深入理解JVM之JVM内存区域与内存分配
前言:这是一篇关于JVM内存区域的文章,由网上一些有关这方面的文章和《深入理解Java虚拟机》整理而来,所以会有些类同的地方,也不能保证我自己写的比其他网上的和书本上的要好,也不可能会这样。写博客的目的是为了个人对这方面自己理解的分享与个人的积累,所以有写错的地方多多指教。
看到深入两字,相信很多的JAVA初学者都会直接忽略这样的文章,其实关于JVM内存区域的知识对于初学者来说其实是很重要的,了解Java内存分配的原理,这对于以后JAVA的学习会有更深刻的理解,这是我个人的看法。
先来看看JVM运行时候的内存区域
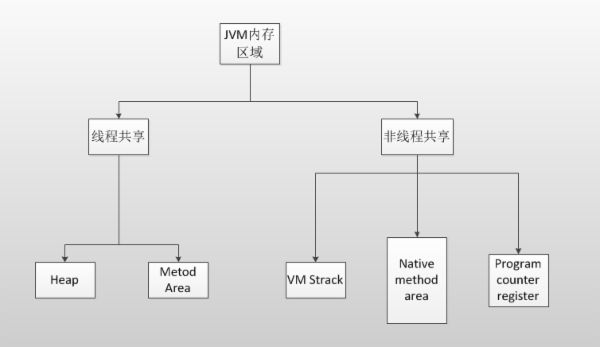
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) , Heap(堆) , Program Counter Register(程序计数器) , VM Stack(虚拟机栈,也有翻译成JAVA 方法栈的),Native Method Stack ( 本地方法栈 ),其中 Method Area 和 Heap 是线程共享的 ,VM Stack,Native Method Stack 和 Program Counter Register 是非线程共享的。为什么分为 线程共享和非线程共享的呢?请继续往下看。
首先我们熟悉一下一个一般性的 Java 程序的工作过程。一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),每个java程序都需要运行在自己的JVM上,然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。那么程序开始运行后,都是如何涉及到各内存区域的呢?
概括地说来,JVM初始运行的时候都会分配好 Method Area(方法区) 和 Heap(堆) ,而JVM 每遇到一个线程,就为其分配一个 Program Counter Register(程序计数器) , VM Stack(虚拟机栈)和Native Method Stack (本地方法栈), 当线程终止时,三者(虚拟机栈,本地方法栈和程序计数器)所占用的内存空间也会被释放掉。这也是为什么我把内存区域分为线程共享和非线程共享的原因,非线程共享的那三个区域的生命周期与所属线程相同,而线程共享的区域与JAVA程序运行的生命周期相同,所以这也是系统垃圾回收的场所只发生在线程共享的区域(实际上对大部分虚拟机来说知发生在Heap上)的原因。
1. 程序计数器
程序计数器是一块较小的内存区域,作用可以看做是当前线程执行的字节码的位置指示器。分支、循环、跳转、异常处理和线程恢复等基础功能都需要依赖这个计算器来完成,不多说。
2.VM Strack
先来了解下JAVA指令的构成:
JAVA指令由 操作码 (方法本身)和 操作数 (方法内部变量) 组成。
1)方法本身是指令的 操作码 部分,保存在Stack中;
2)方法内部变量(局部变量)作为指令的 操作数 部分,跟在指令的操作码之后,保存在Stack中(实际上是简单类型(int,byte,short 等)保存在Stack中,对象类型在Stack中保存地址,在Heap 中保存值);
虚拟机 栈也叫栈内存,是在线程创建时创建,它的 生命期是跟随线程的生命 期 ,线程结束栈内存也就释放, 对于栈来说不存在垃圾回收问题,只要线程一结束,该栈就 Over,所以不存在垃圾回收 。 也有一些资料翻译成JAVA方法栈,大概是因为它所描述的是java方法执行的内存模型,每个方法执行的同时创建帧栈(Strack Frame)用于存储局部变量表(包含了对应的方法参数和局部变量),操作栈(Operand Stack,记录出栈、入栈的操作),动态链接、方法出口等信息,每个方法被调用直到执行完毕的过程,对应这帧栈在虚拟机栈的入栈和出栈的过程。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象的引用(reference类型,不等同于对象本身,根据不同的虚拟机实现,可能是一个指向对象起始地址的引用指针,也可能是一个代表对象的句柄或者其他与对象相关的位置)和 returnAdress类型(指向下一条字节码指令的地址)。局部变量表所需的内存空间在编译期间完成分配,在方法在运行之前,该局部变量表所需要的内存空间是固定的,运行期间也不会改变。
栈帧是一个内存区块,是一个数据集, 是 一个有关方法(Method)和运行期数据的数据集 ,当一个方法 A 被调用时就产生了一个栈帧 F1,并 被压入到栈中,A 方法又调用了 B 方法,于是产生栈帧 F2 也被压入栈,执行完毕后,先弹出 F2 栈帧,再弹出 F1 栈帧,遵循“ 先进后出 ”原则。 光说比较枯燥,我们看一个图来理解一下 Java 栈,如下图所示:
3.Heap
Heap(堆)是JVM的内存数据区。Heap 的管理很复杂,是被所有线程共享的内存区域,在JVM启动时候创建,专门用来保存对象的实例。在Heap 中分配一定的内存来保存对象实例,实际上也只是保存对象实例的属性值,属性的类型和对象本身的类型标记等,并不保存对象的方法(以帧栈的形式保存在Stack中),在Heap 中分配一定的内存保存对象实例。而对象实例在Heap 中分配好以后,需要在Stack中保存一个4字节的Heap 内存地址,用来定位该对象实例在Heap 中的位置,便于找到该对象实例,是垃圾回收的主要场所。java堆处于物理不连续的内存空间中,只要逻辑上连续即可。
4.Method Area
Object Class Data(加载类的类定义数据) 是存储在方法区的。除此之外, 常量 、 静态变量 、JIT(即时编译器)编译后的代码也都在方法区。正因为方法区所存储的数据与堆有一种类比关系,所以它还被称为 Non-Heap。方法区也可以是内存不连续的区域组成的,并且可设置为固定大小,也可以设置为可扩展的,这点与堆一样。
垃圾回收在这个区域会比较少出现,这个区域内存回收的目的主要针对常量池的回收和类的卸载。
5.运行时常量池(Runtime Constant Pool)
方法区内部有一个非常重要的区域,叫做 运行时常量池(Runtime Constant Pool,简称 RCP) 。在字节码文件(Class文件)中,除了有类的版本、字段、方法、接口等先关信息描述外,还有常量池(Constant Pool Table)信息,用于存储编译器产生的字面量和符号引用。这部分内容在类被加载后,都会存储到方法区中的RCP。值得注意的是,运行时产生的新常量也可以被放入常量池中,比如 String 类中的 intern() 方法产生的常量。
常量池就是这个类型用到的常量的一个有序集合。包括 直接常量(基本类型,String) 和 对其他类型、方法、字段的符号引用.例如:
◆类和接口的全限定名;
◆字段的名称和描述符;
◆方法和名称和描述符。
池中的数据和数组一样通过索引访问。由于常量池包含了一个类型所有的对其他类型、方法、字段的符号引用,所以常量池在Java的动态链接中起了核心作用.
很有用且重要关于常量池的扩展:Java常量池详解 http://www.cnblogs.com/DreamSea/archive/2011/11/20/2256396.html
6.Native Method Stack
与VM Strack相似,VM Strack为JVM提供执行JAVA方法的服务,Native Method Stack则为JVM提供使用native 方法的服务。
7.直接内存区
直接内存区并不是 JVM 管理的内存区域的一部分,而是其之外的。该区域也会在 Java 开发中使用到,并且存在导致内存溢出的隐患。如果你对 NIO 有所了解,可能会知道 NIO 是可以使用 Native Methods 来使用直接内存区的。
小结:
- 在此,你对JVM的内存区域有了一定的理解,JVM内存区域可以分为线程共享和非线程共享两部分,线程共享的有堆和方法区,非线程共享的有虚拟机栈,本地方法栈和程序计数器。
8.JVM运行原理 例子
以上都是纯理论,我们举个例子来说明 JVM 的运行原理,我们来写一个简单的类,代码如下:
1 public class JVMShowcase { 2 //静态类常量, 3 public final static String ClASS_CONST = "I'm a Const"; 4 //私有实例变量 5 private int instanceVar=15; 6 public static void main(String[] args) { 7 //调用静态方法 8 runStaticMethod(); 9 //调用非静态方法 10 JVMShowcase showcase=new JVMShowcase(); 11 showcase.runNonStaticMethod(100); 12 } 13 //常规静态方法 14 public static String runStaticMethod(){ 15 return ClASS_CONST; 16 } 17 //非静态方法 18 public int runNonStaticMethod(int parameter){ 19 int methodVar=this.instanceVar * parameter; 20 return methodVar; 21 } 22 }
这个类没有任何意义,不用猜测这个类是做什么用,只是写一个比较典型的类,然后我们来看
看 JVM 是如何运行的,也就是输入 java JVMShow 后,我们来看 JVM 是如何处理的:
第 1 步 、 向操作系统申请空闲内存。 JVM 对操作系统说“给我 64M(随便模拟数据,并不是真实数据) 空闲内存”,于是,JVM 向操作系统申请空闲内存作系统就查找自己的内存分配表,找了段 64M 的内存写上“Java 占用”标签,然后把内存段的起始地址和终止地址给 JVM,JVM 准备加载类文件。
第 2 步, 分配内存内存。 JVM 分配内存。JVM 获得到 64M 内存,就开始得瑟了,首先给 heap 分个内存,然后给栈内存也分配好。
第 3 步, 文件检查和分析class 文件。 若发现有错误即返回错误。
第 4 步, 加载类。 加载类。由于没有指定加载器,JVM 默认使用 bootstrap 加载器,就把 rt.jar 下的所有类都加载到了堆类存的Method Area,JVMShow 也被加载到内存中。我们来看看Method Area区域,如下图:( 这时候包含了 main 方法和 runStaticMethod方法的符号引用,因为它们都是静态方法,在类加载的时候就会加载 )
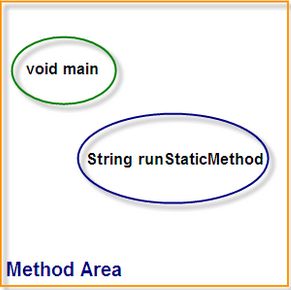
Heap 是空,Stack 是空,因为还没有对象的新建和线程被执行。
第 5 步、 执行方法。 执行 main 方法。执行启动一个线程,开始执行 main 方法,在 main 执行完毕前,方法区如下图所示:
( public final static String ClASS_CONST = "I'm a Const"; )
在 Method Area 加入了 CLASS_CONST 常量,它是在第一次被访问时产生的(runStaticMethod方法内部)。
堆内存中有两个对象 object 和 showcase 对象,如下图所示:(执行了JVMShowcase showcase=new JVMShowcase(); )
为什么会有 Object 对象呢?是因为它是 JVMShowcase 的父类, JVM 是先初始化父类 ,然后再初始化子类,甭管有多少个父类都初始化。
在栈内存中有三个栈帧,如下图所示:
于此同时,还创建了一个程序计数器指向下一条要执行的语句。
第 6 步, 释放内存。释放内存。运行结束,JVM 向操作系统发送消息,说“内存用完了,我还给你”,运行结束。
--------------------------------------------------------------------------------------------
现在来看JVM内存是如何分配的,该部分转载来自 http://blog.csdn.net/shimiso/article/details/8595564
预备知识:
1. 一个Java文件,只要有main入口方法,我们就认为这是一个Java程序,可以单独编译运行。
2. 无论是普通类型的变量还是引用类型的变量(俗称实例),都可以作为局部变量,他们都可以出现在栈中。只不过普通类型的变量在栈中直接保存它所对应的值,而引用类型的变量保存的是一个指向堆区的指针,通过这个指针,就可以找到这个实例在堆区对应的对象。因此,普通类型变量只在栈区占用一块内存,而引用类型变量要在栈区和堆区各占一块内存。
示例:(以下所有实例中,是根据需要对于栈内存中的帧栈简化成了只有局部变量表,实际上由上面对帧栈的介绍知道不仅仅只有这些信息,同理堆内存也一样)
1. JVM自动寻找main方法,执行第一句代码,创建一个Test类的实例,在栈中分配一块内存,存放一个指向堆区对象的指针110925。
2. 创建一个int型的变量date,由于是基本类型,直接在栈中存放date对应的值9。
3. 创建两个BirthDate类的实例d1、d2,在栈中分别存放了对应的指针指向各自的对象。他们在实例化时调用了有参数的构造方法,因此对象中有自定义初始值。
调用test对象的change1方法,并且以date为参数。JVM读到这段代码时,检测到i是局部变量,因此会把i放在栈中,并且把date的值赋给i。
把1234赋给i。很简单的一步。
change1方法执行完毕,立即释放局部变量i所占用的栈空间。
调用test对象的change2方法,以实例d1为参数。JVM检测到change2方法中的b参数为局部变量,立即加入到栈中,由于是引用类型的变量,所以b中保存的是d1中的指针,此时b和d1指向同一个堆中的对象。在b和d1之间传递是指针。
change2方法中又实例化了一个BirthDate对象,并且赋给b。在内部执行过程是:在堆区new了一个对象,并且把该对象的指针保存在栈中的b对应空间,此时实例b不再指向实例d1所指向的对象,但是实例d1所指向的对象并无变化,这样无法对d1造成任何影响。
change2方法执行完毕,立即释放局部引用变量b所占的栈空间,注意只是释放了栈空间,堆空间要等待自动回收。
调用test实例的change3方法,以实例d2为参数。同理,JVM会在栈中为局部引用变量b分配空间,并且把d2中的指针存放在b中,此时d2和b指向同一个对象。再调用实例b的setDay方法,其实就是调用d2指向的对象的setDay方法。
调用实例b的setDay方法会影响d2,因为二者指向的是同一个对象。
change3方法执行完毕,立即释放局部引用变量b。
以上就是Java程序运行时内存分配的大致情况。其实也没什么,掌握了思想就很简单了。无非就是两种类型的变量:基本类型和引用类型。二者作为局部变量,都放在栈中,基本类型直接在栈中保存值,引用类型只保存一个指向堆区的指针,真正的对象在堆里。作为参数时基本类型就直接传值,引用类型传指针。
小结:
1. 分清什么是实例什么是对象。Class a= new Class();此时a叫实例,而不能说a是对象。实例在栈中,对象在堆中,操作实例实际上是通过实例的指针间接操作对象。多个实例可以指向同一个对象。
2. 栈中的数据和堆中的数据销毁并不是同步的。方法一旦结束,栈中的局部变量立即销毁,但是堆中对象不一定销毁。因为可能有其他变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁,而且还不是马上销毁,要等垃圾回收扫描时才可以被销毁。
3. 以上的栈、堆、代码段、数据段等等都是相对于应用程序而言的。每一个应用程序都对应唯一的一个JVM实例,每一个JVM实例都有自己的内存区域,互不影响。并且这些内存区域是所有线程共享的。这里提到的栈和堆都是整体上的概念,这些堆栈还可以细分。
4. 类的成员变量在不同对象中各不相同,都有自己的存储空间(成员变量在堆中的对象中)。而类的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。