Raft一致性算法
Why Not Paxos
Paxos算法是莱斯利·兰伯特(LeslieLamport,就是 LaTeX 中的”La”,此人现在在微软研究院)于1990年提出的一种基于消息传递的一致性算法。由于算法难以理解起初并没有引起人们的重视,使Lamport在八年后1998年重新发表到ACM Transactions on Computer Systems上(The Part-TimeParliament)。即便如此paxos算法还是没有得到重视,2001年Lamport 觉得同行无法接受他的幽默感,于是用容易接受的方法重新表述了一遍(Paxos MadeSimple)。可见Lamport对Paxos算法情有独钟。近几年Paxos算法的普遍使用也证明它在分布式一致性算法中的重要地位。2006年Google的三篇论文初现“云”的端倪,其中的Chubby Lock服务使用Paxos作为Chubby Cell中的一致性算法,Paxos的人气从此一路狂飙。Lamport 本人在 他的blog 中描写了他用9年时间发表这个算法的前前后后。
“There is only one consensus protocol, and that’sPaxos-all other approaches are just broken versions of Paxos.” –Chubby authors
“The dirtylittle secret of the NSDI community is that at most five people really, trulyunderstand every part of Paxos ;-).” –NSDI reviewer
Notes:回想当年,我不知翻阅了多少资料,才勉强弄明白“Basic Paxos”,由于缺乏实践体会,至今对于“Multi-Paxos”仍如云里雾里,不得要领。反观本文的主角Raft,《InSearch of an Understandable Consensus Algorithm》,从它设计之初,作者就将Understandable作为最高准则,这在诸多决策选择时均有体现。
问题描述
分布式系统中的节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。基于消息传递通信模型的分布式系统,不可避免地会发生以下错误:进程可能会慢、垮、重启,消息可能会延迟、丢失、重复(不考虑“Byzantinefailure”)。
一个典型的场景是:在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么它们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个「一致性算法」以保证每个节点看到的指令一致。一个通用的一致性算法可以应用在许多场景中,是分布式计算中的重要问题。从20世纪80年代起对于一致性算法的研究就没有停止过。
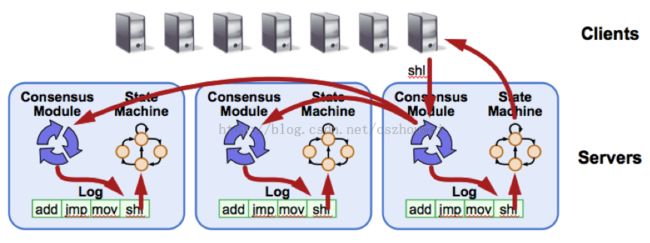
图 1Replicated State Machine Architecture
Raft算法将这类问题抽象为“ReplicatedState Machine”,详见上图,每台Server保存用户命令的日志,供本地状态机顺序执行。显而易见,为了保证“Replicated State Machine”的一致性,我们只需要保证“ReplicatedLog”的一致性。
算法描述
通常来说,在分布式环境下,可以通过两种手段达成一致:
1. Symmetric, leader-less
所有Server都是对等的,Client可以和任意Server进行交互
2. Asymmetric, leader-based
任意时刻,有且仅有1台Server拥有决策权,Client仅和该Leader交互
“Designing for understandability”的Raft算法采用后者,基于以下考虑:
1. 问题分解:Normaloperation & Leader changes
2. 简化操作:Noconflicts in normal operation
3. 更加高效:Moreefficient than leader-less approaches
基本概念
Server States
Raft算法将Server划分为3种角色:
1. Leader
负责Client交互和log复制,同一时刻系统中最多存在1个
2. Follower
被动响应请求RPC,从不主动发起请求RPC
3. Candidate
由Follower向Leader转换的中间状态
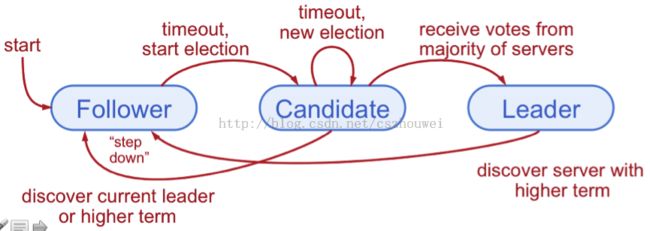
图 2Server States
Terms
众所周知,在分布式环境中,“时间同步”本身是一个很大的难题,但是为了识别“过期信息”,时间信息又是必不可少的。Raft为了解决这个问题,将时间切分为一个个的Term,可以认为是一种“逻辑时间”。如下图所示:
1. 每个Term至多存在1个Leader
2. 某些Term由于选举失败,不存在Leader
3. 每个Server本地维护currentTerm
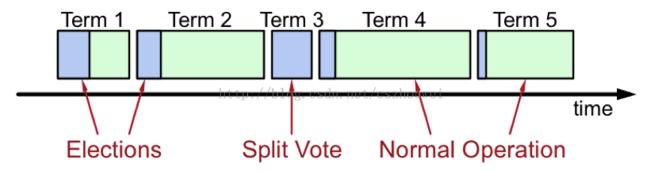
图 3Terms
Heartbeats and Timeouts
1. 所有的Server均以Follower角色启动,并启动选举定时器
2. Follower期望从Leader或者Candidate接收RPC
3. Leader必须广播Heartbeat重置Follower的选举定时器
4. 如果Follower选举定时器超时,则假定Leader已经crash,发起选举
Leader election
自增currentTerm,由Follower转换为Candidate,设置votedFor为自身,并行发起RequestVote RPC,不断重试,直至满足以下任一条件:
1. 获得超过半数Server的投票,转换为Leader,广播Heartbeat
2. 接收到合法Leader的AppendEntries RPC,转换为Follower
3. 选举超时,没有Server选举成功,自增currentTerm,重新选举
细节补充:
1. Candidate在等待投票结果的过程中,可能会接收到来自其它Leader的AppendEntries RPC。如果该Leader的Term不小于本地的currentTerm,则认可该Leader身份的合法性,主动降级为Follower;反之,则维持Candidate身份,继续等待投票结果
2. Candidate既没有选举成功,也没有收到其它Leader的RPC,这种情况一般出现在多个节点同时发起选举(如图Split Vote),最终每个Candidate都将超时。为了减少冲突,这里采取“随机退让”策略,每个Candidate重启选举定时器(随机值),大大降低了冲突概率
Log replication
图 4Log Structure
正常操作流程:
1. Client发送command给Leader
2. Leader追加command至本地log
3. Leader广播AppendEntriesRPC至Follower
4. 一旦日志项committed成功:
1) Leader应用对应的command至本地StateMachine,并返回结果至Client
2) Leader通过后续AppendEntriesRPC将committed日志项通知到Follower
3) Follower收到committed日志项后,将其应用至本地StateMachine
Safety
为了保证整个过程的正确性,Raft算法保证以下属性时刻为真:
1. Election Safety
在任意指定Term内,最多选举出一个Leader
2. Leader Append-Only
Leader从不“重写”或者“删除”本地Log,仅仅“追加”本地Log
3. Log Matching
如果两个节点上的日志项拥有相同的Index和Term,那么这两个节点[0, Index]范围内的Log完全一致
4. Leader Completeness
如果某个日志项在某个Term被commit,那么后续任意Term的Leader均拥有该日志项
5. State Machine Safety
一旦某个server将某个日志项应用于本地状态机,以后所有server对于该偏移都将应用相同日志项
直观解释:
为了便于大家理解Raft算法的正确性,这里对于上述性质进行一些非严格证明。
“ElectionSafety”:反证法,假设某个Term同时选举产生两个LeaderA和LeaderB,根据选举过程定义,A和B必须同时获得超过半数节点的投票,至少存在节点N同时给予A和B投票,矛盾
LeaderAppend-Only: Raft算法中Leader权威至高无上,当Follower和Leader产生分歧的时候,永远是Leader去覆盖修正Follower
LogMatching:分两步走,首先证明具有相同Index和Term的日志项相同,然后证明所有之前的日志项均相同。第一步比较显然,由Election Safety直接可得。第二步的证明借助归纳法,初始状态,所有节点均空,显然满足,后续每次AppendEntries RPC调用,Leader将包含上一个日志项的Index和Term,如果Follower校验发现不一致,则拒绝该AppendEntries请求,进入修复过程,因此每次AppendEntries调用成功,Leader可以确信Follower已经追上当前更新
LeaderCompleteness:为了满足该性质,Raft还引入了一些额外限制,比如,Candidate的RequestVote RPC请求携带本地日志信息,若Follower发现自己“更完整”,则拒绝该Candidate。所谓“更完整”,是指本地Term更大或者Term一致但是Index更大。有了这个限制,我们就可以利用反证法证明该性质了。假设在TermX成功commit某日志项,考虑最小的TermY不包含该日志项且满足Y>X,那么必然存在某个节点N既从LeaderX处接受了该日志项,同时投票同意了LeaderY的选举,后续矛盾就不言而喻了
StateMachine Safety:由于LeaderCompleteness性质存在,该性质不言而喻
Cluster membership changes
在实际系统中,由于硬件故障、负载变化等因素,机器动态增减是不可避免的。最简单的做法是,运维人员将系统临时下线,修改配置,重新上线。但是这种做法存在两个缺点:
1. 系统临时不可用
2. 人为操作易出错
图 5Online Switch Directly
失败的尝试:通过运维工具广播系统配置变更,显然,在分布式环境下,所有节点不可能在同一时刻切换至最新配置。由上图不难看出,系统存在冲突的时间窗口,同时存在新旧两份Majority。
两阶段方案:为了避免冲突,Raft引入Joint中间配置,采取了两阶段方案。当Leader接收到配置切换命令(Cold->Cnew)后,将Cold,new作为日志项进行正常的复制,任何Server一旦将新的配置项添加至本地日志,后续所有的决策必须基于最新的配置项(不管该配置项有没有commit),当Leader确认Cold,new成功commit后,使用相同的策略提交Cnew。系统中配置切换过程如下图所示,不难看出该方法杜绝了Cold和Cnew同时生效的冲突,保证了配置切换过程的一致性。
图 6Joint Consensus
Log compaction
随着系统的持续运行,操作日志不断膨胀,导致日志重放时间增长,最终将导致系统可用性的下降。快照(Snapshot)应该是用于“日志压缩”最常见的手段,Raft也不例外。具体做法如下图所示:
图 7S基于“快照”的日志压缩
与Raft其它操作Leader-Based不同,snapshot是由各个节点独立生成的。除了日志压缩这一个作用之外,snapshot还可以用于同步状态:slow-follower以及new-server,Raft使用InstallSnapshot RPC完成该过程,不再赘述。
Client interaction
典型的用户交互流程:
1. Client发送command给Leader
若Leader未知,挑选任意节点,若该节点非Leader,则重定向至Leader
2. Leader追加日志项,等待commit,更新本地状态机,最终响应Client
3. 若Client超时,则不断重试,直至收到响应为止
细心的读者可能已经发现这里存在漏洞:Leader在响应Client之前crash,如果Client简单重试,可能会导致command被执行多次。
Raft给出的方案:Client赋予每个command唯一标识,Leader在接收command之前首先检查本地log,若标识已存在,则直接响应。如此,只要Client没有crash,可以做到“Exactly Once”的语义保证。
个人建议:尽量保证操作的“幂等性”,简化系统设计!
发展现状
Raft算法虽然诞生不久,但是在业界已经引起广泛关注,强烈推荐大家浏览其官网http://raftconsensus.github.io,上面有丰富的学习资料,目前Raft算法的开源实现已经涵盖几乎所有主流语言(C/C++/Java/Python/Javascript …),其流行程度可见一斑。由此可见,一项技术能否在工业界大行其道,有时“可理解性”、“可实现性”才是至关重要的。
应用场景
timyang在《Paxos在大型系统中常见的应用场景》一文中,列举了一些Paxos常用的应用场合:
1. Database replication, logreplication …
2. Naming service
3. 配置管理
4. 用户角色
5. 号码分配