布式计算框架有:Spark、Impala及SAP的HANA等。但是其中不乏一些还是有文件落地磁盘的操作,如果能让这些落地磁盘的操作全部落地到一个共享的内存中,那么这些基于内存的计算框架的效率会更高。
Tachyon是AmpLab的李浩源所开发的一个分布式内存文件系统,可以在集群里以访问内存的速度来访问存在Tachyon里的文件。Tachyon是架构在最底层的分布式文件存储和上层的各种计算框架之间的一种中间件,其主要职责是将那些不需要落地到DFS里的文件落地到分布式内存文件系统中来达到共享内存,从而提高效率。同时可以减少内存冗余、GC时间等,Tachyon的在大数据中层次关系如下图所示:
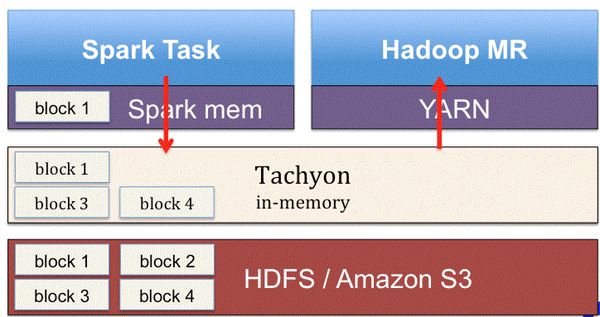
Tachyon允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和 MapReduce那样。通过利用信息继承、内存侵入,Tachyon获得了高性能。Tachyon工作集文件缓存在内存中,并且让不同的 Jobs/Queries以及框架都能以内存的速度来访问缓存文件。因此,Tachyon可以减少那些需要经常使用数据集通过访问磁盘来获得的次数。
1.2 Tachyon系统架构
1.2.1 系统架构
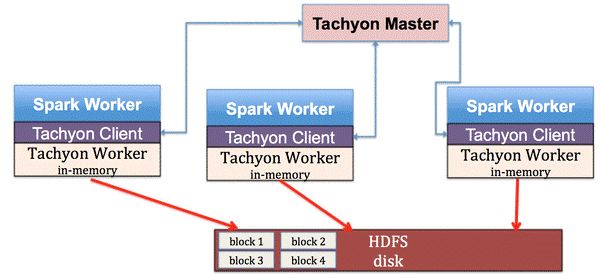
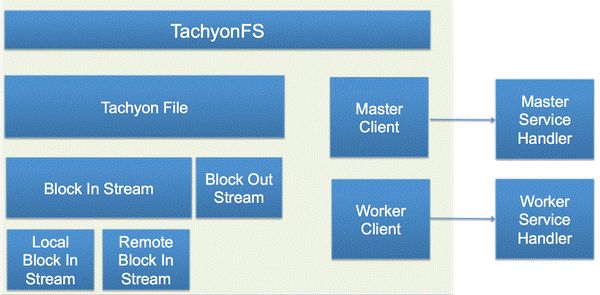
Tachyon在Spark平台的部署:总的来说,Tachyon有三个主要的部件:Master, Client,与Worker。在每个Spark Worker节点上,都部署了一个Tachyon Worker,Spark Worker通过Tachyon Client访问Tachyon进行数据读写。所有的Tachyon Worker都被Tachyon Master所管理,Tachyon Master通过Tachyon Worker定时发出的心跳来判断Worker是否已经崩溃以及每个Worker剩余的内存空间量。
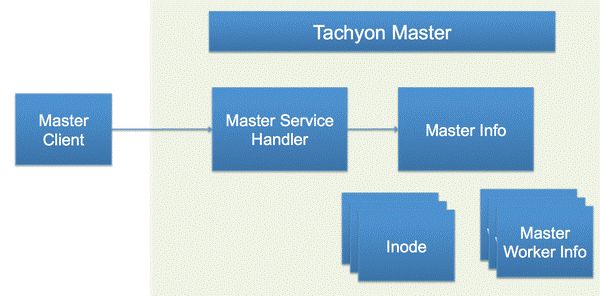
1.2.2 Tachyon Master结构
Tachyon Master的结构其主要功能如下:首先,Tachyon Master是个主管理器,处理从各个Client发出的请求,这一系列的工作由Service Handler来完成。这些请求包括:获取Worker的信息,读取File的Block信息, 创建File等等;其次,Tachyon Master是个Name Node,存放着所有文件的信息,每个文件的信息都被封装成一个Inode,每个Inode都记录着属于这个文件的所有Block信息。在Tachyon中,Block是文件系统存储的最小单位,假设每个Block是256MB,如果有一个文件的大小是1GB,那么这个文件会被切为4个Block。每个Block可能存在多个副本,被存储在多个Tachyon Worker中,因此Master里面也必须记录每个Block被存储的Worker地址;第三,Tachyon Master同时管理着所有的Worker,Worker会定时向Master发送心跳通知本次活跃状态以及剩余存储空间。Master是通过Master Worker Info去记录每个Worker的上次心跳时间,已使用的内存空间,以及总存储空间等信息。
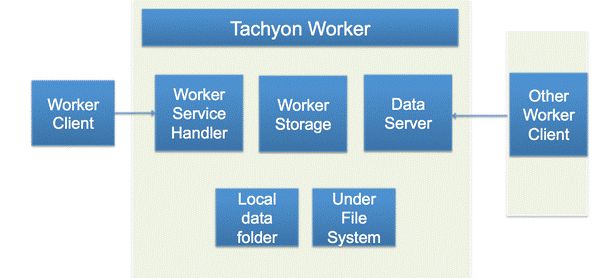
1.2.3 Tachyon Worker结构
Tachyon Worker主要负责存储管理:首先,Tachyon Worker的Service Handler处理来自Client发来的请求,这些请求包括:读取某个Block的信息,缓存某个Block,锁住某个Block,向本地内存存储要求空间等等。第二,Tachyon Worker的主要部件是Worker Storage,其作用是管理Local Data(本地的内存文件系统)以及Under File System(Tachyon以下的磁盘文件系统,比如HDFS)。第三,Tachyon Worker还有个Data Server以便处理其他的Client对其发起的数据读写请求。当由请求达到时,Tachyon会先在本地的内存存储找数据,如果没有找到则会尝试去其他的Tachyon Worker的内存存储中进行查找。如果数据完全不在Tachyon里,则需要通过Under File System的接口去磁盘文件系统(HDFS)中读取。
1.2.4 Tachyon Client结构
Tachyon Client主要功能是向用户抽象一个文件系统接口以屏蔽掉底层实现细节。首先,Tachyon Client会通过Master Client部件跟Tachyon Master交互,比如可以向Tachyon Master查询某个文件的某个Block在哪里。Tachyon Client也会通过Worker Client部件跟Tachyon Worker交互, 比如向某个Tachyon Worker请求存储空间。在Tachyon Client实现中最主要的是Tachyon File这个部件。在Tachyon File下实现了Block Out Stream,其主要用于写本地内存文件;实现了Block In Stream主要负责读内存文件。在Block In Stream内包含了两个不同的实现:Local Block In Stream主要是用来读本地的内存文件,而Remote Block In Stream主要是读非本地的内存文件。请注意,非本地可以是在其它的Tachyon Worker的内存文件里,也可以是在Under File System的文件里。
1.2.5 场景说明
现在我们通过一个简单的场景把各个部件都串起来:假设一个Spark作业发起了一个读请求,它首先会通过Tachyon Client去Tachyon Master查询所需要的Block所在的位置。如果所在的Block不在本地的Tachyon Worker里,此Client则会通过Remote Block In Stream向别的Tachyon Worker发出读请求,同时在Block读入的过程中,Client也会通过Block Out Stream把Block写入到本地的内存存储里,这样就可以保证下次同样的请求可以由本机完成。
1.3 HDFS与Tachyon
HDFS(Hadoop Distributed File System)是一个分布式文件系统。HDFS具有高容错性(fault-tolerant)特点,并且设计用来部署在低廉的硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了POSIX的要求,这样可以实现以流的形式访问(streaming access)文件系统中的数据。
HDFS采用Master/Slave架构。HDFS集群是由一个Namenode和一定数目的Datanode组成的。Namenode是一台中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录,它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求,在Namenode的统一调度下对数据块进行创建、删除和复制。
HDFS架构示意图如下图所示。
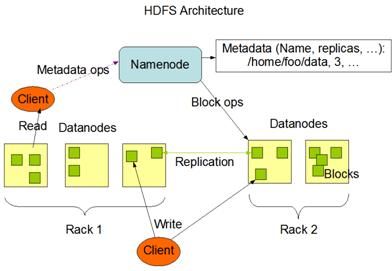
Namenode和Datanode被设计成可以在普通的商用机器上运行,这些机器一般运行着GNU/Linux操作系统。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个Namenode实例,而集群中的其他机器则分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样用户数据永远不会流过Namenode。
对比HDFS和Tachyon,首先从两者的存储结构来看,HDFS设计为用来存储海量文件的分布式系统,Tachyon设计为用来缓存常用数据的分布式内存文件系统。从这点来看,Tachyon可以认为是操作系统层面上的Cache,HDFS可以认为是磁盘。
在可靠性方面,HDFS采用副本技术来保证出现系统宕机等意外情况时文件访问的一致性以及可靠性;而Tachyon是依赖于底层文件系统的可靠性来实现自身文件的可靠性的。由于相对于磁盘资源来说,内存是非常宝贵的,所以Tachyon通过在其underfs(一般使用HDFS)上写入CheckPoint日志信息来实现对文件系统的可恢复性。
从文件的读取以及写入方式来看,Tachyon可以更好地利用本地模式来读取文件信息,当文件读取客户端和文件所在的Worker位于一台机器上时,客户端会直接绕过Worker直接读取对应的物理文件,减少了本机的数据交互。而HDFS在遇到这样的情况时,会通过本地Socket进行数据交换,这也会有一定的系统资源开销。在写入文件时,HDFS只能写入磁盘,而Tachyon却提供了5种数据写入模式用以满足不同需求。
2 Tachyon编译部署
Tachyon目前的最新发布版为0.7.1,其官方网址为http://tachyon-project.org/。Tachyon文件系统有3种部署方式:单机模式、集群模式和高可用集群模式,集群模式相比于高可用集群模式区别在于多Master节点。下面将介绍单机和集群环境下去安装、配置和使用Tachyon。
2.1 编译Tachyon
2.1.1 下载并上传源代码
第一步 下载到Tachyon源代码:
对于已经发布的版本可以直接从github下载Tachyon编译好的安装包并解压,由于Tachyon与Spark版本有对应关系,另外该系列搭建环境为Spark1.1.0,对应下载Tachyon0.5.0,版本对应参考http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html描述:

下载地址为https://github.com/amplab/tachyon/releases ,为以下演示我们在这里下载的是tachyon-0.5.0.tar.gz源代码包,文件大小为831K,如下图所示:
第二步 在主节点上解压缩
$cd /home/hadoop/upload/
$tar -xzf tachyon-0.5.0.tar.gz第三步 把tachyon-0.5.0.tar.gz改名并移动到/app/complied目录下
$mv tachyon-0.5.0 /app/complied/tachyon-0.5.0-src
$ll /app/complied
2.1.2 编译代码
为了更好地契合用户的本地环境,如Java版本、Hadoop版本或其他一些软件包的版本,可以下载Tachyon源码自行编译。Tachyon开源在GitHub上,可以很方便地获得其不同版本的源码。Tachyon项目采用Maven进行管理,因此可以采用 mvn package 命令进行编译打包。编译Tachyon源代码的时候,需要从网上下载依赖包,所以整个编译过程机器必须保证在联网状态。编译执行如下脚本:
$cd /app/complied/tachyon-0.5.0-src
$export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
$mvn clean package -Djava.version=1.7 -Dhadoop.version=2.2.0 -DskipTests
整个编译过程编译了约3个任务,整个过程耗时大约4分钟。
使用如下命令查看编译后该Tachyon项目大小为72M
$cd /app/complied/tachyon-0.5.0-src
$du -s /app/complied/tachyon-0.5.0-src
完成这一步后,我们就得到了能够运行在用户本地环境的Tachyon,下面我们分别介绍如何在单机和分布式环境下配置和启动Tachyon,在进行部署之前先把编译好的文件复制到/app/hadoop下并把文件夹命名为Tachyon-0.5.0:
$cd /app/complied
$cp -r tachyon-0.5.0-src /app/hadoop/tachyon-0.5.0
$ll /app/hadoop
2.2 单机部署Tachyon
这里要注意一点,Tachyon在单机(local)模式下启动时会自动挂载RamFS,所以请保证使用的账户具有sudo权限。
【注】编译好的Tachyon将本系列附属资源/install中提供,具体名称为10.tachyon-0.5.0-hadoop2.2.0-complied.zip
2.2.1 配置Tachyon
Tachyon相关配置文件在$TACHYON_HOME/conf目录下,在workers文件中配置需要启动TachyonWorker的节点,默认是localhost,所以在单机模式下不用更改(在Tachyon-0.5.0版本中,该文件为slaves)。在这里需要修改tachyon-env.sh配置文件,具体操作是将tachyon-env.sh.template复制为tachyon-env.sh:
$cd /app/hadoop/tachyon-0.5.0/conf
$cp tachyon-env.sh.template tachyon-env.sh
$ll
$vi tachyon-env.sh
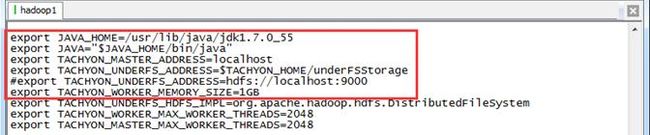
并在tachyon-env.sh中修改具体配置,下面列举了一些重要的配置项:
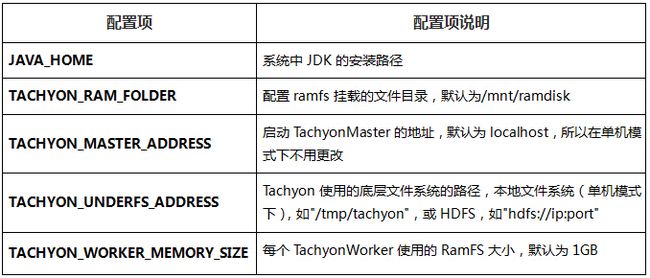
- JAVA_HOME:系统中java的安装路径
- TACHYON_MASTER_ADDRESS:启动TachyonMaster的地址,默认为localhost,所以在单机模式下不用更改
- TACHYON_UNDERFS_ADDRESS:Tachyon使用的底层文件系统的路径,在单机模式下可以直接使用本地文件系统,如”/tmp/tachyon”,也可以使用HDFS,如”hdfs://ip:port”
- TACHYON_WORKER_MEMORY_SIZE:每个TachyonWorker使用的RamFS大小
2.2.2 格式化Tachyon
完成配置后即可以单机模式启动Tachyon,启动前需要格式化存储文件,格式化和启动Tachyon的命令分别为:
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon format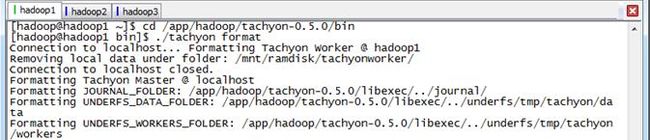
存储文件为$TACHYON_HOME/underfs/tmp/tachyon目录下
2.2.3 启动Tachyon
使用如下命令启动Tachyon,可以看到在/nmt/ramdisk目录下格式化RamFS
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon-start.sh local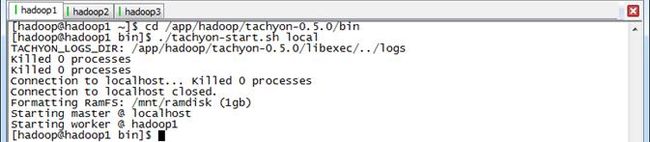
2.2.4 验证启动
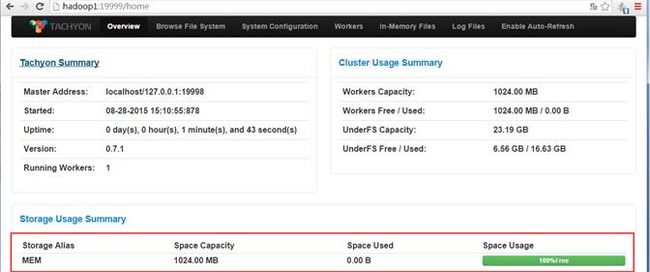
使用JPS命令查看Tachyon进程,分别为:TachyonWorker和TachyonMaster

查看Tachyon监控页面,访问地址为http://hadoop1:19999
2.2.5 停止Tachyon
停止Tachyon的命令为:
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon-stop.sh 
2.3 集群模式部署Tachyon
2.3.1 集群环境
集群包含三个节点(该集群环境可以参考第二课《2.Spark编译与部署(上)–基础环境搭建》进行搭建),运行进程分布如下:
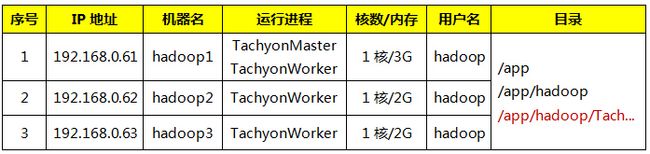
2.3.2 配置conf/worker
Tachyon相关配置文件在$TACHYON_HOME/conf目录下,对slaves文件中配置需要启动TachyonWorker的节点,在这里需要设置hadoop1、hadoop2和hadoop3三个节点:
$cd /app/hadoop/tachyon-0.5.0/conf
$vi slaves 
2.3.3 配置conf/tachyon-env.sh
在$TACHYON_HOME/conf目录下,将tachyon-env.sh.template复制为tachyon-env.sh,并在achyon-env.sh中修改具体配置。不同于单机模式,这里需要修改TachyonMaster地址以及底层文件系统路径:
$cd /app/hadoop/tachyon-0.5.0/conf
$cp tachyon-env.sh.template tachyon-env.sh
$vi tachyon-env.sh在该文件中修改一下两个参数,这里使用底层文件系统为HDFS:
export TACHYON_MASTER_ADDRESS=hadoop1
export TACHYON_UNDERFS_ADDRESS=hdfs://hadoop1:9000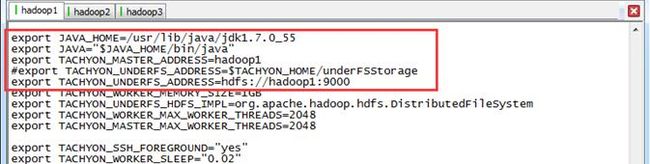
2.3.4 向各个节点分发Tachyon
使用如下命令把hadoop文件夹复制到hadoop2和hadoop3机器
$cd /app/hadoop/
$scp -r tachyon-0.5.0 hadoop@hadoop2:/app/hadoop/
$scp -r tachyon-0.5.0 hadoop@hadoop3:/app/hadoop/
2.3.5 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-dfs.sh
2.3.6 格式化Tachyon
启动前需要格式化存储文件,格式化命令为:
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon format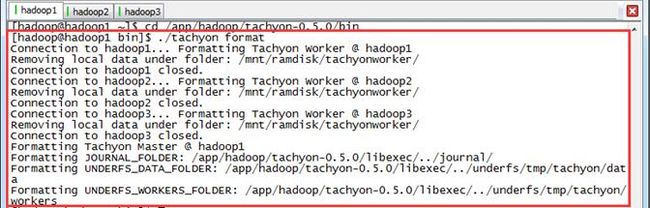
可以看到在HDFS的/tmp创建了tachyon文件夹
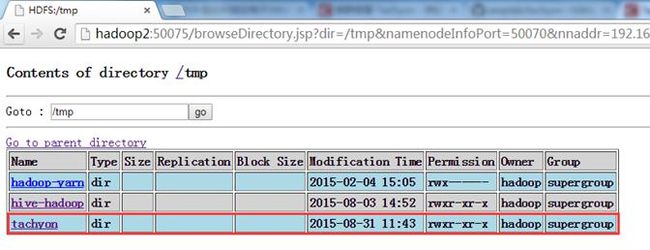
2.3.7 启动Tachyon
在这里使用SudoMout参数,需要在启动过程中输入hadoop的密码,具体过程如下:
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon-start.sh all SudoMount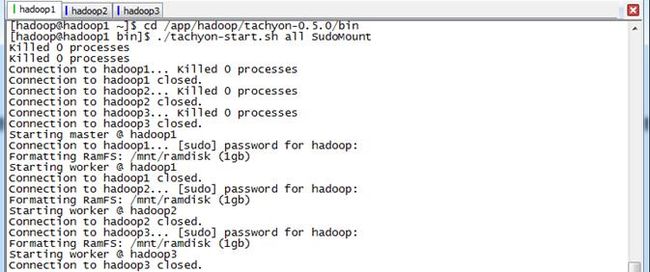
启动Tachyon有了更多的选项:
- ./tachyon-start.sh all Mount 在启动前自动挂载TachyonWorker所使用的RamFS,然后启动TachyonMaster和所有TachyonWorker。由于直接使用mount命令,所以需要用户为root;
- ./tachyon-start.sh all SudoMount在启动前自动挂载TachyonWorker所使用的RamFS,然后启动TachyonMaster和所有TachyonWorker。由于使用sudo mount命令,所以需要用户有sudo权限;
- ./tachyon-start.sh all NoMount 认为RamFS已经挂载好,不执行挂载操作,只启动TachyonMaster和所有TachyonWorker
因此,如果不想每次启动Tachyon都挂载一次RamFS,可以先使用命令./tachyon-mount.sh Mount workers 或./tachyon-mount.sh SudoMount workers 挂载好所有RamFS,然后使用./tachyon-start.sh all NoMount 命令启动Tachyon。
单机和集群式模式的区别就在于节点配置和启动步骤,事实上,也可以在集群模式下只设置一个TachyonWorker,此时就成为伪分布模式。
2.3.8 验证启动
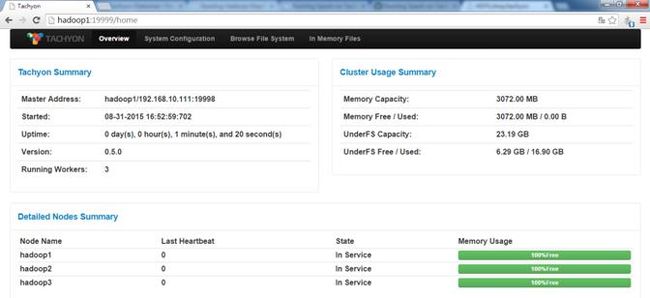
使用JPS命令查看Tachyon进程,分别为:TachyonWorker和TachyonMaster

可以在浏览器内打开Tachyon的WebUI,如 http://hadoop1:19999,查看整个Tachyon的状态,各个TachyonWorker的运行情况、各项配置信息和浏览文件系统等。
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon runTests2.4 Tachyon的配置
这里以0.5.0版本为例,介绍Tachyon中可配置参数的具体含义。Tachyon中的可配置项分为两类,一种是系统环境变量,用于在不同脚本间共享配置信息;另一种是程序运行参数,通过-D选项传入运行Tachyon的JVM中。程序运行参数又分为:
- 通用配置(Common Configuration)
- TachyonMaster配置(Master Configuration)
- TachyonWorker配置(Worker Configuration)
- 用户配置(User Configuration)
要修改或添加这些可配置项,可修改conf/tachyon-env.sh文件。
2.4.1 Tachyon环境变量
2.4.2 Tachyon通用配置
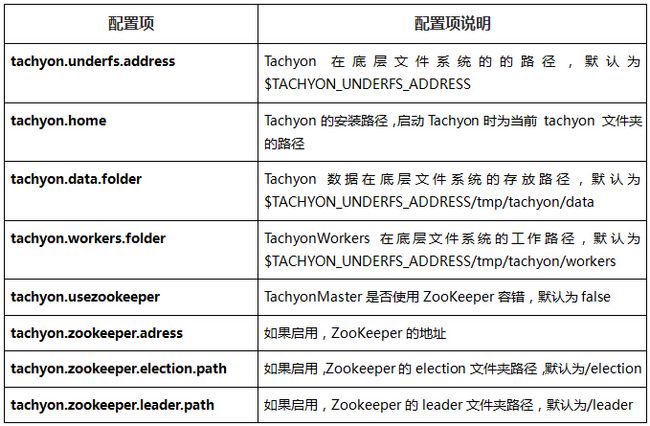
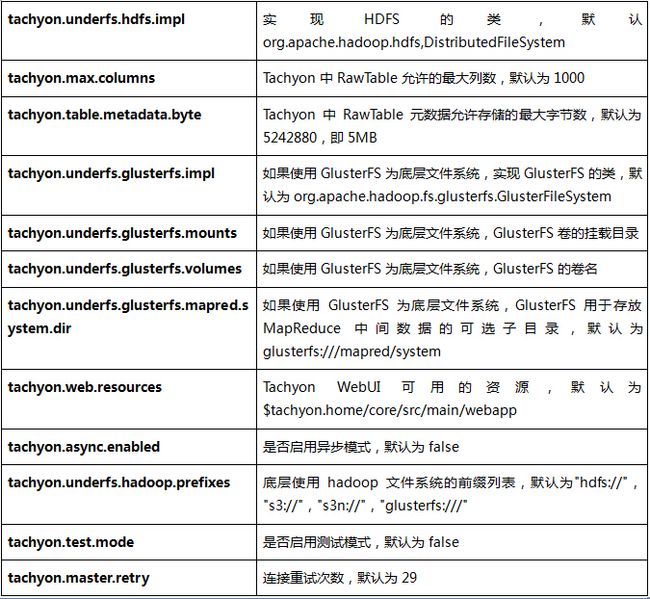
2.4.3 TachyonMaster配置
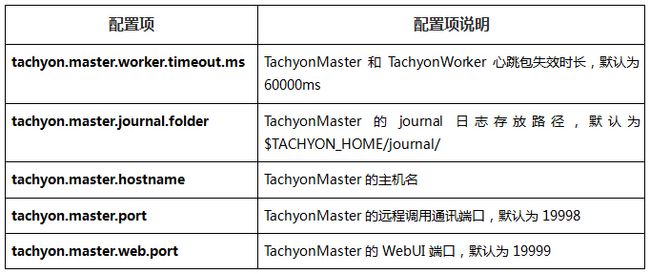

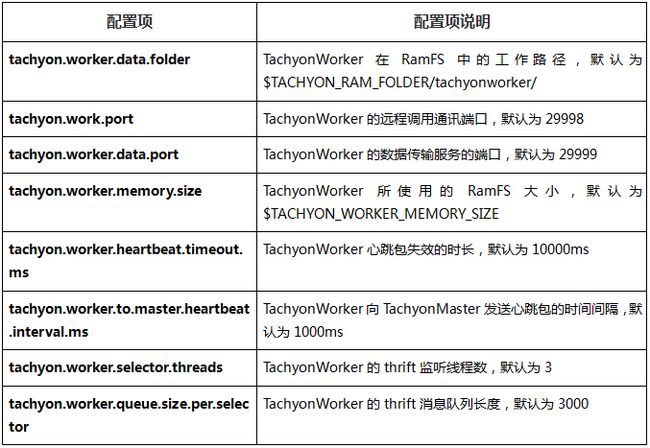
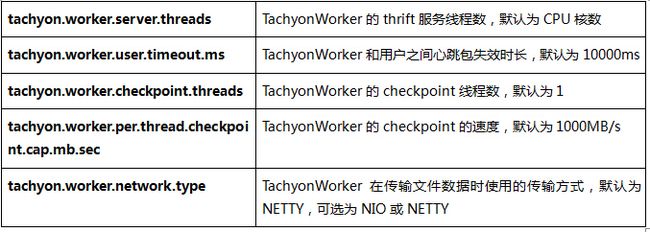
2.4.4 TachyonWorker配置
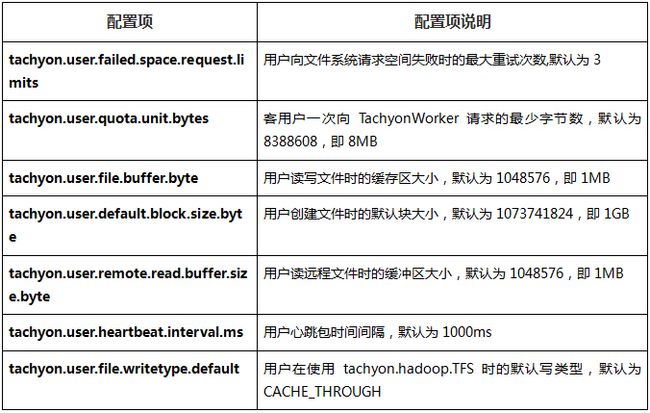
2.4.5 用户配置
3 Tachyon命令行使用
Tachyon的命令行界面让用户可以对文件系统进行基本的操作。调用命令行工具使用以下脚本:
$./tachyon tfs文件系统访问的路径格式如下:
tachyon://<master node address>:<master node port>/<path>在Tachyon命令行使用中tachyon://:前缀可以省略,该信息从配置文件中读取。
3.1 接口说明
可以通过如下命令查看Tachyon所有接口命令
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon tfs -help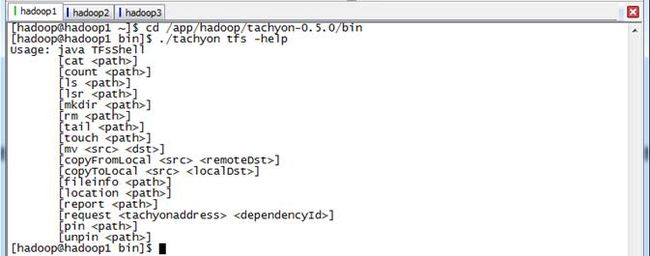
其中大部分的命令含义可以参考Linux下同名命令,命令含义:
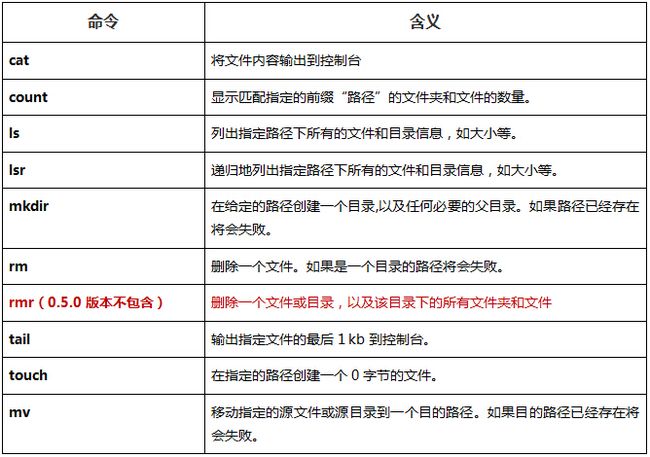
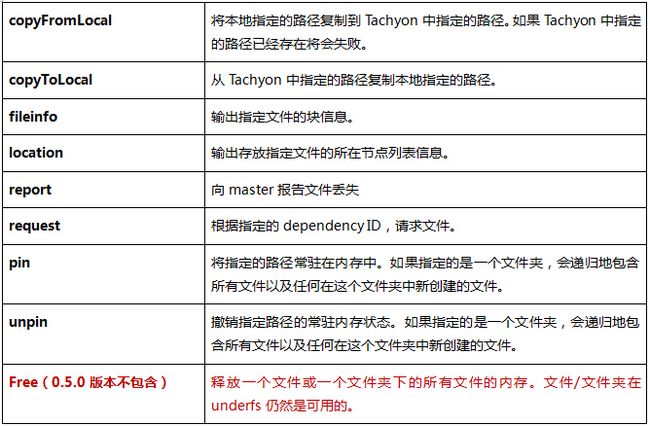
3.2 接口操作示例
在操作之前需要把$TACHYON_HOME/bin配置到/etc/profile 配置文件的PATH中,并通过source /etc/profile生效

3.2.1 copyFromLocal
将本地$TACHYON_HOME/conf目录拷贝到Tachyon文件系统的根目录下的conf子目录
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon tfs copyFromLocal ../conf /conf
$./tachyon tfs ls /conf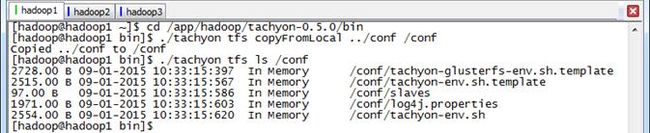
3.2.2 copyToLocal
把Tachyon文件系统文件复制到本地,需要注意的是命令中的src必须是Tachyon文件系统中的文件不支持目录拷贝,否则报错无法复制
$mkdir -p /home/hadoop/upload/class10/conflocal
$./tachyon tfs copyToLocal /conf /home/hadoop/upload/class10/conflocal
$./tachyon tfs copyToLocal /conf/tachyon-env.sh /home/hadoop/upload/class10/conflocal/tachyon-env.sh
$ll /home/hadoop/upload/class10/conflocal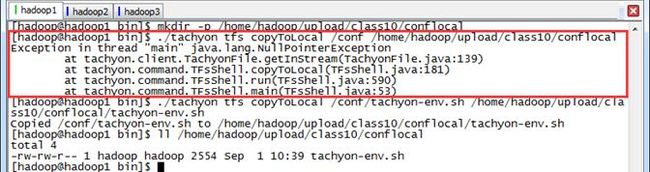
3.2.3 ls和lsr
使用ls和lsr命令查看Tachyon文件系统下的文件信息,其中lsr命令可以递归地查看子目录。
$./tachyon tfs ls /conf
$./tachyon tfs ls tachyon://hadoop1:19998/conf
$./tachyon tfs lsr /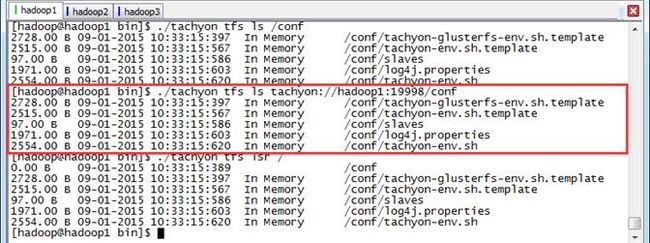
3.2.4 count
统计当前路径下的目录、文件信息,包括文件数、目录树以及总的大小
$./tachyon tfs count /
3.2.5 cat
查看指定文件的内容
$./tachyon tfs cat /conf/slaves
$./tachyon tfs cat tachyon://hadoop1:19998/conf/slaves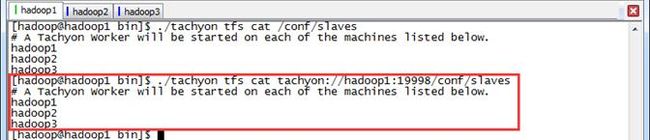
3.2.6 mkdir、rm、rmr和touch
(1) mkdir:创建目录,支持自动创建不存在的父目录;
(2) rm:删除文件,不能删除目录,注意,递归删除根目录是无效的
(3) rmr:删除目录,支持递归,包含子目录和文件,其中0.5.0版本不提供该命令
(4) touch:创建文件,不能创建已经存在的文件。
$./tachyon tfs mkdir /mydir
$./tachyon tfs ls /
$./tachyon tfs rm /mydir
$./tachyon tfs touch /mydir/my.txt
$./tachyon tfs lsr /mydir
$./tachyon tfs rm /mydir/my.txt
$./tachyon tfs touch /mydir2/2/2/my.txt
$./tachyon tfs lsr /mydir2
$./tachyon tfs rm /mydir2
$./tachyon tfs rm /
$./tachyon tfs ls /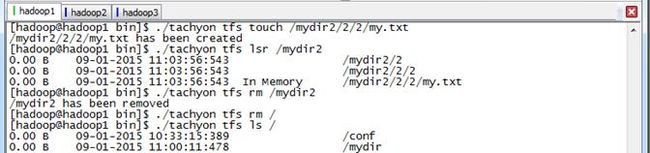
3.2.7 pin和unpin
pin命令将指定的路径常驻在内存中,如果指定的是一个文件夹会递归地包含所有文件以及任何在这个文件夹中新创建的文件。unpin命令撤销指定路径的常驻内存状态。

pin执行前或unpin执行后的Web Interface界面
$./tachyon tfs pin /conf/log4j.properties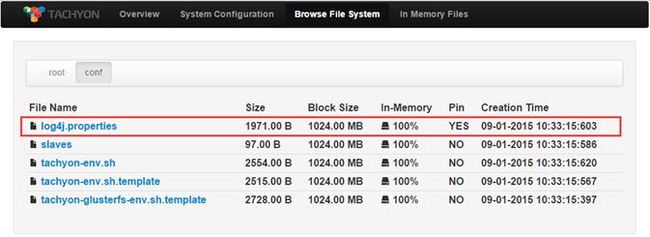
$./tachyon tfs unpin /conf/log4j.properties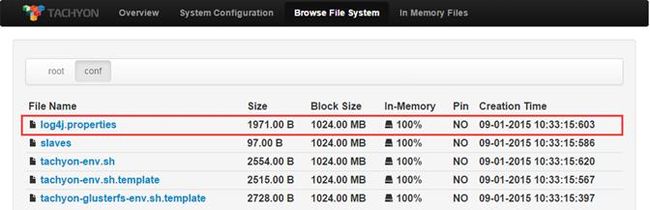
4 Tachyon实战应用
4.1 配置及启动环境
4.1.1 修改spark-env.sh
修改$SPARK_HOME/conf目录下spark-env.sh文件:
$cd /app/hadoop/spark-1.1.0/conf
$vi spark-env.sh在该配置文件中添加如下内容:
export SPARK_CLASSPATH=/app/hadoop/tachyon-0.5.0/client/target/tachyon-client-0.5.0-jar-with-dependencies.jar:$SPARK_CLASSPATH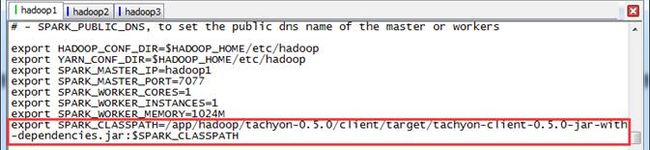
4.1.2 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-dfs.sh4.1.3 启动Tachyon
在这里使用SudoMout参数,需要在启动过程中输入hadoop的密码,具体过程如下:
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon-start.sh all SudoMount4.2 Tachyon上运行Spark
4.2.1 添加core-site.xml
在Tachyon的官方文档说Hadoop1.X集群需要添加该配置文件(参见http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html),实际在Hadoop2.2.0集群测试的过程中发现也需要添加如下配置文件,否则无法识别以tachyon://开头的文件系统,具体操作是在$SPARK_HOME/conf目录下创建core-site.xml文件
$cd /app/hadoop/spark-1.1.0/conf
$touch core-site.xml
$vi core-site.xml在该配置文件中添加如下内容:
<configuration>
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
</configuration>
4.2.2 启动Spark集群
$cd /app/hadoop/spark-1.1.0/sbin
$./start-all.sh4.2.3 读取文件并保存
第一步 准备测试数据文件
使用Tachyon命令行准备测试数据文件
$cd /app/hadoop/tachyon-0.5.0/bin
$./tachyon tfs copyFromLocal ../conf/tachyon-env.sh /tachyon-env.sh
$./tachyon tfs ls /
第二步 启动Spark-Shell
$cd /app/hadoop/spark-1.1.0/bin
$./spark-shell第三步 对测试数据文件进行计数并另存
对前面放入到Tachyon文件系统的文件进行计数
scala>val s = sc.textFile("tachyon://hadoop1:19998/tachyon-env.sh")
scala>s.count()

把前面的测试文件另存为tachyon-env-bak.sh文件
scala>s.saveAsTextFile("tachyon://hadoop1:19998/tachyon-env-bak.sh")
第四步 在Tachyon的UI界面查看
可以查看到该文件在Tachyon文件系统中保存成tahyon-env-bak.sh文件夹
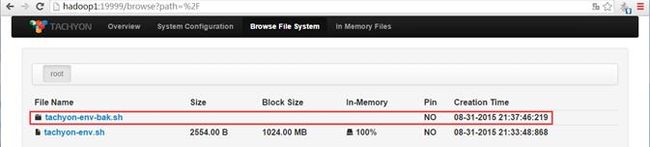
该文件夹中包含两个文件,分别为part-00000和part-00001:

其中tahyon-env-bak.sh/part-0001文件中内容如下:

另外通过内存存在文件的监控页面可以观测到,这几个操作文件在内存中:
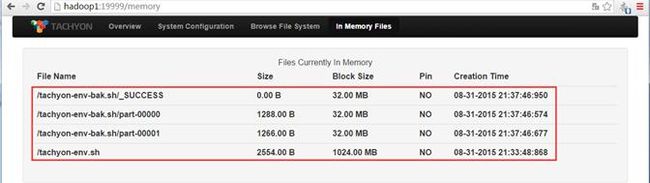
4.3 Tachyon运行MapReduce
4.3.1 修改core-site.xml
该配置文件为$Hadoop_HOME/conf目录下的core-site.xml文件
$cd /app/hadoop/hadoop-2.2.0/etc/hadoop
$vi core-site.xml修改core-site.xml文件配置,添加如下配置项:
<property>
<name>fs.tachyon.impl</name>
<value>tachyon.hadoop.TFS</value>
</property>
<property>
<name>fs.tachyon-ft.impl</name>
<value>tachyon.hadoop.TFSFT</value>
</property>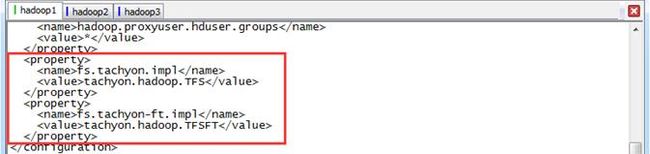
4.3.2 启动YARN
$cd /app/hadoop/hadoop-2.2.0/sbin
$./start-yarn.sh4.3.3 运行MapReduce例子
第一步 创建结果保存目录
$cd /app/hadoop/hadoop-2.2.0/bin
$./hadoop fs -mkdir /class10第二步 运行MapReduce例子
$cd /app/hadoop/hadoop-2.2.0/bin
$./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount -libjars $TACHYON_HOME/client/target/tachyon-client-0.5.0-jar-with-dependencies.jar tachyon://hadoop1:19998/tachyon-env.sh hdfs://hadoop1:9000/class10/output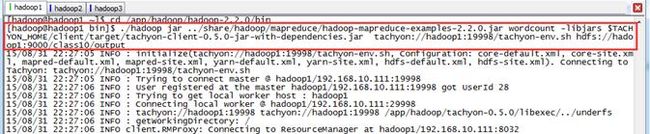
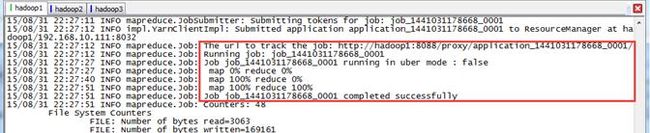
第三步 查看结果
查看HDFS,可以看到在/class10中创建了output目录
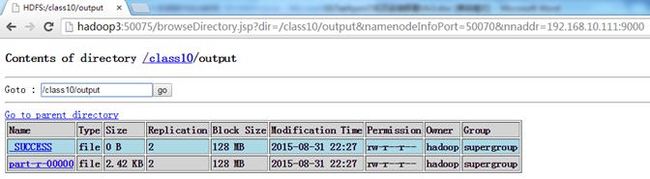
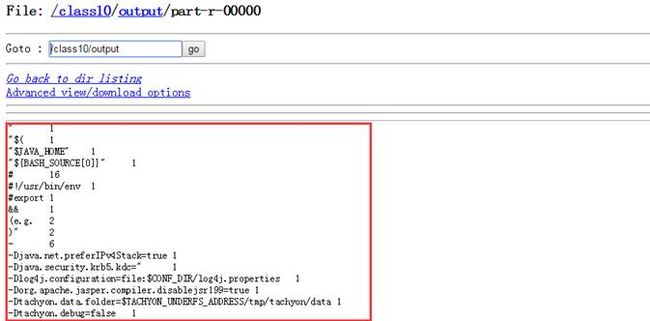
查看part-r-0000文件内容,为tachyon-env.sh单词计数
5 参考资料
(1) 《Tachyon:Spark生态系统中的分布式内存文件系统》 http://www.csdn.net/article/2015-06-25/2825056
(2) 《Tachyon的安装、配置和使用》 http://blog.csdn.net/u014252240/article/details/42238081
(3) Tachyon官方网站http://tachyon-project.org/documentation/Running-Spark-on-Tachyon.html