SAX解析器
SAX解析器解析XML文档是基于事件驱动的。他将XML文档转化为一系列的事件,然后由事件处理器来决定如何处理。这种模式主要是基于事件源和事件处理器的。能产生事件的对象是事件源,对事件做出响应处理的对象被叫做事件处理器。
而事件处理器则是org.xml.sax包中的ContentHandler、DTDHandler、ErrorHandler,以及EntityResolver这四个接口。他们分别处理事件源在解析过程中产生不同类的事件(其中DTDHandler为解析文档DTD时所用)。
详细介绍如下表:
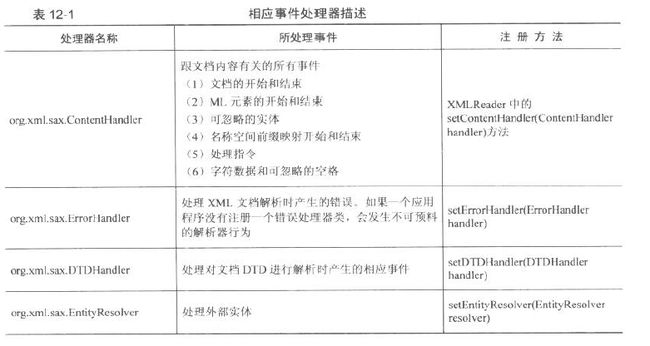
以上事件处理器中,ContentHandler相对重要。
在Android中使用SAX解析的步骤如下:
第一步:新建一个工厂类SAXParserFactory,
SAXParserFactory factory = SAXParserFactory.newInstance();
第二步:让工厂类产生一个SAX的解析类SAXParser
SAXParser parser = factory.newSAXParser();
第三步:从SAXPsrser中得到一个XMLReader实例
XMLReader reader = parser.getXMLReader();
第四步:把自己写的handler注册到XMLReader中,一般最重要的就是ContentHandler,代码如下:
MySAXHandler handler = new MySAXHandler();
reader.setContentHandler(handler);
第五步:解析正式开始
reader.parse(is);
其中XMLReader 对象使用如下方法:
/注册处理XML文档解析事件ContentHandler public void setContentHandler(ContentHandler handler) //开始解析一个XML文档 public void parse(InputSorce input) throws SAXException
MySAXHandler是需要我们自己实现的ContentHandler.一般实现ContentHandler需要以下一些步骤:
1、声明一个类,继承DefaultHandler。DefaultHandler是一个基类,这个类里面简单实现了一个ContentHandler。我们只需要重写里面的方法即可。
2、重写 startDocument() 和 endDocument(),一般解析将正式解析之前的一些初始化工资放到startDocument()里面,收尾的工作放到endDocument()里面。
3、重写startElement(),XML解析器遇到XML里面的tag时就会调用这个函数。经常在这个函数内是通过localName俩进行判断而操作一些数据。
4、重写characters()方法,这是一个回调方法。解析器执行完startElement()后,解析完节点的内容后就会执行这个方法,并且参数ch[]就是节点的内容。
5、重写endElement()方法,这个方法与startElement()相对应,解析完一个tag节点后,执行这个方法。
package com.liupan.parse;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
//DefaultHandler是一个基类,这个类里面简单实现了一个ContentHandler。我们只需要重写里面的方法即可。
public class MyHandler extends DefaultHandler{
//一般将正式解析前的一些初始化工作放到这里面,收尾工作放在endDocument中
@Override
public void startDocument() throws SAXException {
// TODO Auto-generated method stub
super.startDocument();
}
@Override
public void endDocument() throws SAXException {
// TODO Auto-generated method stub
super.endDocument();
}
// XML解析器遇到XML里面的tag时就会调用这个函数。经常在这个函数内是通过localName俩进行判断而操作一些数据。
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
// TODO Auto-generated method stub
/*
* attributes Element节点的属性
*/
super.startElement(uri, localName, qName, attributes);
}
//回调方法。解析器执行完startElement()后,解析完节点的内容后就会执行这个方法,并且参数ch[]就是节点的内容。
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
// TODO Auto-generated method stub
String text = new String(ch, start, length);//取到Text节点内容
super.characters(ch, start, length);
}
// 这个方法与startElement()相对应,解析完一个tag节点后,执行这个方法。
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// TODO Auto-generated method stub
super.endElement(uri, localName, qName);
}
}
解析的时候会顺序触发相应的事件,其中的Element和Element之间的空格换行等都会触发characters函数,所以一般限定在
<introduction> 北胶莱河,长100余公里 </introduction>这种时(通过一些布尔值来限制,或者一些整形的常量值
final int RSS_TITLE = 1; final int RSS_LINK = 2; final int RSS_DESCRIPTION = 3; final int RSS_CATEGORY = 4; final int RSS_PUBDATE = 5;),才是有效的。取到的值调用String 的trim()方法去掉左边和右边的空格