作者讲解视频: http://www.youtube.com/watch?v=_J_clwqQ4gI
matlab代码实现: http://people.cs.uchicago.edu/~rbg/latent/
开源C代码实现: https://github.com/liuliu/ccv [有错误,慎用!代码质量一般,coding style较差]
==================================================================================
http://www.computervisiononline.com/software/discriminatively-trained-deformable-part-models
Over the past few years a complete learning-based system for detecting and localizing objects in images has been developed that represents objects using mixtures of deformable part models. These models are trained using a discriminative method that only requires bounding boxes for the objects in an image. The approach leads to efficient object detectors that achieve state of the art results on the PASCAL and INRIA person datasets.
At a high level the system can be characterized by the combination of
- Strong low-level features based on histograms of oriented gradients (HOG)
- Efficient matching algorithms for deformable part-based models (pictorial structures)
- Discriminative learning with latent variables (latent SVM)
This work was awarded the PASCAL VOC "Lifetime Achievement" Prize in 2010.
Related publications:
P. Felzenszwalb, D. McAllester, D. Ramaman, A Discriminatively Trained, Multiscale, Deformable Part Model
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2008
P. Felzenszwalb, R. Girshick, D. McAllester, D. Ramanan, Object Detection with Discriminatively Trained Part Based Models IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 32, No. 9, Sep. 2010 pdf
P. Felzenszwalb, R. Girshick, D. McAllester, Cascade Object Detection with Deformable Part Models IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2010 pdf
P. Felzenszwalb, D. McAllester, Object Detection Grammars University of Chicago, Computer Science TR-2010-02, February 2010 pdf
R. Girshick, P. Felzenszwalb, D. McAllester, Object Detection with Grammar Models, Neural Information Processing Systems (NIPS), 2011 pdf
R. Girshick, From Rigid Templates to Grammars: Object Detection with Structured Models, Ph.D. dissertation, The University of Chicago, Apr. 2012 pdf
Software URL:
http://people.cs.uchicago.edu/~rbg/latent/
=============================================================================
改进版:http://agamenon.tsc.uah.es/Personales/rlopez/data/pose-estimation/
Deformable Part Models Revisited: A Performance Evaluation for ObjectCategory Pose Estimation
Abstract
Deformable PartModels (DPMs) as introduced by Felzenszwalb et al. have shown remarkably goodresults for category-level object detection. In this paper, we explore whetherthey are also well suited for the related problem of category-level object poseestimation. To this end, we extend the original DPM so as to improve itsaccuracy in object category pose estimation and design novel and more effectivelearning strategies. We benchmark the methods using various publicly availabledata sets. Provided that the training data is sufficiently balanced and clean,our method outperforms the state-of-the-art.
Results
Downloads
Software
- Download a ready-to-use mDPM car pose estimator for 4, 8 a 16 views.
Data
- Download the PASCAL VOC Augmented datasets (2006, 2007 and 2010).
- Download the ICARO dataset.
You may downloadthe paper too:
DeformablePart Models Revisited: A Performance Evaluation for Object Category PoseEstimation, R. J. López-Sastre, T. Tuytelaars, S. Savarese. ICCV 2011 - 1stIEEE Workshop on Challenges and Opportunities in Robot Perception. Last update (11-Jan-12) with new results.
====================================================
实验记录-deformable part models训练数据准备及中间结果记录
准备数据集:1.生成新的imagelist
2.改变SelectImagesParsingXML()中if objectsize /imagesize >= 0.9这一句的参数来选择bounding box比例不一样的图像,保存在imagelist中。
3.运行上述程序。
4.在VOCdevkit中新建文件夹,如VOC0002,并在其中添加5个文件夹,分别是:
Annotations,ImageSets,JPEGImages,SegmentationClass,SegmentationObject。
5.修改SelectImagesToDirectory()函数中保存文件的位置,将上述imagelist中的图像及其标注复制到对应的文件夹中。有两个地方需要改动,如改成VOC0002。
还要改变对应的imagelistDIR = [tmp '/imagelist_0.95_201.txt'];的imagelist的文件名字。这里表示imagelist中阈值设置为0.95时有201幅图像被选出。
7.准备trainval.txt,和train和val.txt。(注意应提前复制和准备好空文件,存放在experiment/VOCdevkit/VOC2002/ImageSets/Main文件夹下。
6.运行上述程序。程序的第一部分将image和annotation复制到文件夹中,第二部分生成对应的trainval.txt。
7.得到trainval.txt后,使用SplitTrainVal()将其随机分成两个集合,train和val。修改文件夹中的VOC0002即可。运行上述程序。
8.数据准备完毕,进入训练程序文件夹:~/experiment/mycode/voc-release4.01,比如说要运行pascal(‘person’,3);那么还需要改几个地方:
1.globals.m中的 VOCyear = '0002';需要修改
2.由于pascal_init.m中:
tmp = pwd;
cd(VOCdevkit);
addpath([cd '/VOCcode']);
VOCinit;
cd(tmp);
运行了VOCdevkit中VOCcode里的VOCinit,而其中包含了解析VOCopts的重要初始化内容,如果不改变会影响到后面的训练完全错误。
需要将VOCopts.dataset = 'VOC0001';中文件夹进行指定修改。
9.运行pascal(‘person’,3);注意应到mycode/voc-release4.01这个目录下。
运行1:
2.
3.阈值0.95,共201幅图像进行训练。
=======================================================================
花边:http://www.zhizhihu.com/html/y2011/3436.html
OpenCV中HOG人检测以及Part Model latent SVM目标识别
发表于361 天前
⁄ 技术, 科研
⁄ 被围观
3753 次+
要做点视频中检测的小东西,发现OpenCV中已经十分全面了,要做的东西要用到Navneet Dalal and Bill Triggs的Histogram of Oriented Gradients (HOG)方法以及Pedro F. Felzenszwalb的Discriminatively Trained Deformable Part Models,其实这两种方法在OpenCV中已经有完整的实现了,我用的opencv版本是2.3.1。
先是使用HOG进行People Detection的,已经提供了完整的方法,在peopledetect.cpp中,主要的方法有HOG特征提取以及训练还有识别,你可以通过 hog.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());来用已经训练好的模型直接检测。hog.detectMultiScale(...)进行检测。

2、通过latentSVM进行目标的识别。相关的例子在latentsvmdetect.cpp中,不过例子只提供了cat的模型,怎么自己训练自己的模型需要摸索一下了。但是这个cat的结果感觉不是很好的样子,可能模型的问题吧。瓶子应该很不错。
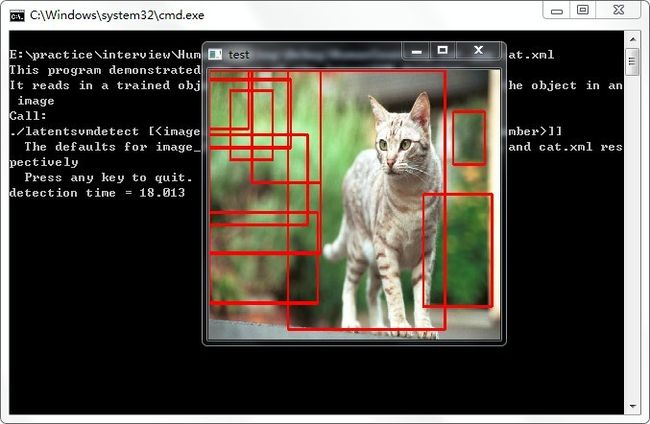
这两种方法的基本方法都在opencv_objdetect中,hog.cpp以及latensvm.cpp等,自己开发也方便。
OpenCV潜力无限,用起来也方便,十分之方便,主要是C系列的,效率也不用很担心,况且有一些GPU的应用,估计发展一下还会有并行计算等得框架来进一步提高效率吧。
==============================================================================
http://bubblexc.com/y2011/422/
Deformable Part Model是最近两年最为流行的图像中物体检测模型,利用这个模型的方法在近几届PASCAL VOC Challenge中都取得了较好的效果。其作者,芝加哥大学的Pedro Felzenszwalb教授,也因为这项成就获得了VOC组委会授予的终身成就奖。有人认为这个模型是目前最好的物体检测算法。
不同于bag of features和hog模板匹配,这类“object conceptually weaker”的模型,在Deformable Part Model中,通过描述每一部分和部分间的位置关系来表示物体(part+deformable configuration)。其实早在1973年,Part Model就已经在 "The representation and matching of pictorial structures" 这篇文章中被提出了。
Part Model中,我们通过描述a collection of parts以及connection between parts来表示物体。图1表示经典的弹簧模型,物体的每一部分通过弹簧连接。我们定义一个energy function,该函数度量了两部分之和:每一部分的匹配程度,部分间连接的变化程度(可以想象为弹簧的形变量)。与模型匹配最好的图像就是能使这个energy function最小的图片。形式化表示中,我们可以用一无向图 G=(V,E) 来表示物体的模型, V={v1,...,vn} 代表n个部分,边 (vi,vj)∈E 代表两部分间的连接。物体的某个实例的configuration可以表示为 L=(l1,...,ln) , li 表示为 vi 的位置(可以简单的将图片的configuration理解为各部分的位置布局,实际configuration可以包含part的其他属性)。给定一幅图像,用 mi(li) 来度量 vi 被放置图片中的 li 位置时,与模板的不匹配程度;用 dij(li,lj) 度量 vi,vj 被分别放置在图片中的 li,lj 位置时,模型的变化程度。因此,一副图像相对于模型的最优configuration,就是既能使每一部分匹配的好,又能使部分间的相对关系与模型尽可能的相符的那一个。同样的,模型也自然要描述这两部分。可以通过下面的公式描述最优configuration:
L∗=argminL(∑i=1nmi(li)+∑(vi,vj)∈Edij(li,lj))
Pedro Felzenszwalb教授提出的Deformable Part Model用到了三方面的知识:1.Hog Features 2.Part Model 3. Latent SVM。
- 作者通过Hog特征模板来刻画每一部分,然后进行匹配。并且采用了金字塔,即在不同的分辨率上提取Hog特征
- 利用上段提出的Part Model。在进行object detection时,detect window的得分等于part的匹配得分减去模型变化的花费。
- 在训练模型时,需要训练得到每一个part的Hog模板,以及衡量part位置分布cost的参数。文章中提出了Latent SVM方法,将deformable part model的学习问题转换为一个分类问题。利用SVM学习,将part的位置分布作为latent values,模型的参数转化为SVM的分割超平面。具体实现中,作者采用了迭代计算的方法,不断地更新模型。
作者的页面上有模型的matlab实现源码,必须运行在linux或mac平台中。另外,源码中已经包含PASCAL VOC中各个类别训练好的模型,可以直接用,如果需要自己训练模型,这个过程是很耗时的。为了提高效率,作者又在2010年的“Cascade Object Detection with Deformable Part Models”这篇文章中对part model做了改进,将效率提高了20倍左右。
相关资料:
- Fischler, M.A. and Elschlager, R.A. The representation and matching of pictorial structures, 1973
- Felzenszwalb, P.F. and Huttenlocher, D.P. Pictorial structures for object recognition,2005
- http://people.csail.mit.edu/torralba/courses/6.870/slide/6870_2008-09-10_histograms_pinto_opt.pdf
Stanford University
CS223C: The Cutting Edge of Computer vision
Project Description:
Implement a pedestrian detection algorithm using the HOG (Histogram of Oriented Gradients) feature representation and the Deformable Part Model.
• Refer to Viola & Jones for a general idea about object detection systems.
• Refer to Dalal & Triggs for the HOG (Histogram of Oriented Gradients) feature representation.
• Refer to Felzenszwalb et al (2008) for the Deformable Part Model for object detection. Felzenszwalb et al (PAMI 2010) is a more detailed
version of the paper.
• Refer to Felzenszwalb et al (CVPR 2010) for how to make your algorithm faster. (We encourage you to read this paper to get more ideas about how to improve a detection system. But you are not required to implement this paper.)
Dataset and Project Setup:
In this project, we will use PASCAL VOC 2007 person detection dataset to train and test your program. Here is a brief introduction of the datasets (you only need to look at the "person" category). The performance of your method will be evaluated using precision & recall curve and average precision (AP). Here is a criteria to evaluate whether a specific detection result is correct or not.
Fortunately, in this project you do not need to install the PASCAL VOC development kit and write codes of how to evaluate the performance by yourself. Please follow these steps to start your project:
• Download the PASCAL VOC development kit that has been installed by us from here (859MB). Untar the file.
• Run "VOCdevkit/example_detector.m" in matlab, which contains a very simple person detection training and testing method. This program
loads training data to memory, trains a person detector, tests the trained detector on testing images, and finally computes the average
precision score and draws the precision-recall curve.
• In "VOCdevkit/example_detector.m", replace "detector=train(VOCopts,cls)" with your own training implementation. Refer to the "train"
function for how to load training images and ground truth bounding boxes.
• In "VOCdevkit/example_detector.m", replace "test(VOCopts,cls,detector)" with your own testing implementation. Refer to the "test" function
for how to load testing images and ground truth bounding boxes.
More Guides
• The authors of the deformable part model have the code online:http://people.cs.uchicago.edu/~pff/latent/. You can read the code
before you start your own implementation. But the authors' code has many tricks that are not fully covered by their paper, and you do not
need to worry if you cannot fully understand their code.
• Implement your method based on the CVPR 2008 paper but you do not need to implement the mixture model and dynamic programming for
updating deformable parts. You can refer to the PAMI 2010 paper to have a better understanding of the method, but you do not need to
implement the additional details in this paper.
• Directly copying the authors' code without mentioning it in your write-up is an honor code violation. But if you do have trouble in
implementing a specific function, you might refer to the existing codes and mention this clearly in your write-up. Note that implementing a
function by yourself but have poor performance is more desirable than using existing codes.
• There might be some very time-consuming parts in the method. You may use mex-files which allows you to call C functions in matlab so
that your algorithm can be accelerated.
• If your compute is limited by memory or your code is extremely slow, you do not need to use all training and testing images. You can use half
or a even smaller proportion of the images. But it is encouraged to use all training (2501) and testing (4952) images in your experiments.
• If you have any questions or trouble, feel free to ask questions in Piazzza or send emails to the course staff email "cs223c-spr1011-staff [at]
lists [dot] stanford [dot] edu".
• Although you are basically implementing an existing algorithm, the project is very open and you can do everything you can imagine to
achieve good performance. You do not need to worry too much if your algorithm is not doing a perfect job. But we do encourage you to
start your projects earlier so that you have more time to play with your algorithm.
• Your project will not be evaluated based only on the performance of your algorithm. Show us that you have a good understanding of the
problem and the algorithm, and try to have deep insights from your experiment results.
References:
• P.Viola and M.Jones. Rapid Object Detection using a Boosted Cascade of Simple Features. CVPR 2001.
• N.Dalal and B.Triggs. Histograms of Oriented Gradients for Human Detection. CVPR 2005.
• P.Felzenszwalb, D.McAllester, and D.Ramanan. A Discriminatively Trained, Multiscale, Deformable Part Model. CVPR 2008.
• P.Felzenszwalb, R.Girshick, D. McAllester, and D.Ramanan. Object Detection with Discriminatively Trained Part-Based Models. PAMI
2010.
• P.Felzenszwalb, R.Girshick, and D.McAllester. Cascade Object Detection with Deformable Part Models. CVPR 2010.
Important Dates:
• Deadline of submitting the code and write-up: Sat, Apr 16 (23:59pm), how to submit your documents will be updated later
• A short presentation of your work: Mon, Apr 18 (in class)