编程珠玑_第二章_啊哈 算法
三个问题:
一、给出一个顺序文件,它最多包含40亿个随机排列的32位整数。
问题:找出一个不在文件中的32位整数。
注意:题目中没有说,这40亿个数是否是含有重复的数据
条件限制:
1、如果有足够的内存,如何处理?
2、如果内存仅有上百字节(内存不足)且 可以用若干外部临时文件,如何处理?
二、类似字符串循环移位
举例:比如abcdef 左移三位,则变成defabc
条件限制:空间限制:可用内存为几十字节
时间限制:花费时间与n成比例
三、给出一个英语字典,找出所有变位词集。
举例:abc 的变位词为:abc acb bca bac cba cab
~~~~~~~~~~~~~~~~~~分界线~~~~~~~~~~~~~~~~~~~~
一、给出一个顺序文件,它最多包含40亿个随机排列的32位整数
问题:找出一个不在文件中的32位整数。
条件限制:
1、如果有足够的内存,如何处理?
2、如果内存仅有上百字节(内存不足)且 可以用若干外部临时文件,如何处理?
思路:由于2^32 = 4 294 967 296个数据,超过给出的40亿,所以肯定有数据不在文件中。
1、如果给出的内存是没有限制的
思想:我们可以使用位图法,寻找不在文件的数
申请的空间为(2^32)/8 = 最大数/一个字节可以表示8位 = 2^29B = 2^9MB = 512MB内存
之后,使用位图法。此时出现次数为0的数据为缺失的整数
2、如果内存仅有上百字节(内存不足)且 可以用若干外部临时文件,如何处理?
思想:类似二分查找。可以根据某一位(操作时,可以从最高位 到 最低位依次处理),把待处理的数据分成两部分。在一部分中,此位为0,另一部分此位为1。
之后,分别统计落在两个部分的数的个数。(此时我们不考虑数据是否重复)
如果,没有缺失,那么这两部分数的个数应该是相等的。
如果,数据有缺失,那么两部分数可能相等,也可能不等
两部分相等的情况:两段都缺失,但缺失的个数相等
两部分不等的情况:一个缺一个不缺 或 都缺但缺的个数不同
基于此,把数据分成两部分后,我们可以去数据量小的那个部分寻找缺失的数。如果两个部分的数相等,我们可以随意选择一个部分寻找缺失的数据。此时,可以递归的处理紧挨着的下一位。直到遍历完所有的位后,就可以找到一个缺失的数。
#include <iostream>
#include <assert.h>
using namespace std;
int FindLostNum(int arr[],int len,int maxBits)
{
assert(arr && len && maxBits && len != (unsigned long)(1 << maxBits));
int lostNum = 0;
int checkNum = 0;
int locZero = 0;
int locOne = 0;
int* arrZero = new int[len];
int* arrOne = new int[len];
for (int bit = maxBits - 1;bit >= 0;bit--)
{
locZero = 0;
locOne = 0;
checkNum = 1 << bit;
for (int i = 0;i < len;i++)
{
if (arr[i] & checkNum)//条件成立,该位为1
{
arrOne[locOne++] = arr[i];
}
else
{
arrZero[locZero++] = arr[i];
}
}
if (locOne > locZero)//该bit位上是1的总数 大于 是0的总数
{
arr = arrZero;
len = locZero;
}
else
{
lostNum += checkNum;
arr = arrOne;
len = locOne;
}
}
return lostNum;
}
int main()
{
/*int len = 10;
int maxBits = 4;
int arr[10] = {1,2,3,4,5,6,7,9,0};*/
/*int len = 1;
int maxBits = 1;
int arr[10] = {1};*/
int len = 15;
int maxBits = 4;
int arr[15] = {0,1,2,3,4,5,6,7,9,10,11,13,14,15};
int lostNum = FindLostNum(arr,len,maxBits);
cout<<lostNum<<endl;
system("pause");
}
时间复杂度为:由于每次处理的部分都近似是上次的一办,累加在一起可得O(n)
二、类似字符串循环移位
举例:比如abcdef 左移三位,则变成defabc
条件限制:空间限制:可用内存为几十字节
时间限制:花费时间与n成比例
方法一、求逆
直观的想法:先局部翻转,在整体翻转
字符串abcdefgh -> defghabc 需要三步: reverse(0,i-1); //cba defgh reverse(i,n-1); //cba hgfed reverse(0,n-1); //defghabc
代码:
#include <iostream>
#include <assert.h>
#include <sstream>
using namespace std;
void Reverse(char* str,int start,int end)
{
assert(str != NULL);
char tmp;
int mid = (start + end)/2;
for (int i = start,j = end;i <= mid;i++,j--)
{
tmp = str[i];
str[i] = str[j];
str[j] = tmp;
}
}
/*把字符串循环左移k位*/
void LeftRotateString(char* str,int k)
{
assert(str != NULL && k > 0);
int strLen = strlen(str);
Reverse(str,0,k-1);
Reverse(str,k,strLen-1);
Reverse(str,0,strLen-1);
}
int main()
{
char str[81] = "abcde";
//char str[81] = "abcdef";
LeftRotateString(str,3);
cout<<str<<endl;
system("pause");
return 1;
}
方法二、杂耍算法
举例:原串:0123456789 结果:3456789012
直观的想法:由于要对数组整体向左循环移动k位,那么我们就可以对数组中的每一个元素向左移动k位(超过数组长度的可以取模回到数组中),此时总是能获得结果的。
步骤:(k表示循环移动的位数)
1)先将x[0]移到临时变量t中
2)将x[k]移动到x[0]中,x[2k]移动到x[k]中,依次类推
3)将x中的所有下标都对n取模,直到我们又回到从x[0]中提取元素。不过这时我们从t中提取元素,结束。
循环的终止条件:当我们要从循环的起始位置点中提取元素时,此次循环结束
由于k,2k...之间的偏移量是相同的,所以整个操作实际上就是讲序列向左移动k个位置
注意:从下标0开始,按照上述步骤移动位置时,一次循环并不一定能够把所有数移到目标位置。这还与n和k是否互质有关
如果,n与k互质,从0开始,每一个元素向前移动k个位置,一次循环就可以处理完所有元素,最后一个元素会从0位置取元素
如果,n与k不互质,仅仅从0开始,每次向前移动k个位置。终止时是不能把所有元素放到目的地的。这是要需要进行gcd(n,k)次循环。即第一次是从0开始,每次向前移动k个位置,直至循环结束。第二次是从1开始,每次向前移动k个位置,直至循环结束。第三次...直到第gcd(n,k)-1次。而且每次循环的最后一个元素都会回到该循环的起点
我们这里把包含gcd(n,k)的元素称为一段,可以看出程序需要进行gcd(n,k)循环才能够把所有数移到目标位置
代码:
#include <iostream>
#include <assert.h>
#include <sstream>
using namespace std;
/*获取m和n的最大公约数*/
int gcd(int m,int n)
{
int tmp;
if (m < n)
{
tmp = m;
m = n;
n = tmp;
}
if (m % n == 0)
{
return n;
}
else
{
return gcd(n,m%n);
}
}
//*把字符串循环左移k位*/
void LeftRotateString(char* str,int k)
{
assert(str != NULL && k > 0);
int strLen = strlen(str);
int gcdNum = gcd(strLen,k);
for (int i = 0;i < gcdNum;i++)
{
int first = i;
int next = (first + k) % strLen;
char tmp = str[i];//每段的起始位置,注意不能写成0
while(next != i)
{
str[first] = str[next];
first = next;
next = (first + k) % strLen;
}
str[first] = tmp;//临时变量中存储每一趟的循环的最后一个字符
}
}
int main()
{
//char str[81] = "abcde";
char str[81] = "abcdef";
LeftRotateString(str,3);
cout<<str<<endl;
system("pause");
return 1;
}
参考:http://www.cnblogs.com/solidblog/archive/2012/07/15/2592009.html
http://www.cnblogs.com/HappyAngel/archive/2011/01/16/1936905.html
方法三、块变换
直观的想法:
举例:原串:0123456789 结果:3456789012
观察结果,直接的想法,我们能不能直接把待移动的串直接后面(0123456789 -- 7893456012)
此时,012是正确的位置了,但是其他元素还需调整。
但是我们可以看到,把7893456变成3456789也需要向左循环移3位,这和第一步的变化是一样的,可以用递归做。
原理:我们将待旋转的向量x看成是由向量a和b组成的,那么旋转向量x实际上就是将向量ab的两个部分交换为向量ba
步骤:假设a比b短(谁长,谁分成两部分)
1)将b分割为bl和br两个部分,使得br的长度和a的长度一样
2)交换a和br,即ablbr转换成了brbla。通过本次变换,序列a就位于它的最终位置了。
3)我们需要集中精力交换b的两个部分了,这个时候就回到了最初的问题上了,我们可以递归地处理b部分。
举例:待旋转字符串"0123456789",向左移动3位

程序:
#include <iostream>
#include <assert.h>
using namespace std;
/*
函数作用:把两块数据互换
arr:待翻转的字符串
aStart:第一块内容的起始位置
bStart:第二块内容的起始位置
len:交换的长度
*/
void swap(char* arr,int aStart,int bStart,int len)
{
assert(arr != NULL && aStart >= 0 && bStart >= 0 && len > 0);
char tmp;
while(len-- > 0)
{
tmp = arr[aStart];
arr[aStart] = arr[bStart];
arr[bStart] = tmp;
aStart++;
bStart++;
}
//cout<<arr<<endl;
}
//待旋转字符串的起始位置start,长度len,向左移动的位数bits
void Rotate(char* str,int Start,int len,int bits)
{
//根据移动的位数,把待旋转字符串分成两部分
//左半部分
int leftStart = Start;
int leftLen = bits;
//右半部分
int rightStart = Start + bits;
int rightLen = len - bits;
//待旋转字符串长度为1时,直接结束
if (1 == len)
{
return;
}
//旋转字符串
if (leftLen > rightLen)
{
swap(str,leftStart,leftStart + leftLen,rightLen);
Rotate(str,leftStart + rightLen,len - rightLen,len - 2 * rightLen);
}
else
{
swap(str,leftStart,leftStart + len - leftLen,leftLen);
Rotate(str,leftStart,len - leftLen,leftLen);
}
}
void LeftRotateString(char* str,int k)
{
Rotate(str,0,strlen(str),k);
}
int main()
{
char str[81] = "abcdefghij";
LeftRotateString(str,3);
cout<<str<<endl;
/*char str[81] = "abcdefghij";
LeftRotateString(str,7);
cout<<str<<endl;*/
system("pause");
return 1;
}
书中给出的三种方法的效率分析:
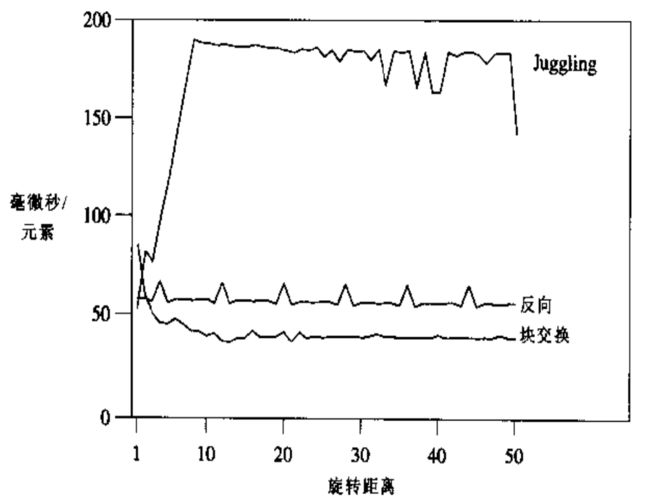
从这个图中,我们可以看出:
反向(即求逆算法)的运行时间比较一致。
块交换算法在执行短距离变换的时候开销很大(可能是由于交换单个元素块的函数调用引起的)。但他具有良好的高速缓存性能
这使得当旋转距离大于2时,他具有最快的执行效率。
Juggling算法(杂耍算法)的高速缓存性能很差,在三个算法中效率最差。
基于分析,虽然求逆算法需要遍历数组两遍,块交换和杂耍算法只需要遍历一遍,但是杂耍算法有求素数,还是块交换的效率高。但是从实际编码上的难度上,还是使用求逆比较划算。
三、给出一个英语字典,找出所有变位词集。
举例:abc 的变位词为:abc acb bca bac cba cab
思想:
1、为每一个单词生成一个标签,并使所有的变位词有相同的标签
2、根据标签收集单词,每一个标签对应一个集合,这个集合包括其所有的变位词
每个单词标签的生成:把这个单词所包含的字母,按照字母顺序排列。这样,所有变位词的标签就全相等了。
#include <iostream>
#include <fstream>
#include <string>
#include <map>
#include <vector>
#include <algorithm>
using namespace std;
void GenAnagram(string word,map<string,vector<string>>& anagramSet)
{
string key = word;
sort(key.begin(),key.end());
anagramSet[key].push_back(word);
}
int main()
{
string str;
map<string,vector<string>> anagramSet;
vector<string>::iterator itVec;
map<string,vector<string>>::iterator itMap;
fstream in("Dic.txt");
while(in >> str)
{
GenAnagram(str,anagramSet);
}
//输出
for (itMap = anagramSet.begin();itMap != anagramSet.end();itMap++)
{
cout<<itMap -> first<<" ";
for (itVec = itMap->second.begin();itVec != itMap->second.end();itVec++)
{
cout<<*itVec<<" ";
}
cout<<endl;
}
in.close();
system("pause");
return 1;
}
问题5、向量旋转函数将向量ab更改为ba,那你应该如何将abc转换为cba?
方法:把abc三部分分别翻转,之后对整体翻转
一个面试题:输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。句子中单词以空格符隔开。为简单起见,标点符号和普通字母一样处理。
方法:先分别对各个单词进行逆转,然后对整个句子进行逆转。
问题6、类似手机键盘,每个数字对应几个字母。按下数字键,就意味着多个字符组合,有关这些字符组合的姓名和手机号就找到。问题,如何实现一个以名字的按键编码为参数,并返回所有可能的匹配名字的函数
方法:把名字对应的数字按键形成一个唯一的标识符,值存入数字键对应的名字map<int,map<string> > rec;
问题8、给定一个n元实数集合,一个实数t和一个整数k,如何快速确定是否存在一个k元子集,使其元素之和不超过t?
方法:构建一个最小堆,取其前k个最小的数。 如果用topk的思路,那么应该更加快速,构建一个k个元素的最大堆来获得k个最小的元素。
参考http://www.cnblogs.com/solidblog/archive/2012/07/18/2596683.html