Recurrent Neural Network Language Modeling Toolkit by Tomas Mikolov使用示例
Recurrent Neural Network Language Modeling Toolkit代码学习
递归神经网络语言模型工具地址:http://www.fit.vutbr.cz/~imikolov/rnnlm/
1. 工具的简单使用
工具为:rnnlm-0.3e
step1. 文件解压,解压后的文件为:
图1.rnnlm-0.3e解压后的文件
step2. 编译工具
命令:
make clean
make
可能报错 说这个x86_64-linux-g++-4.6 命令找不到
如果出现上述错误,简单的将makefile文件的第一行CC = x86_64-linux-g++-4.6 改为 CC = g++
编译后,有如下新文件生成
图2. 编译完后,有rmmlm可执行文件生成
step3. 执行rnnlm
example.sh文件中有执行的命令,在此简单的拷贝出来执行,看看效果。
图3. 执行的rnn的命令
执行命令后的输出:
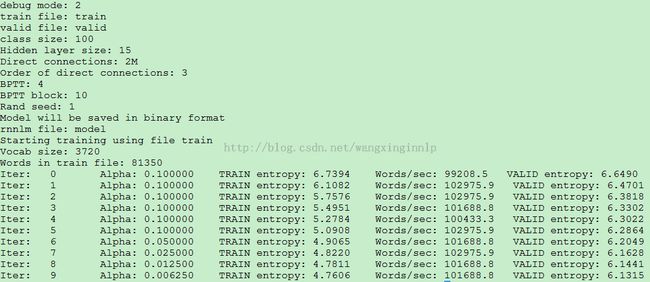
图4. 执行rnnlm后的输出
输出中有一堆参数,目前不清楚这些参数有什么用,以后弄清楚了再补上。
至此,rnnlm运行完毕,模型文件也有生成。如下图:

图5. rnn模型文件
model是训练出rnnlm的参数文件,model.output.txt是模型在验证集(valid dataset)上的表现。
**工具包中自带的train valid test数据分别包含10000, 999, 1000个英语句子。语料规模很小。
step4. 使用训练好的模型对测试集test进行测试
命令./rnnlm -rnnlm model -test test
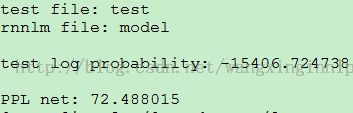
图6. 训练好的模型在测试集上的性能
后面的是将rnnlm和普通的n-gram进行对比
step5. 训练普通的n-gram model[此处的srilm工具需要自己安装]
命令:ngram-count -text train -order 5 -lm templm -kndiscount -interpolate -gt3min 1 -gt4min 1
图7. 训练出的名为templm的5元n-gram model
step6. 使用训练出的templm对test进行测试
命令:ngram -lm templm -order 5 -ppl test -debug 2 > temp.ppl
测试完毕后,当面目录下有temp.ppl文件生成。temp.ppl文件记录templm在test上的表现
![]()
图8. temp.ppl文件最后2行。
**example还有convert的命令:
gcc convert.c -O2 -o convert
./convert <temp.ppl >srilm.txt
后面step9的执行需要此步骤中的srilm.txt文件
**关于convert.cc文件,其源文件中对其功能有简单说明:this simple program converts srilm output obtained in -debug 2 test mode to raw per-word probabilities。
[在工具包给定的语料实验中,对比rnnlm和n-gram模型的模型大小,模型在test上的表现,此处应有几点结论。]
step7. 对rnlm和n-gram进行加权使用
命令:./rnnlm -rnnlm model -test test -lm-prob srilm.txt -lambda 0.5
加权后模型在test的表现如下图:
关于RNNLM的使用,至此,剧终.....
2.自己实验语料上的表现:
语料统计
| 语料 | train | valid | test |
| 句数 | 2500000 | 250000 | 184985 |
| 词数 | 7030251 8 | 9113721 | 6993456 |
程序运行中.......
程序运行时间对比:
n-gram:199.66 user 3.84 system 3:24.84 elapsed 99%CPU
rnn:17667.22 user 4.05 system 4:54:39 elapsed 99%CPU
模型大小对比:
n-gram: 1.7G
rnn:50M(隐层大小设为30)
实验结果:
1. RNN
2. N-gram
![]()
测试句子的测试信息(@ancle_song):
3. RNN+N-gram 权值参数设为0.5
