TLD学习笔记(六)
今天看TLD的源代码,看其中mex中的lk.cpp文件,里面是TLD中的trackering部分
其中定义了这样的函数。
//归一化相关函数
void normCrossCorrelation(IplImage *imgI, IplImage *imgJ, CvPoint2D32f *points0, CvPoint2D32f *points1, int nPts, char *status, float *match,int winsize, int method) {
IplImage *rec0 = cvCreateImage( cvSize(winsize, winsize), 8, 1 );
IplImage *rec1 = cvCreateImage( cvSize(winsize, winsize), 8, 1 );
IplImage *res = cvCreateImage( cvSize( 1, 1 ), IPL_DEPTH_32F, 1 );
for (int i = 0; i < nPts; i++) {
if (status[i] == 1) {
cvGetRectSubPix( imgI, rec0, points0[i] );
cvGetRectSubPix( imgJ, rec1, points1[i] );
cvMatchTemplate( rec0,rec1, res, method );
match[i] = ((float *)(res->imageData))[0];
} else {
match[i] = 0.0;
}
}
cvReleaseImage( &rec0 );
cvReleaseImage( &rec1 );
cvReleaseImage( &res );
}
很明显中间两个函数我就不知道是干什么的?去官网上查了下。 还是一头雾水,只知道大概是先算一个偏移量,然后再用偏移量去进行匹配,匹配的方法可以根据method的不同而用不同的公式,估计都是数学上计算相关性常用的公式。
两个函数具体的文档如下,总之这个函数就是实现了归一化互相关系数的计算,具体用的公式,后面再做分析。
getRectSubPix
Retrieves a pixel rectangle from an image with sub-pixel accuracy.
- C++: void getRectSubPix (InputArray image, Size patchSize, Point2f center, OutputArray dst, int patchType=-1 )
- Python: cv2. getRectSubPix (image, patchSize, center [, patch [, patchType ] ] ) → patch
- C: void cvGetRectSubPix (const CvArr* src, CvArr* dst, CvPoint2D32f center )
- Python: cv. GetRectSubPix (src, dst, center ) → None
-
Parameters: - src – Source image.
- patchSize – Size of the extracted patch.
- center – Floating point coordinates of the center of the extracted rectangle within the source image. The center must be inside the image.
- dst – Extracted patch that has the size patchSize and the same number of channels as src .
- patchType – Depth of the extracted pixels. By default, they have the same depth as src .
The function getRectSubPix extracts pixels from src :
where the values of the pixels at non-integer coordinates are retrieved using bilinear interpolation. Every channel of multi-channel images is processed independently. While the center of the rectangle must be inside the image, parts of the rectangle may be outside. In this case, the replication border mode (see borderInterpolate() ) is used to extrapolate the pixel values outside of the image.
See also
warpAffine(), warpPerspective()
matchTemplate
Compares a template against overlapped image regions.
- C++: void matchTemplate (InputArray image, InputArray temp, OutputArray result, int method )
- Python: cv2. matchTemplate (image, templ, method [, result ] ) → result
- C: void cvMatchTemplate (const CvArr* image, const CvArr* templ, CvArr* result, int method )
- Python: cv. MatchTemplate (image, templ, result, method ) → None
-
Parameters: - image – Image where the search is running. It must be 8-bit or 32-bit floating-point.
- templ – Searched template. It must be not greater than the source image and have the same data type.
- result – Map of comparison results. It must be single-channel 32-bit floating-point. If image is and templ is
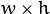 , then resultis
, then resultis 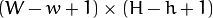 .
. - method – Parameter specifying the comparison method (see below).
The function slides through image , compares the overlapped patches of size ![]() againsttempl using the specified method and stores the comparison results in result . Here are the formulae for the available comparison methods (
againsttempl using the specified method and stores the comparison results in result . Here are the formulae for the available comparison methods ( ![]() denotes image,
denotes image, ![]() template,
template, ![]() result ). The summation is done over template and/or the image patch:
result ). The summation is done over template and/or the image patch: ![]() * method=CV_TM_SQDIFF
* method=CV_TM_SQDIFF
-
method=CV_TM_SQDIFF_NORMED
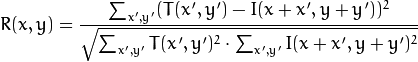
-
method=CV_TM_CCORR
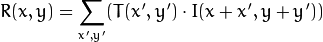
-
method=CV_TM_CCORR_NORMED
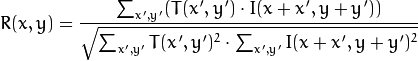
-
method=CV_TM_CCOEFF
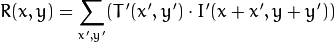
where
-
method=CV_TM_CCOEFF_NORMED
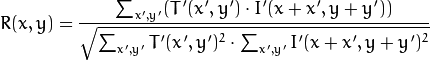
After the function finishes the comparison, the best matches can be found as global minimums (when CV_TM_SQDIFF was used) or maximums (when CV_TM_CCORR or CV_TM_CCOEFF was used) using the minMaxLoc() function. In case of a color image, template summation in the numerator and each sum in the denominator is done over all of the channels and separate mean values are used for each channel. That is, the function can take a color template and a color image. The result will still be a single-channel image, which is easier to analyze.