tesseract训练字库
tesseract 训练字库先做两个准备工作
1.下载工具cowboxer
http://download.csdn.net/detail/cxf7394373/5305519
2. 下载tesseract-ocr.exe
https://code.google.com/p/tesseract-ocr/downloads/list
3. 安装tessract-ocr
我直接安装在了D:\\下面
现在可以开始了,训练步骤包括以下几步:
1. 识别图片
打开cmd,cd 至D:\\tesseract\\下面,拷贝一张图片1.tif至该目录下,执行下面的命令
tesseract 1.tif 1 –l chi_sim batch.nochopmakebox
2.在cowbox中调整方框大小
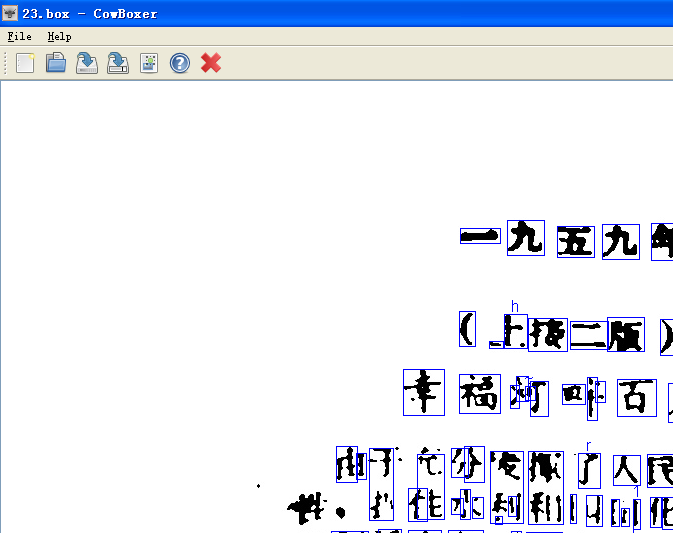
在D:\\tesseract\\下会生成一个文件1.box,用cowboxer工具打开1.box,会显示如下图的内容,纠正不正确的文字框,如果是中文,先输入拼音,所有修改完之后,保存。然后用记事本打开1.box,再改成汉字。
3. 训练字库,在这里是对两张图片进行了处理,也就是说这个工具可以把多张图片的字训练至一个字库中,过程如下:
tesseract 1.tif 1 nobatch box.train
tesseract 2.tif 2 nobatch box.train
training\mftraining -U unicharset -O test.unicharset 1.tr 2.tr
training\cntraining 1.tr 2.tr
rename normproto test.normproto
rename Microfeat test.Microfeat
rename inttemp test.inttemp
rename pffmtable test.pffmtable
..\training\combine_tessdata test.
最后出现如下的结果,第 2,4,5,6,行出现非-1数字时说明生成了新的字库。
