云算法调用平台--web 工程调用hadoop集群1.3
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit,struts2;
本篇介绍的是一个云算法调用平台,主要的作用是使用前台的参数配置,然后调用hadoop集群来跑mahout的算法程序。工程可以在web 工程调用hadoop集群1.3下载,工程下载后需要拷贝WEB-INF/lib/hadoop-fz1.3.jar到hadoop集群的lib下面。此版本只支持text2vector算法,其他算法后续版本给出。
先看下整体页面:
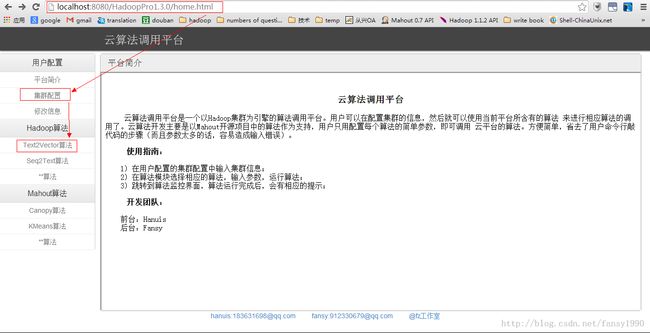
用户首先需要配置集群,集群配置完成后,可以调用算法了。
这里验证集群是否Running状态使用的是初始化JobClient的方法,如果使用配置的jobtracker和namenode初始化JobClient成功,那么就说明集群是可以使用的。这里前台页面提交到后台都是使用struts2拦截,然后使用action来接收处理的,首先看下struts2的配置:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.3//EN"
"http://struts.apache.org/dtds/struts-2.3.dtd">
<struts>
<!-- Add packages here -->
<constant name="struts.devMode" value="true" />
<constant name="struts.i18n.encoding" value="UTF-8" />
<package name="actions" extends="struts-default" namespace="/actions" >
<action name="hadoop_Setup" class="org.fz.algorithm.hadoop.action.SetupAction">
<result name="success">/hadoop/setup_success.html </result>
<result name="error">/hadoop/setup_error.html </result>
</action>
<action name="*_*" class="org.fz.algorithm.{1}.action.{2}Action">
<result name="success">/algorithm/running.jsp </result>
<result name="error">/algorithm/error.jsp </result>
</action>
</package>
</struts>
这里的setup单独配置了,涉及到算法调用的都使用通配符进行跳转;
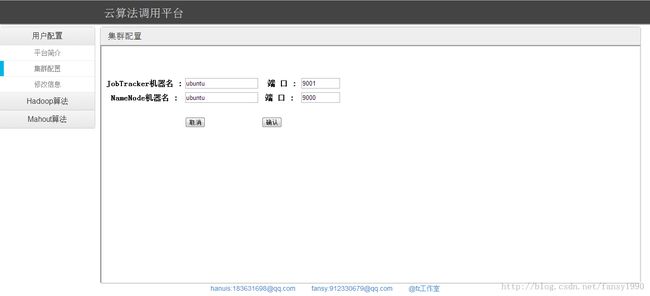
集群配置参数输入完成后,点击确认,表单提交到actions/hadoop_Setup ,这是一个action,在struct.xml中看到这个action对应的是org.fz.algorithm.hadoop.action.SetupAction,这里的处理就是利用前面的参数初始化JobClient来判断集群是否可用。这里的参数接收使用的是strut2的特有方式,表单里面输入框的命名也有要求,具体参考代码;
接着是hadoop算法的一个用例:
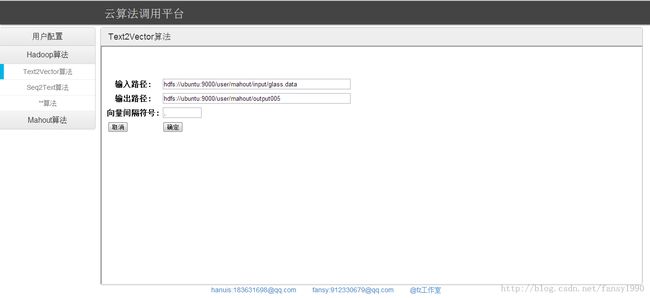
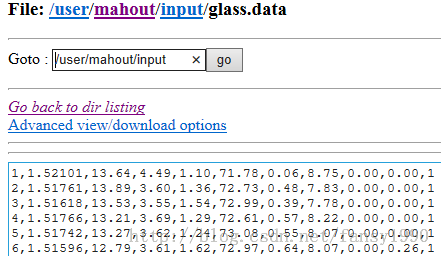
这个算法是把输入文本数据文件转换成序列向量文件的算法,需要参数有输入路径、输出路径、向量间隔符。比如下面的数据,数据间隔符就是逗号:
看这个表单提交的action是actions/hadoop_Text2vector,这个在strut.xml中没有直接的匹配,但是却有一个通配符匹配到,那么它实际的action就是:org.fz.algorithm.{1}.action.{2}Action,替换{1}、{2}得到org.fz.algorithm.hadoop.action.Text2vectorAction,这个action的代码如下:
package org.fz.algorithm.hadoop.action;
import org.fz.algorithm.hadoop.model.Text2vectorVo;
import org.fz.algorithm.hadoop.service.Text2vectorService;
import util.hadoop.HadoopUtil;
import com.opensymphony.xwork2.ActionSupport;
public class Text2vectorAction extends ActionSupport {
/**
*
*/
private static final long serialVersionUID = 1L;
private Text2vectorVo text2vectorVo;
/*
* do the text 2 vector transform
* use split
* @see com.opensymphony.xwork2.ActionSupport#execute()
*/
@Override
public String execute(){
if(!HadoopUtil.checkHaveSetHadoop()){// have not set hadoop cluster then return error;
return ERROR;
}
Text2vectorService t2v=new Text2vectorService(text2vectorVo);
// run job
new Thread(t2v,"text2vector job").start();
return SUCCESS;
}
public Text2vectorVo getText2vectorVo() {
return text2vectorVo;
}
public void setText2vectorVo(Text2vectorVo text2vectorVo) {
this.text2vectorVo = text2vectorVo;
}
}
这里算法调用都是采用新建thread的方法来做的,直接跳转到任务监控界面,但是点击下面方块中的内容不会刷新,可以考虑点击圆圈的内容:
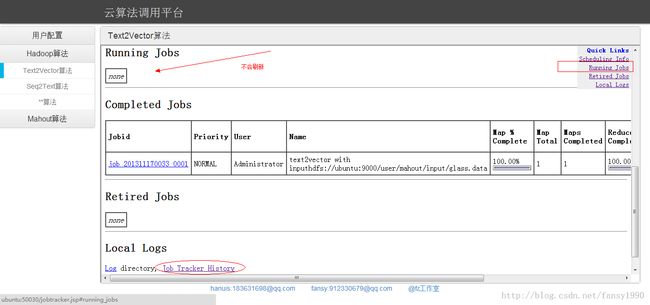
这里的点击确定,运行算法后,跳转到算法监控界面不是很合理,应该是自己写一个监控的,而不是直接调用原来的监控。这块暂时还没想好怎样监控。
后续版本会慢慢增加算法,同时页面会调整的相对美观点。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990