基于HBase做Storm 实时计算指标存储
Hi,大家好!我是祝威廉,本来微博也想叫祝威廉的,可惜被人占了,于是改名叫·祝威廉二世。然后总感觉哪里不对。目前在乐视云数据部门里从事实时计算,数据平台、搜索和推荐等多个方向。曾从事基础框架,搜索研发四年,大数据平台架构、推荐三年多,个人时间现专注于集群自动化部署,服务管理,资源自动化调度等方向。
这次探讨的主题是:
* 基于 HBase 做 Storm 实时计算指标存储 *
HBase 实时指标存储是我入职乐视云后对原有的实时系统改造的一部分。部分分享内容其实还处于实施阶段。架构方案设计的话应该是仁者见仁智者见智,也会有很多考虑不周的地方,欢迎大家批评指正。说不定大家听完分享后好的提议我们会用到工程上,也为后面的实际课程做好准备。
我之前做过一次大数据的课,比较 Naive,但是也包含了我对数据平台的一些看法。
参看:http://www.stuq.org/course/detail/999
好了,步入正文,O(∩_∩)O~
- HBase 存储设计
- Storm 结果如何存储到 HBase
- HBase 写入性能优化
- 与传统方案 (Redis/MySQL) 对比
乐视云内部用 Storm 做 CDN,点播,直播流量的计算,同时还有慢速比,卡顿比等统计指标。相应的指标会由指标名称,业务类型,客户,地域,ISP 等多个维度组成。指标计算一个比较大的问题是 Key 的集合很大。
举个例子,假设我们有客户 10w,计算指标假设 100 个,5 个 ISP,30 个地域,这样就有亿级以上的 Key 了,我们还要统计分钟级别,小时级别,天级别,月级别。所以写入量和存储量都不小。
如果采用 Redis/Memcached 写入速度是没有问题的,毕竟完全的内存操作。但是 key 集合太大,其实压力也蛮大的,我去的时候因为加了指标,结果导致 Memcache 被写爆了,所以紧急做了扩容。
首先是 Redis 查起来的太麻烦。客户端为了某个查询,需要汇总成千上万个 Key。。。业务方表示很蛋疼,我们也表示很蛋疼
其次,内存是有限的,只能存当天的。以前的数据需要转存。
第三,你还是绕不过持久化存储,于是引入 MySQL,现在是每天一张表。那 Redis 导入到 MySQL 本身就麻烦。所以工作量多了,查询也麻烦,查一个月半年的数据就吐血了。
鉴于以上原因,我们就想着有没有更合适的方案。
我们首先就想到了 HBase,因为 HBase 还是具有蛮强悍的写入性功能以及优秀的可扩展性。而事实上经过调研,我们发现 HBase 还是非常适合指标查询的,可以有效的通过列来减少 key 的数量。
举个例子,我现在想绘制某一个视频昨天每一分钟的播放量的曲线图。如果是 Redis,你很可能需要查询 1440 个 Key。如果是 HBase,只要一条记录就搞定。
我们现在上图:
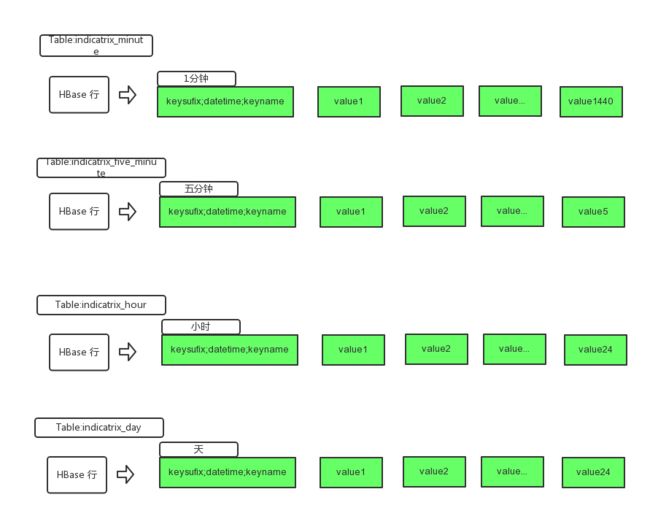
这里,我们一行可以追踪某个指标一天的情况。如果加再加个维度,无非增加一条记录。而如果是 redis,可能就多了一倍,也就是 2880 个 key 了。
假设该视频是 A,已经在线上 100 天了。我们会记录这个视频所有的 1 分钟播放数,用 Redis 可能有 100*1440 个 key,但是 HBase只要获取 100 条记录就可以找出来,我们把时间粒度转化为了 hbase 的列,从而减少行 (Key)。
我们知道 HBase 是可以多列族,多 Column,Schemaless 的。所以这里,我们建了一个列族,在该列族上,直接建了 1440 个 Column。Column 的数目和时间粒度有关。如果是一分钟粒度,会有 1440 个,如果是五分钟粒度的会有 288 个,如果是小时粒度的,会有 24 个。不同的粒度,我们会建不同的表。
写入的时候,我们可以定位到 rowkey,以及对应的 column,这里一般不会存在并发写。当然 HBase 的 increment 已经解决了并发问题,但是会造成一定的性能影响。
查询的时候,可根据天的区间查出一条相应的记录。我们是直接把记录都取出来,Column 只是一个 Int/Long 类型,所以 1440 个 Column 数据也不算大。
Storm 计算这一块,还有一个比较有意思的地方。假设 A 指标是五分钟粒度的,也就是说我们会存储 A 指标每个五分钟的值。但是在实际做存储的时候,他并不是五分钟结束后就往 HBase 里存储,而是每隔(几秒/或者一定条数后)就 increment 到 HBase 中,然后清除重新计数。
这里其实我要强调的是,到 HBase 并不是覆盖某个 Rowkey 特定的 Cloumn 值,而是在它原有的基础上,做加法。这样做可以防止时间周期比较长的指标,其累计值不会因为有拓扑当掉了而丢失数据(其实还是会丢的,但可能损失的计数比较少而已)。
丢数据比如你 kill-9 了。
大家可以想象一下,如果我计算一个五分钟的指标,到第三分钟挂掉了,此时累计值是 1000,接着拓扑重启了,五分钟还没完,剩下的两分钟它会接着累计,此时是 500。如果是覆盖写,就会得到不正确的结果,实际上整个完整的计数是 1500。
防止拓扑当掉并不是这样设计的主要原因,还有一点是计算延时了,比如某个数据片段因为某个原因,延时了十分钟才到 Storm 实时计算集群,这个时候新得到的值还可以加回去,如果是覆盖,数据就错误了。
所以 HBase 存储这块就变成做加法操作而不仅仅是简单的更新了。目前 HBase 添加了计数的功能 (Increment),而另外一个比较神奇的接口设计的地方是,竟然没有从名字上看的出是批量increment接口,一开始我以为没有,后面是去看源码,才发现是有的,就是batch接口,put,increment等都可以使用这种接口去批量提交,提高查询效率。
另外 HBase 的 Client 也是非常的奇特,比如 HTablePool 竟然是对象池而不是真实的Connection连接池,多个 HTable 对象是共享一个 Connection 链接的。当然,这里 HTable 的 Connection 会比较复杂,因为要连 Zookeeper 还有各个 Region。如果过多了,可能会对Zookeeper造成压力,这倒也问题不大。
如果不使用批量接口,客户端的写入量死活是上不去。16 台 32G,24 核的服务器,我做了预分区 (60个左右),用了四十个进程,300 个左右的线程去写,也就只能写到 60000/s 而已。
但实际并发应该是只有 40 左右的。300 个线程并没有起到太多作用。
还有就是,HBase 的 incrementColumnValue 的性能确实不高。至少和批量 Put 差距很大。所以一定要使用Batch接口。性能可以提升很多倍。
我们的测试中,还是比较平稳的,整个写入状态。抖动不大。
在整个过程中,有两点要注意:
- 预分区
- rowkey的设计要满足两个均匀,* 数量分布均匀 , 读写分布均匀 *。尤其是第二个均匀。
预分区是要看场景的,在我们这个场景下是预分区是非常重要的。否则一开始都集中在一台机器的一个 Regin 上写,估计很快写的进程就都堵住了。上线就会挂。
所以我事先收集了几天的 key,然后预先根据 key 的分布做了分区。我测试过,在我们的集群上,到了 60 个分区就是一个瓶颈,再加分区已经不能提升写入量。
写入我们也做了些优化,因为写的线程和 Storm 是混用的(其实就是 Storm 在写)。我们不能堵住了 Storm。这点我们是通过rowkey的设计来解决,保证写入和读取都能均匀的分布在HBase的各个Regin上。如果写入出现问题(比如HBase出现堵塞),一个可选的方案是将数据回写到kafka,然后再起一个拓扑尝试重新写。第二个就是HBase的主从高可用,这个有机会以后再谈。
上面的设计稿中,大家可以看到Rowkey的组成。我的建议是这样
真实key的md5 + 时间(精确到天) + 真实的key
因为md5还是有可能碰撞,所以真实的key必须存在,这点很重要,否则一旦有碰撞,计费就出问题了。
我们总结下上面的内容:
- Redis/Mysql 存储方案存在的一些缺点。
- HBase 表结构设计,充分利用了 HBase 自身的特点,有效的减少Key的数量,提高查询效率。
- Storm 写入方案,用以保证出现数据延时或者 Storm 拓扑当掉后不会导致数据不可用。
我们再看看整个存储体系完整的拓扑图。
第五个圆圈是为了在实时计算出错时,通过 Spark/MR 进行数据恢复。
第二个圆圈和第四个圆圈是为了做维度复制,比如我计算了五分钟的值,这些值其实可以自动叠加到对应的小时和天上。我们称为分裂程序
第三个圆圈就是对外吐出数据了,由我们的统一查询引擎对外提供支持查询支持了。
我们对查询做一个推演。如果我要给用户绘制流量的一个月曲线图。曲线的最小粒度是小时,小时的值是取 12 个五分钟里最高的值,我们看看需要取多少条记录完成这个查询。
我们需要取 31 条五分钟的记录,每条记录有 288 个点,对这 288 个点分成 24 份(具体就是把分钟去掉 groupBy 一下),求出每份里的最大值(每组 SortBy 一下),这样就得到了 24 个值。
我取过两天的,整个 HTTP 响应时间可以控制 50ms 左右(本机测试)。
上面的整体架构中,分裂程序是为了缓解实时写入 HBase 的压力,同时我们还利用 MR/Spark 做为恢复机制,如果实时计算产生问题,我们可以在小时内完成恢复操作,比如日志的收集程序、分拣程序、以及格式化程序。格式化程序处理完之后是 kafka,Storm 对接的是 Kafka 和 HBase。
上面就是今天分享的内容了。
感谢大家。
课程 Q&A
Q:海量存储容灾备份怎么做?
A:这个问得比较大。我只能从 HBase 的角度大概说下。HBase 是基于 HDFS 做的,HDFS 本身数据就会有 replication。通常是 3 份。所以一般机器故障是没什么问题的。但是要做到灾备,可能就要涉及到多机房问题了。比如冷备或者所谓的多活等方案。
Q:祝同学现在的工作主要是哪些?我也是做云服务器的,想请教下以后的职业发展。
A:目前现阶段主要工作是实时计算的架构调整,以及数据平台的构建,为未来的更详细的数据分析和推荐等做好准备。云服务这块,我觉得方向可以多参看 DaoCloud,数人科技。
深入容器技术或者资源调度,或者整合现有技术做完整解决方案。在整个大数据领域,算法工程师最吃香,架构也不错。
Q:祝老师能介绍下架构中数据恢复的机制么?
A:数据恢复是通过离线 MR/Spark 完成的。其实就是对原始日志重新做一遍处理。这个主要是应对实时计算出现故障,补录数据用的。
Q:distinctcount,是该如何计算,比如在这一个月 ip 数?
A:通过 Redis 来去重的。
Q:祝老师,您好,对于初学者进入打数据领域学习,有什么建议于指导,是否需要这么大量的支撑,平时可能遇不到您说的那种情况。
A:对于大数据,我觉得首先要有个一个正确的理念。这个参看我之前的课程:↓请点击“阅读原文”查看,第一节讲的就是如何正确认识大数据。通常会有五个方向:
* 平台架构
* 基于平台之上的应用开发
* 算法
* BI/可视化
* 数据分析
目前比较炙手可热的是算法,薪资较高。其实各有各的挑战。做的好都行。除了你自己想要的做的,公司的发展其实对你的职业发展影响也会比较大。
Q:老师我对您那个架构有一个问题既然有 1在计算为啥还要有 2 和 4?
A:我们是做实时计算的。但是实时计算可能出现故障,比如 crash 或者有些 bug,这个时候就需要 2/4 离线补录重算。
Q:针对你们的一分钟设计,如果列值比较复杂,比如要分析用户数,用户来源,用户 ip 等等,这个时候怎么设计表结构?
A:用户来源,用户 ip 应该设计在 key 里而不是列里。列里存的是某个 key 在某天的某个一分钟里产生的数。对于 HBase 理论上其实我也是不怕 key 多的,它本来就是为了海量存储设计的。
Q:HBase 是否适合做实时统计分析,比如 group by 操作如何能够支撑高并发?
A:不适合。只适合简单的 key 查询或者 rowkey 的 range 查询。我不建议在其之上做复杂运算。
Q:祝老师您好,我最近要一个协处理器的功能,但是业务需要区别 hbase 的新增和更新,我在 Google 找到 incrementcolumnvalue 可以做到,但是目前并没有试成功,请问您有没有这方面的经验或者建议呢?谢谢!
A:无法使用是版本问题么?incrementcolumnvalue 就是新增,不存在则视初始值为 0,并且它会直接返回新增后的结果值,并且能保证原子操作。