二叉树
0)首先回顾一些树的基本概念:
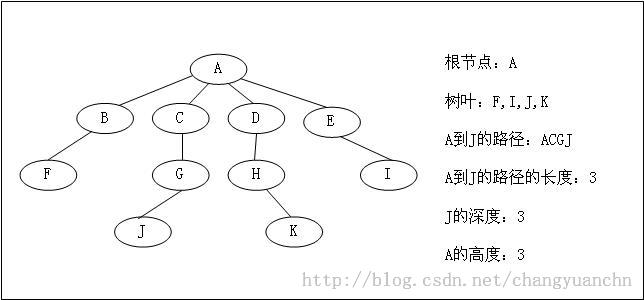
根节点(root):没有父亲的结点。
树叶(leaf):没有儿子的结点。
路径(path):是一个结点到另一个结点的序列表示,这些结点都应该是父子关系。
路径的长(length): 路径上边的条数。为序列个数减一。
深度(depth):根结点到某一结点的唯一路径的长。
高(height):某一结点到树叶的最长路径的长。
如图所示:
树的遍历:
前序遍历(preorder traversal):先根节点,然后左子树,最后右子树。
中序遍历(inorder traversal):先遍历左子树,然后根节点,最后右子树。
后序遍历(postorder traversal):先左子树,然后右子树,最后根节点。
分类是根据根节点的遍历顺序分的。
下图是遍历的例子:
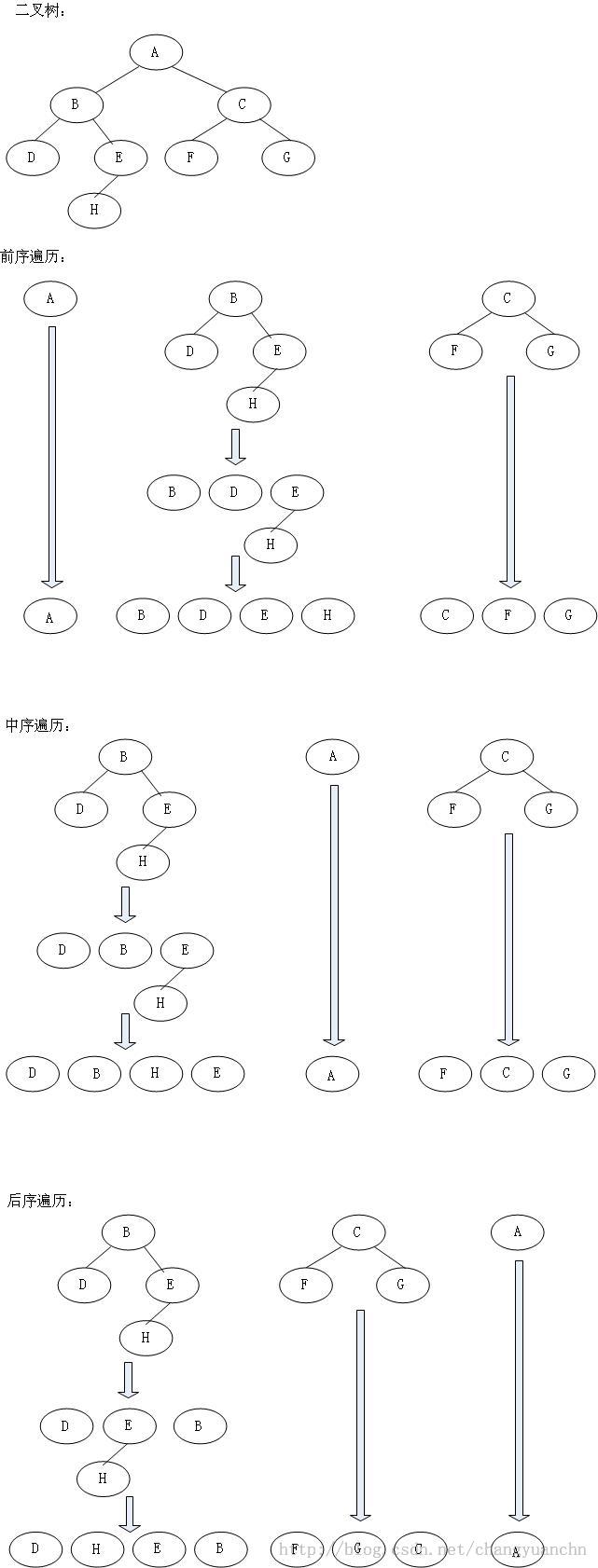
1) 二叉树
二叉树是一种树,其子节点的数目不超过2个。上图就是一个二叉树。
二叉树中应用最多的当属二叉查找树,原因是二叉查找树的查找时间复杂度相当的低,平均只有O(logN),效率基本相当于二分查找。而链表的时间复杂度为O(logN).
2)二叉查找树的实现
二叉树的实现是递归调用的经典范例。
二叉查找树的性质是:左子树<根节点<右子树。也就是说二叉查找树的数据分布一定是满足这一性质的。
二叉树的定义:
struct TreeNode;
typedef struct TreeNode *Position;
typedef struct TreeNode *SearchTree;
typedef int ElementType;
struct TreeNode
{
ElementType Element;
SearchTree Left;
SearchTree Right;
}; 设置空树:
SearchTree MakeEmpty(SearchTree T)
{
if(T!=NULL)
{
MakeEmpty(T->Left);
MakeEMpty(T->Right);
free(T);
}
return NULL;
} 二叉树查找:
Position Find(ElementType X, SearchTree T)
{
if(T==NULL)
return NULL;
if(X<T->Element)
return Find(X,T->Left);
else if(X>T->Element)
return Find(X,T->Right);
else
return T;
} 查找最大值以及最小值:
因为二叉查找树是按排好序存储的,因此查找最大最小值非常方便简单,最大最小值分别为最左的叶子和最右的叶子。也就是说如果最小值不是根节点的话,那必然在左子树长;同理,最大值的情况,不在根节点就是在右子树上。
Position FindMax(SearchTree T)
{
if(T==NULL)
return NULL;
else if(T->Left==NULL)
return T;
else
return FindMax(T->Left);
}
Position FindMin(SearchTree T)
{
if(T != NULL)
while(T->Right!=NULL)
T = T->Right;
return T;
} 在这里要注意的是:在应用
T = T->Right;的时候要格外小心,这里很容易引起错误。在这个子程序中不存在错误的问题。
插入结点:
插入结点比较简单,首先查找有没有这个结点,如果有的话,do nothing,没有的话,找到相应的叶子位置,把这个结点插上。
SearchTree Insert(ElementType X, SearchTree T)
{
if(T==NULL)
{
T = malloc(sizeof(struct TreeNode));
if(T==NULL)
Error("Out of Space!!!");
else
{
T->Element = X;
T->Left =T->Right = NULL;
}
}
else
if(X<T->Element)
T->Left = Insert(X,T->Left);
else
if(X>T->Element)
T->Right = Insert(X,T->Right);
return T;
} 关于Insert函数的返回值,T指向的是新生成的树的根节点。其实针对Insert函数来说,不需要返回值.
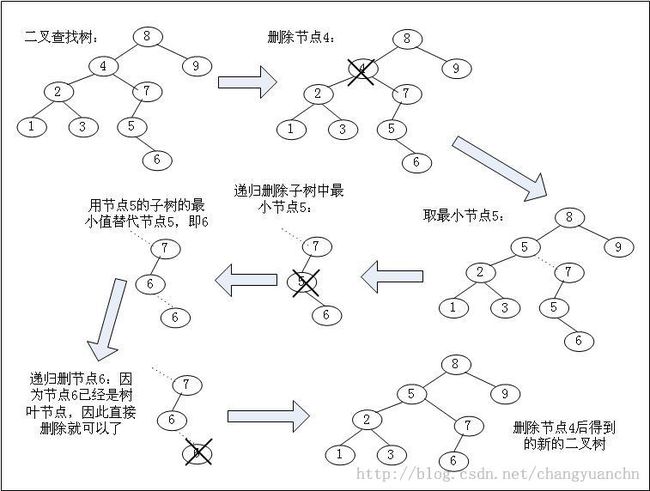
删除节点:
删除节点是一个比较麻烦的问题,如果是叶节点,那么直接删除就可以了,如果是非叶结点就麻烦了,因为把非叶结点删除了以后,还要考虑这个结点的子节点的排列问题。
如图所示
SearchTree Delete(ElementType X, SearchTree T)
{
if(T==NULL)
Error("Element not Found!");
else
if(X<T->Element)
T->Left = Delete(X,T->left);
else
if(X>T->Element)
T->Right = Delete(X,T->Right);
else //found the element
if(T->Left && T->Right) //two children
{
Position Tmp;
Tmp = FindMin(T->Right);
T->Element = Tmp->Element;
T->Right = Delete(T->Element,T->Right);
free(Tmp);
}
else //leaf or one child
{
Position Tmp;
if(T->Left==NULL)
Tmp = T->Right;
else if(T->Right==NULL)
Tmp = T->Left;
T = Tmp;
free(Tmp);
}
return T;
}
值得注意的是:当以上述的方式进行若干次的删除操作时,可能会使树不再平衡,左子树会非常健壮,右子树会萎缩,也就会使二叉树的查找的时间复杂度要高于O(logN).