Linkers and Loaders 01
Chapter 01:链接和装载
给出链接过程的历史,讨论链接的步骤,最后给出一个“Hello World”程序的完整的链接过程。
链接器和装载器是做什么的?
任何链接器和装载器的基本工作都很简单:把抽象的名字绑定到具体的实名上,使程序员能写出更有抽象意义的代码。也就是说,它把程序员写的例如“getline”绑定成“iosys模块中的可执行代码起始地址偏移612字节的地址”。甚至可以采用更抽象的寻址方式,例如把“在本模块静态数据区起始地址前450字节的地址”,绑定到一个数值地址上。
地址绑定:历史回顾
最早的计算机用机器语言进行编程。程序员把带符号的程序写在纸上,手工汇编成机器码,输入到计算机里,或制作到磁带或卡里。虽然程序中符号只要直接转换成相应地址,就像程序员手工转换过程一样,但是如果需要加入或删除一条指令,那么整个程序中所有被影响到的地址都要手工调整。
问题就是过早的把名字绑定到了地址。汇编程序解决了这个问题,允许程序员编写符号化程序,由汇编程序最后把名字绑定成机器代码。如果程序修改了,程序员需要重新汇编一次,但是调整地址的工作从程序员转移到了计算机上。
库代码也有同样问题。由于计算机能执行的基本操作很简单,有用的程序一般都由许多子程序组合而成,以执行更高级和复杂的操作。计算机里保存有已经写好并调试过的子程序,程序员能利用它们写出新程序,只要装载子程序就行了。
甚至在汇编程序之前,程序员就开始使用子程序库了。1947年,领导ENIAC工程的John Mauchly写过一个装载程序,可以选择并装载位于磁带上的子程序,并根据需要重定位子程序的代码。可能令人惊讶,链接器的两大功能——重定位和库搜索,甚至比汇编程序还要出现的早,虽然他们都是用机器语言写成的。重定位装载器允许程序员先写好子程序,并假定它们从内存地址0开始运行,把实际的地址绑定延迟到子程序被链接成主程序的时候。
随着操作系统的出现,重定位装载器从链接器里分离出来,库也变得必要。以前一个程序可以支配计算机的整个内存,所以可以用确定的内存地址汇编和链接程序。但是现在,一个程序必须和操作系统或其他程序共享计算机的内存,于是程序开始运行的真实地址直到操作系统把程序装载到内存中后才会知道,地址绑定的时间推迟到了装载的时候。链接器和装载器现在分工合作,链接器完成部分地址绑定,为程序设置相对地址,由装载器设置最终的实际地址。
当系统变得越来越复杂,链接器需要完成越来越复杂的名字管理和地址绑定工作。Fortran程序使用多重子程序(multiple subprograms),公共块(common blocks)和数据共享区(areas of data shared),并且依靠链接器来为子程序和公共块分配存储空间和设置地址。于是链接器必须处理的目标代码库包括Fortran或其他语言写的应用程序库,以及编译器支持的库,后者由编译器内部调用来处理I/O和其他高级的操作。
程序迅速变得比可用的内存更大了,于是链接器提供了重叠(overlays)技术,使程序的不同部分共享同一块内存,在被调用时才装载入内存。在1960年左右,重叠技术被大量应用到配备磁盘的大型机里,直到70年代虚拟内存(virtual memory)技术的普及。随后又在80年代初被应用到微型机,直到虚拟内存又出现在个人电脑里时才慢慢退出。现在它在内存受限的嵌入式环境里仍被应用,并且可能在其他一些需要程序精确控制内存或编译器控制内存的地方会起作用。
随着硬件重定位(hardware relocation)和虚拟内存的出现,链接器和装载器实际上变简单了,因为每个程序再次拥有了整个地址空间。程序可以用确定的地址进行链接和装载,让硬件来处理装载期的重定位,而非软件重定位。但是计算机总是运行不止一个程序,或者是一个程序的几个副本。当计算机运行了一个程序的多个实例,这些程序的某些部分可能全部都是相同的(特别是代码段部分),其他部分则互不相同。如果这些不变的部分能和可变的部分分离开来,操作系统就只需要一份不变部分的副本,于是省下可观的存储空间。编译器和汇编器于是被修改,把目标代码创建到多个部分(sections)里,其中有一个只读部分和其他可写部分。链接器必须能把不同类的部分组合起来连成整个程序,且使所有的代码在一个地方,而所有的数据在另一个地方。这并没有比以前更延迟地址绑定的时间,因为地址仍是在链接的时候指定的,但是使其他的工作延迟到了链接期来设定相对地址。
即使计算机运行不同的程序,也会共享许多的公共代码。比如,几乎每个C语言程序都使用fopen和printf函数,所有数据库应用程序都使用高效访问的库来连接数据库,而在GUI(用户图形界面)下运行的程序如X Windows,MS Windows,或Macintosh,都使用了GUI库的一部分。大部分系统现在提供共享库(shared libraries),使所有使用它的程序能共享单个副本。这样既能提高运行时性能,又能节省磁盘空间。在一些小程序中,公共库代码经常比它们本身代码占用更多空间。
在一种简单的静态共享库(static shared libraries)情况下,每个库被建立时就绑定到明确的地址,链接器绑定程序中的引用(program references)到库函数的地址。静态库渐渐变得不方便和不灵活,因为每次库修改后程序在都需要重新链接,并且创建静态共享库的细节变得越来越麻烦。于是系统加入了动态链接库(dynamically linked libraries),让库的分段部分(sections)和符号(symbols)直到程序开始运行时才绑定到真实地址。有时候绑定工作甚至更延后,例如成熟的动态绑定过程中,函数例程的地址直到第一次调用时才被绑定。
此外,现在即使程序运行过程中也能进行库的绑定和装载,这使程序功能的扩展性大大增加。例如微软Windows就广泛的应用运行时装载共享库技术(例如DLL,动态链接库)来建立和扩展程序。
链接和装载
链接器和装载器的工作既相关又有区别:
* 程序装载
把程序从存储设备(从1968年以后基本表示磁盘)复制到主存中运行。在一些情况下装载只是从磁盘到内存复制数据,但另一些情况下却要分配空间,设置保护位(
protection bits),或调整虚拟内存使虚拟地址映射到磁盘分页文件。
* 重定位
编译器和汇编器一般假定程序从地址0开始运行来创建目标代码文件,但是很少有计算机允许程序装载到地址0的。如果一个程序是由许多子程序建立起来的,所有的子程序都要被装载到不重叠的地址里。重定位过程就是给程序的不同部分设定装载地址,并调整相应的代码和数据。在许多系统里,重定位不止进行一次。一种普遍的情况是链接器利用多个子程序最后生成一个目标程序,整体假定从地址0开始运行,但是其中的那些子程序就必须重定位到适当的相对地址,使整个程序运行正确。然后当整个程序被装载,系统选择了实际地址,那么整个链接好的程序就被重定位到装载地址。
* 符号解析
当一个程序从多个子程序建立时,某个子程序利用符号来引用另一个子程序里的代码;主程序可能用符号“sqrt”来调用一个求平方根的函数,而某个数学库里对sqrt进行了定义。链接器为了解析这个符号,先记录数学库中sqrt的相对地址,然后加上调用者目标代码的相对地址,最后得到整个指令的调用地址。
虽然链接和装载之间有许多重复的地方,但还是应该用不同的程序来完成工作。它们每个都可以进行重定位,并且也有集这3个功能于一体的链接装载器(
linking loaders
)。
重定位和符号解析之间的界限也很模糊。既然链接器能解析符号引用,那么就可以用符号表示程序每个部分的基址(
base address),然后把可重定位地址(
relocatable addresses)当作这些基址符号的再次引用。
链接器和装载器的另一个重要共同点是能处理目标代码,此外只有调试器有这个能力。这是一个很强大的功能,和机器硬件细节有很大联系,如果出错将导致莫名其妙的漏洞。
2次遍历链接
现在我们看看链接器的一般结构。与编译和汇编一样,链接是一个典型的2次遍历过程。链接器的输入包括目标文件,库,或命令文件。输出最终的目标文件,和附加的信息例如
load map
,或包含调试符号的文件,如下图所示:
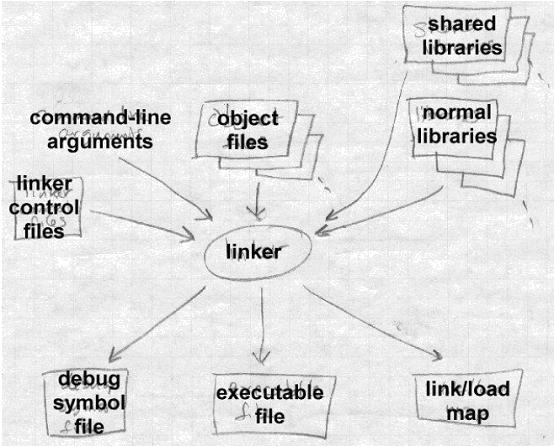
每个输入文件都包含一些段(
segments
),即可以放入输出文件的整块连续的代码或数据。每个输入文件还包含至少一个符号表(
symbol table
)。有些符号还会导出到别的文件,一般是函数符号,方便别的文件调用。其他符号则需要导入,即本文件没有定义,而调用别处的函数。
链接器运行时,首先扫描输入文件,得到各个段的大小,搜集所有符号的定义和引用。然后创建一个段列表(
segment table
)列出所有的段,和一个符号表包含所有导入或导出的符号。
利用第
1
次遍历得到的数据,链接器可以给符号设置数值地址,决定各个段在输出地址空间的大小和位置,以及输出文件的其他细节。
第
2
次遍历利用先前得到的信息控制链接过程。它读取并重定位目标代码,用数值地址代替符号引用,调整代码和数据中的内存地址适应重定位后的段地址,然后把重定位后的代码写到输出文件。接着给输出文件加上头信息(
header information
),重定位段,和符号表信息。如果程序使用动态链接,符号表里还包含了必要信息供运行时链接器(
runtime linker
)解析动态符号。很多情况下,链接器自己会产生少量的代码或数据,例如“胶合代码(
glue code
)”来调用重叠区或动态链接库内的函数,或一个指针数组来初始化程序启动时要调用的函数。
无论程序是否使用动态链接,输出文件都包含符号表,供重新链接或调试时使用。
有些目标格式可以重新链接,即从一个链接器输出的文件可以作为其他链接器的输入。这就要求输出文件和输入文件一样包含一个符号表,以及其他的一些辅助信息
几乎所有的目标格式都为调试符号作了准备,所以当程序在调试器的控制下运行时,程序员可以利用源程序里的符号控制程序的运行状态。根据目标格式的细节不同,调试符号和链接器需要的符号可能混合在一个符号表里,或者有一个链接符号表,和另一个独立的调试符号表。
很少的链接器只用
1
次遍历,通过把部分或全部输入文件读入缓冲区来实现。但这只能算是一个实现技巧,而不影响到链接过程的
2
次遍历本质,我们也不作过多讨论。
目标代码库
所有的链接器都支持某种形式的目标代码库,大部分还支持多种形式的共享库。
目标代码库的基本原理很简单,如下图所示。
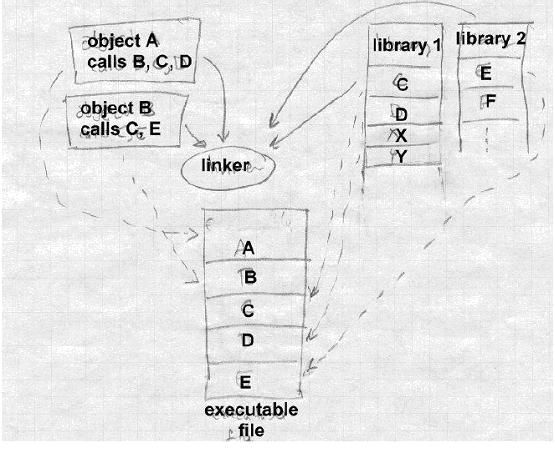
一个库无非就是一堆目标文件,在某些系统里甚至可以把目标文件简单拼接到一起形成一个链接库。当链接器处理完所有合法的输入文件后,如果还有某些导入的名字未定义,它就遍历当前的所有库,找到任何定义了这些名字的文件或库,然后链接它们。
共享库让工作稍微复杂了一点,把一些事从链接时期移到了装载时期。链接器先识别出共享库里的未定义名字,但是不链接共享库,而是在输出文件里记录下哪个库里有哪个名字,最后在程序装载的时候进行绑定。后续第
9
和
10
章有更多细节。
重定位和代码修正
链接器和装载器的核心工作就是重定位和代码修正。当编译器或汇编器生成目标文件时,它不知道代码和数据的重定位地址,而且把其他地方定义的代码或数据地址假定成
0
。而链接过程的一部分就是链接器根据真实的地址修正目标代码。比如,下面这段
x86
下的汇编代码,利用
eax
寄存器把变量
a
的内容移到变量
b
里。
mov a,%eax
mov %eax,b
如果
a
在同一个文件里有定义,且位于
0x1234
处,
b
是一个导入符号,那么产生的目标代码将是:
A1 34 12 00 00 mov a,%eax
A3 00 00 00 00 mov %eax,b
每条指令包含
1
字节的操作码(
A1
和
A3
)和
4
字节的地址。第一条指令有一个到
0x1234
的引用(字节倒序,因为
x86
采用从右到左的字节顺序),第二条指令引用为
0
,因为
b
的地址还是未知。
现在假设链接器要链接这段代码,并把
a
所在的部分重定位到
0x10000
字节的位置,而
b
最终解析为
0x9A12
。于是链接器修正代码为:
A1 34 12 01 00 mov a,%eax
A3 12 9A 00 00 mov %eax,b
即链接器先给第一条指令的引用地址加上
0x10000
,于是
a
的重定位地址变成了
0x11234
,然后修正
b
的地址。目标文件中数据部分的所有指针都需要进行调整。
在老式的小地址空间和直接寻址的计算机里,修正工作非常简单,因为只有一到二种地址格式。现代计算机和所有的
RISC
计算机,要求相当复杂的代码修正工作。一条指令的空间还不够存储直接地址,所以编译器和链接器都使用复杂的寻址技巧处理任意地址的数据。在一些情况下,可以用
2
到
3
条指令合成一个地址,每条指令包含地址的一部分,然后用位操作
(
bit manipulation
)组合成整个地址。这时链接器需要对每条指令进行适当的修改,插入一些地址位。另一些情况下,程序中所有的地址都放在称为“地址池(
address pool
)”的数组里,初始化代码让某个寄存器指向数组,然后代码把该寄存器当成基址寄存器来访问“地址池”指向的数据。链接程序可能要创建数组来存储程序里用到的所有地址,然后修正指令使它们表示正确的地址池入口。详见第
7
章。
有些系统要求位置独立(
position independent
)的代码,即装载到任何地址空间都能正确运行。链接器就需要使用额外的技巧,把位置独立的程序部分分离开来,并安排与其余部分的通信与协调。详见第
8
章。
编译器驱动
在大多数情况下,链接器的操作对程序员是不可见的,因为它们自动作为编译过程的一部分。许多编码系统有一个编译器驱动(
compiler driver
)自动根据编译器状态调用相应操作。比如,一个程序有
2
个
C
语言源文件,一个
Unix
系统下的编译器将运行这样一系列的程序:
*
C
预处理器处理
A
文件,创建
A
的预处理文件
*
C
编译器处理
A
的预处理文件,创建
A
的汇编文件
*
汇编器处理
A
的汇编文件,创建
A
的目标文件
*
C
预处理器处理
B
文件,创建
B
的预处理文件
*
C
编译器处理
B
的预处理文件,创建
B
的汇编文件
*
汇编器处理
B
的汇编文件,创建
B
的目标文件
*
链接器处理
A
和
B
的目标文件,以及
C
语言系统库
即把每个源文件编译成汇编语言和目标文件,然后链接到一起,加上所需的
C
语言系统库。
实际的编译器驱动往往比这还聪明。它们比较源文件和目标文件的创建日期,只重新编译改过的源文件(
Unix
系统的
make
程序就是一个典型的例子)。特别是编译
C++
和其他面向对象语言的时候,编译器驱动想尽办法来弥补链接器或目标格式的不足。例如,
C++
的函数模版能潜在的定义无穷的相关函数,为了找到一段代码实际调用的函数形式,编译器驱动先去掉模版定义,把程序目标文件链接到一起,通过错误信息判断哪些东西没有定义,然后让编译器从函数模版代码中产生必要的目标代码并重新链接。在第
11
章里还有一些技巧的介绍。
链接器命令语言
每个链接器都有一些命令语言来控制链接过程。至少链接器需要目标文件和库的一个列表来进行链接,这样就有了很多的选择可能:是否保留调试符号,是否使用共享或不共享的库,选择哪一种输出格式。大部分链接器允许指定链接代码被绑定的地址,这在链接一个操作系统内核或其他不在操作系统下运行的程序很有用。对于一个支持多代码段和多数据段的链接器,命令语言可以指定段的链接顺序,特殊段的特殊处理,和其他应用上的选项。
下面有4种常用的命令方式:
* 命令行
大部分系统支持命令行参数,可以传递文件名和选项。这也是Unix和Windows的常用方式。在一些限制命令行长度的系统里,可以想办法从文件读取命令参数,就像从命令行读取一样。
* 混合到目标文件
某些链接器,例如IBM大型机链接器,接受一个包含了目标文件和命令选项的输入文件。这起源于使用纸带程序的时期,那时人们把包含目标代码的纸带和手工打孔的命令选项卡插入到读卡器里。
* 嵌入到目标文件里
微软的目标格式允许命令选项内嵌到目标文件里。这样就使编译器传给链接器的文件里记录了自己该怎样被处理。
* 独立的配置语言
少数几个链接器有单独完整的配置语言。GNU链接器可以处理大部分的目标文件格式,计算机体系结构和地址空间规则,也有一套复杂的控制语言使程序员可以指定各个段链接的顺序,及其他众多的选项。其他链接器的命令语言相对简单,比如处理程序员定义的重叠属性。
链接:一个实际的例子
我们以一个实际的例子来结束对链接的讨论。下面有2个C语言源文件,m.c包含一个主程序,调用函数a,而a.c包含一个函数,调用库函数strlen和
write。
————————————————————————————————————
Source file m.c
extern void a(char *);
int main(int ac, char **av)
{
static char string[] = "Hello, world!/n";
a(string);
}
Source file a.c
#include <unistd.h>
#include <string.h>
void a(char *s)
{
write(1, s, strlen(s));
}
————————————————————————————————————
主程序m.c在作者的机器上,用GCC编译成一个165字节的目标文件a.out,内容如下面的表所示,包括固定的文件头,16字节的“text”只读程序段,和16字节的“data”数据段,接着是2个重定位入口,一个标记了pushl指令,表明此时把字符串的地址压入堆栈以备调用函数a,另一个入口标记了call指令,使控制器转移到a。符号表导出_main,导入_a,还包含其他调试符号(每个全局符号都加了“_”前缀,原因见第5章)。注意pushl指令引用了地址0x10,这只是暂时的字符串地址,毕竟它们在同一个文件里。而call指令则引用了地址0,因为当时_a是未知的。
文件a.out的内容:
————————————————————————————————————
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000010 00000000 00000000 00000020 2**3
1 .data 00000010 00000010 00000010 00000030 2**3
Disassembly of section .text:
00000000 <_main>:
0: 55 pushl %ebp
1: 89 e5 movl %esp,%ebp
3: 68 10 00 00 00 pushl $0x10
4: 32 .data
(这是一个重定位入口)
8: e8 f3 ff ff ff call 0
9: DISP32 _a
(这是另一个重定位入口)
d: c9 leave
e: c3 ret
...
————————————————————————————————————
子程序文件a.c编译成160字节的目标文件,如下面的表。包含文件头,28字节的代码段,没有数据段,2个重定位入口标记对strlen和write的调用,还有符号表导出_a并导入_strlen和_write。
————————————————————————————————————
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0000001c 00000000 00000000 00000020 2**2
CONTENTS, ALLOC, LOAD, RELOC, CODE
1 .data 00000000 0000001c 0000001c 0000003c 2**2
CONTENTS, ALLOC, LOAD, DATA
Disassembly of section .text:
00000000 <_a>:
0: 55 pushl %ebp
1: 89 e5 movl %esp,%ebp
3: 53 pushl %ebx
4: 8b 5d 08 movl 0x8(%ebp),%ebx
7: 53 pushl %ebx
8: e8 f3 ff ff ff call 0
9: DISP32 _strlen
(这是一个重定位入口)
d: 50 pushl %eax
e: 53 pushl %ebx
f: 6a 01 pushl $0x1
11: e8 ea ff ff ff call 0
12: DISP32 _write
(这是另一个重定位入口)
16: 8d 65 fc leal -4(%ebp),%esp
19: 5b popl %ebx
1a: c9 leave
1b: c3 ret
————————————————————————————————————
要生成一个可执行程序,链接器把这2个目标文件组装起来,并加上标准C程序的启动初始化,必要的C语言库函数,最后的可执行文件片断在下表显示:
————————————————————————————————————
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000fe0 00001020 00001020 00000020 2**3
1 .data 00001000 00002000 00002000 00001000 2**3
2 .bss 00000000 00003000 00003000 00000000 2**3
Disassembly of section .text:
00001020 <start-c>:
...
1092: e8 0d 00 00 00 call 10a4 <_main>
...
000010a
4 <_main>:
10a4: 55 pushl %ebp
10a5: 89 e5 movl %esp,%ebp
10a7: 68 24 20 00 00 pushl $0x2024
10ac: e8 03 00 00 00 call 10b4 <_a>
10b1: c9 leave
10b2: c3 ret
...
000010b4 <_a>:
10b4: 55 pushl %ebp
10b5: 89 e5 movl %esp,%ebp
10b7: 53 pushl %ebx
10b8: 8b 5d 08 movl 0x8(%ebp),%ebx
10bb: 53 pushl %ebx
10bc: e8 37 00 00 00 call 10f8 <_strlen>
10c1: 50 pushl %eax
10c2: 53 pushl %ebx
10c3: 6a 01 pushl $0x1
10c5: e8 a2 00 00 00 call 116c <_write>
10ca: 8d 65 fc leal -4(%ebp),%esp
10cd: 5b popl %ebx
10ce: c9 leave
10cf: c3 ret
...
000010f
8 <_strlen>:
...
0000116c
<_write>:
...
————————————————————————————————————
链接器把每个输入文件中相应的段组合起来,整体形成一个代码段,一个数据段和一个bss段(初始化为0的数据,本例中2个输入文件中未使用)。每个段都填充成4K对齐,以适应x86分页大小,所以代码段为4K(还要减去20字节的a.out文件头),数据段和bss段都是4K大小。
组合成的代码段包含库的启动代码,叫做start-c,m.o里的代码重定位到了0x10A4,a.o里的代码重定位到了0x10B4,而C语言库函数重定位到了代码段的更后面。数据段虽然没有显示出来,但组合方式是一样的。因为_main函数代码被重定位到了0x10A4,所以start-c里的call指令也被修改。而在_main函数内部,对字符串的引用变成了最终地址0x2024(前面是0x10),call指令也修改为_a的最终地址0x10B4(前面是0)。在_a内部,对_strlen和_write的调用都修改成了最终的函数地址(0x
10F
8
和
0x116C)。
可执行文件内还包含很多C语言库的其他函数,被直接或间接的调用,例如错误处理代码。但是没有重定位的数据,因为这个格式不是可重链接的,操作系统会把它装载到一个已知的地址内运行。它还包含一个符号表,仅用于调试,当然也可以去掉以节省空间。
在这个例子里,从库中链接的代码比程序本身要大得多。但这种情况很普遍,特别是使用大型图形库或绘制窗体库的程序,于是这也推进了共享库的发展,见第9和10章。这个程序最终有8K,但是同等的使用共享库的程序只有264字节,而实际的程序经常也能达到这么大的节省空间效果。
注:
我对书中的“Hello World”程序也进行了编译链接,得到的结果与书中有所不同,当然可能是GCC版本和环境不同造成的,不过也可以作为参考。
处理器:Intel Pentium® M 1.70GHz
环境:Red Hat Linux 3.2.2-5 with GCC version 3.2.2 20030222
由如下命令得到m.c的汇编代码m.asm:
gcc m.c –S –o m.asm
其完整内容如下:
————————————————————————————————————
.file "m.c"
.data
.type string.0,@object
.size string.0,15
string.0:
.string "Hello, world!/n"
.text
.globl main
.type main,@function
main:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
andl $-16, %esp
movl $0, %eax
subl %eax, %esp
subl $12, %esp
pushl $string.0
call a
addl $16, %esp
leave
ret
.Lfe1:
.size main,.Lfe1-main
.ident "GCC: (GNU) 3.2.2 20030222 (Red Hat Linux 3.2.2-5)"
————————————————————————————————————
然后可以用如下命令得到m.c的目标代码文件m.o:
gcc m.c –c –o m.o
得到的m.o文件实际有756字节大小,在UltraEdit-32下查看,其中代码段起始于0x00000034h位置:
————————————————————————————————————
0x00000034 <main>:
0: 55 pushl %ebp
1: 89 E5 movl %esp, %ebp
3: 83 EC 08 subl $8, %esp
6: 83 E4 F0 addl $16, %esp
9: B8 00 00 00 00 movl $0, %eax
E: 29 C4 subl %eax, %esp
10: 83 EC 0C subl $12, %esp
13: 68 00 00 00 00 pushl $string.0
18: E8 FC FF FF FF call a
1D: 83 C4 10 addl $16, %esp
20: C9 leave
21: C3 ret
...
————————————————————————————————————
同样可以用上面的命令得到a.c的汇编代码文件a.asm和目标文件a.o:
gcc a.c –S –o a.asm
gcc a.c –c –o a.o
其中a.asm文件的完整内容如下:
————————————————————————————————————
.file "a.c"
.text
.globl a
.type a,@function
a:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
subl $4, %esp
subl $8, %esp
pushl 8(%ebp)
call strlen
addl $12, %esp
pushl %eax
pushl 8(%ebp)
pushl $1
call write
addl $16, %esp
leave
ret
.Lfe1:
.size a,.Lfe1-a
.ident "GCC: (GNU) 3.2.2 20030222 (Red Hat Linux 3.2.2-5)"
————————————————————————————————————
而a.o文件大小为740字节,代码段也起始于0x00000034位置:
————————————————————————————————————
0x00000034 <a>:
0:
55 pushl %ebp
1: 89 E5 movl %esp, %ebp
3: 83 EC 08 subl $8, %esp
6: 83 EC 04 subl $4, %esp
9: 83 EC 08 subl $8, %esp
C: FF 75 08 pushl 8(%ebp)
F: E8 FC FF FF FF call strlen
14: 83 C4 0C addl $12, %esp
17: 50 pushl %eax
18: FF 75 08 pushl 8(%ebp)
1B: 6A 01 pushl $1
1F: E8 FC FF FF FF call write
22: 83 C4 10 addl $16, %esp
25: C9 leave
26: C3 ret
...
————————————————————————————————————
最后使用如下命令把m.o和a.o链接成整个可执行程序文件a.exe:
gcc m.o a.o –o a.exe
注意m.o和a.o的顺序,生成的a.exe大小为11,768字节,用UltraEdit-32找到main函数的代码段起始于0x0000035C,a函数的代码段起始于0x00000380:
————————————————————————————————————
0x0000035C <main>:
0: 55 pushl %ebp
1: 89 E5 movl %esp, %ebp
3: 83 EC 08 subl $8, %esp
6: 83 E4 F0 addl $16, %esp
9: B8 00 00 00 00 movl $0, %eax
E: 29 C4 subl %eax, %esp
10: 83 EC 0C subl $12, %esp
13: 68 64 94 04 08 pushl $string.0 (注意地址的变化)
18: E8 07 00 00 00 call a (注意地址的变化)
1D: 83 C4 10 addl $16, %esp
20: C9 leave
21: C3 ret
...
0x00000380 <a>:
0:
55 pushl %ebp
1: 89 E5 movl %esp, %ebp
3: 83 EC 08 subl $8, %esp
6: 83 EC 04 subl $4, %esp
9: 83 EC 08 subl $8, %esp
C: FF 75 08 pushl 8(%ebp)
F: E8 F8 FE FF FF call strlen (注意地址变化)
14: 83 C4 0C addl $12, %esp
17: 50 pushl %eax
18: FF 75 08 pushl 8(%ebp)
1B: 6A 01 pushl $1
1F: E8 DA FE FF FF call write (注意地址变化)
22: 83 C4 10 addl $16, %esp
25: C9 leave
26: C3 ret
...
————————————————————————————————————
至于程序运行的结果就是打印出“Hello World”,用如下的命令执行:
./a.exe
由于我对汇编语言和文件格式了解得也不是很深,所以不能推出strlen和write代码在文件中的偏移,甚至对上面的一些代码也是似懂非懂,错误之处在所难免,希望读者指正。