Oracle数据库索引
1 索引基本概念
索引是用于加速数据存取的数据对象,合理的使用索引可以大幅降低I/O次数,从而提高数据访问性能。
单列索引:在一个列上建立的索引,比如:
-- Oracle默认建立B-tree索引 create index 索引名 on 表名(列名)
复合索引:在两列或多列上建立的索引。在同一张表上可以有多个索引,但是这些索引所包含的列的组合必须不完全相同。如:
create index emp_idx1 on emp(ename, job); create index emp_idx2 on emp(job, ename);索引的使用原则:在大表上建立索引才有意义;在where子句(where子句中一般将熵值较大的字段放在后面,SQL语句的查询条件是从右向左)或连接条件上经常使用的列上建立索引;索引的层次不宜超过4层。
索引的缺点:建立索引,系统要占用大约为表的1.2倍的硬盘和内存空间来保存索引;更新数据时,必须同时对索引进行更新,以维持数据和索引的一致性。
因此,不恰当的索引反而会降低系统性能,因为在数据插入、修改和删除时需要额外的时间更新索引。例如,如在如下字段建立索引一般是不恰当的:很少或从不引用的字段;逻辑型字段,如男或女(是或否)等。总之,建立索引提高查询效率是以消耗一定的系统资源(额外的存储和增删改操作额外的索引更新时间)为代价的,DBA需要慎重考虑在哪些字段上建立索引,以及建立哪种索引。
2 索引的作用
支持快速查询
对于存储大量数据的数据库,线性查找效率很低,索引技术使数据库支持次线性时间查找以提高查询性能。索引是所有提高查询性能的数据结构。目前已经有许多数据结构可用于提高查询速度,事实上计算机科学领域的研究有很大一部分工作是对索引数据结构的研究和分析。索引数据结构的研究需要考虑查询性能、索引大小和索引更新性能等方面的折中。许多索引提供对数时间复杂度(O(logn(N)))的查找性能,某些情况下甚至可以获得O(1)时间复杂度。
实现数据库约束
索引也可以用于实现数据库的约束,如UNIQUE,EXCLUSION,PRIMARY KEY和FOREIGN KEY。UNIQUE索引约束其所引用的列,该列的值唯一。数据库系统通常会默认在PRIMARY KEY(主键)的列上创建索引。
3 索引的架构
在Sybase中,分为clustered indexes(聚集索引)和nonclustered indexes(非聚集索引)。聚集索引是一种特殊的索引,它把表中的记录的物理存储重新排序。因此,每张表只能有一个聚集索引。聚集索引的叶节点包含数据页。
非聚集索引中,索引的逻辑顺序与物理存储顺序不同。非聚集索引的叶节点中不包含数据页,而是包含索引行。
Oracle中并不存在这两种索引。仅从技术上讲,Oracle的IOT(index organized table)可以实现clustered indexes的作用,但是通常不推荐这么做。
Oracle提供了称为cluster的结构,但与上述两种索引并无关系。cluster是一种将多个表存到同一个block中的方法。正常情况下,一个block包含1个表的数据。在一个cluster中,多个表的数据共享同一个block。
4 Oracle索引的类型
按照数据存储方式,分为B-树索引、反向索引、位图索引,B-树索引建立在重复值很少的列上,位图索引建立在重复值很多、不同值相对固定的列上。
按照索引列的个数,分为单列索引、复合索引;
按照索引列值的唯一性,分为唯一索引、非唯一索引。
此外还有函数索引、全局索引、分区索引等。
Oracle数据库提供以下类型的索引:
- B-tree索引(Oracle默认建立B-tree索引)
- B-tree聚集索引(B-tree cluster indexes)
- Hash聚集索引(Hash cluster indexes)
- 反向索引(Reverse key indexes)
- 位图索引(Bitmap indexes)
- 位图连接索引(Bitmap join indexes)
Oracle也支持基于函数的索引和某个应用的域索引(domain indexes)。
4.1 基于函数的索引
基于函数的索引SQL语句如下:
-- 基本结构 CREATE [UNIQUE] INDEX index_name ON table_name (function1, function2, . function_n) [ COMPUTE STATISTICS ]; -- 例子 CREATE INDEX supplier_idx ON supplier (UPPER(supplier_name));COMPUTE STATISTICS表示是否收集索引的统计信息。
4.2 位图索引
目前大量使用的索引一般主要是B-Tree索引,在索引结构中存储着键值和键值的RowID,并且是一一对应的。而位图索引主要针对大量相同值的列而创建,例如:类别,操作员,部门ID等。位图索引由于只存储键值的起止Rowid和位图,占用的空间非常少。
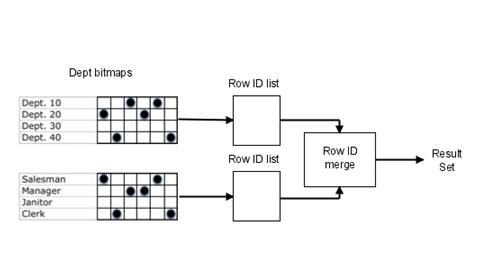
位图索引非常适合于数据仓库应用,因为数据仓库处理的是大量即席查询,几乎没有并发的事务。位图索引提供以下优势:
- 缩短了即席查询的相应时间
- 比其他索引技术节省存储空间
- 高性能
- 高效的并行DML和加载
位图索引不适合OLTP应用,OLTP应用需要处理大量并发的修改数据的事务。位图索引更适合于基于数据仓库的决策支持系统,因为决策支持系统主要是查询数据而不是修改数据。位图索引页不适合于主要用于大于或小于比较的列,只适合于等式查询,特别是AND,OR和NOT操作;大于和小于比较更适合采用B-tree索引。
CREATE BITMAP INDEX 索引名 ON 表名 (列名);
5 Oracle索引的实现
Oracle数据库使用B-tree结构组织索引以加速数据访问。如果没有索引,就只能顺序扫描整个数据库。对于n行的表,平均扫描行数是n/2。
如果将这些记录根据它们的某一列组织成B-tree结构,一个叶节点代表一条数据,那么从n行的表中查询一条记录的平均用时为log(n)。这就是Oracle数据库索引的基本原理。

B-tree的分支节点包含到其子节点的索引。最低层节点(叶节点)包含了索引数据值和其对应的rowid,rowid用于定位对应的数据表行。
参考:
Overview of Indexes. http://docs.oracle.com/cd/B28359_01/server.111/b28318/schema.htm#i5671
CREATE INDEX. http://docs.oracle.com/cd/B28359_01/server.111/b28286/statements_5011.htm#SQLRF01209
http://docs.oracle.com/cd/B28359_01/server.111/b28318/schema.htm#CNCPT811
About Indexes. http://docs.oracle.com/cd/B28359_01/server.111/b28310/indexes001.htm
http://asktom.oracle.com/pls/asktom/f?p=100:11:0::::p11_question_id:586423377841