也谈零拷贝(一) 抛砖篇
首先,如果读者之前不熟悉什么是零拷贝,请参考下面的链接:
Linux中的零拷贝技术,第1部分
http://www.ibm.com/developerworks/cn/linux/l-cn-zerocopy1/index.html
Linux中的零拷贝技术,第2部分
http://www.ibm.com/developerworks/cn/linux/l-cn-zerocopy2/index.html
通过零拷贝实现有效数据传输
http://www.ibm.com/developerworks/cn/java/j-zerocopy/
链接里给出的文章已经很好的说明了零拷贝的概念和作用(即更有效地实现数据传输),以及如何实现零拷贝。下面我们一步步地来看看普通情况下数据的发送和接收流程和使用零拷贝技术情况下数据的发送和接收流程到底有何区别,从而进一步理解零拷贝的含义及其优点。
一、数据传输:传统方法
考虑一下从一个磁盘文件中读出数据并将数据传输到网络上另一程序的场景(这个场景表述出了很多服务器应用程序的行为,包括提供静态内容的 Web应用程序、FTP服务器、邮件服务器等)。
图 1
数据传输从读磁盘文件开始到数据到达网卡为止,整个过程描述如下:
图 2
Step1: read()调用引发了第一次从用户模式到内核模式的上下文切换。在内部,发出 sys_read()(或等效内容)从文件中读取数据。DMA引擎执行了第一次拷贝/复制,它从磁盘中读取文件内容,然后将它们存储到一个内核地址空间缓存区中。
Step2:所需的数据被从读取缓冲区拷贝到用户缓冲区,read()调用返回。该调用的返回引发了内核模式到用户模式的第二次上下文切换。这同时产生了第二次拷贝/复制,现在数据被储存在用户地址空间缓冲区。
Step3: send()套接字(或者write()调用)引发了从用户模式到内核模式的第三次上下文切换。数据被第三次拷贝/复制,并被再次放置在内核地址空间缓冲区。但是这一次放置的缓冲区不同,该缓冲区与目标套接字相关联。
Step4: send()调用返回,结果导致了第四次的上下文切换。DMA 引擎将数据从内核缓冲区传到协议引擎,第四次拷贝/复制独立地、异步地发生。
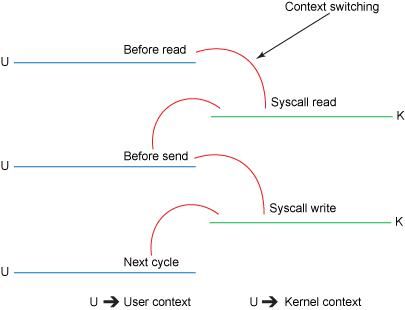
图 3
我们可以很清楚的看到,数据在磁盘、中间内核缓冲区和用户缓冲区中被拷贝了多次,并且经过了多次上下文切换。显然,这样的数据传输效率是很低下的。
而零拷贝正是通过消除这些冗余的数据拷贝从而提高了性能,下面我们就循序渐进地看看使用零拷贝传输数据的情况是什么样的:
二、数据传输:零拷贝方法
从文章开始的地方给出的链接中,简要介绍了零拷贝的几种实现方式,我们这里针对其中的mmap实现方式进行进一步的分析。当我们仔细看传统情况下的数据传输,就会注意到有些拷贝操作是可以不用做的。应用程序只是起到缓存数据并将其传回到套接字的作用而已,别无他用。我们完全可以采用下图所示的方式进行数据传输:

图 4
注意图4与图1的区别,图4中使用mmap代替了图1中的read。这会导致什么不同呢,我们又该如何实现以上的想法呢?另外,使用中间内核缓冲区,即图2中的Read buffer或图4中的页缓存,而不是直接将数据传输到用户缓冲区,看起来可能有点效率低下。但是之所以引入中间内核缓冲区的目的是想提高性能。在读取方面使用中间内核缓冲区,可以允许内核缓冲区在应用程序不需要内核缓冲区内的全部数据时,充当 “预读高速缓存(readahead cache)”的角色。这在所需数据量小于内核缓冲区大小时极大地提高了性能。在写入方面的中间缓冲区则可以让写入过程异步完成。不幸的是,如果所需数据量远大于内核缓冲区大小的话,这个方法本身可能成为一个性能瓶颈。