第四章:BIRT数据集和参数的建立
第四章:BIRT数据集和参数的建立
转载至:http://blog.csdn.net/birtbird/article/details/8480547
4.1 数据集的设置
4.1.1 SQL选择查询数据集
在“新建数据集”对话框,输入数据集名,选择“数据集类型”为“SQL选择查询”,再选择某个JDBC数据源,如下图所示:
图4-1
点击“Next>”进入SQL查询语句的输入界面,如下图所示:
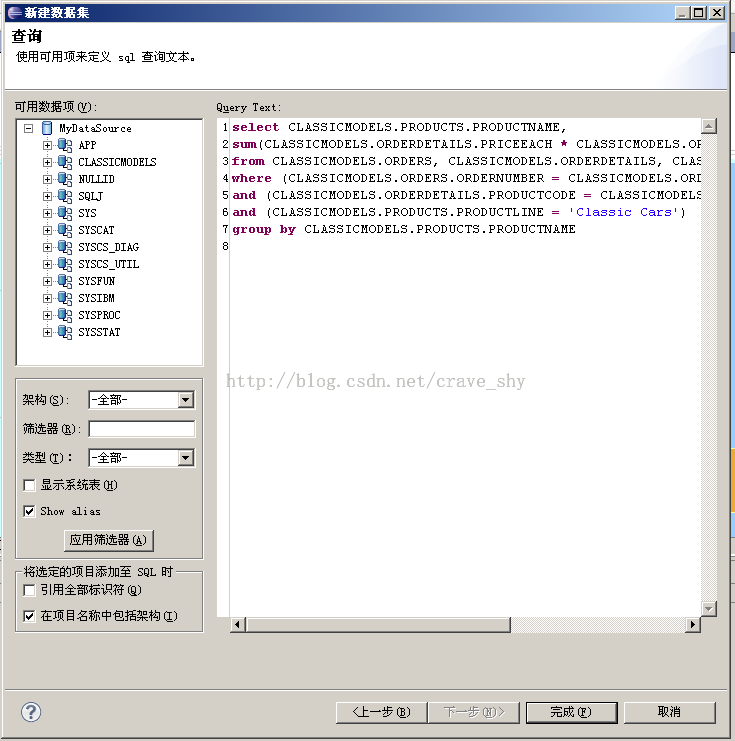
图4-2
各主要参数含义如下:
可用数据项
默认列出从数据库中读出的所有表/视图/存储过程。如果数据库支持架构(Schema),则按Schema进行分组。用户双击某个非根结点,该结点对应的文本将自动添加到右侧的SQL查询语句输入框。
事实上,“可用数据项”中的项如何显示也是可以设置的。点击系统菜单“窗口”->“Preferences”,在打开的对话框的左侧,选择“报表设计”->“数据集编辑器”->“JDBC数据集”结点,如下图所示:
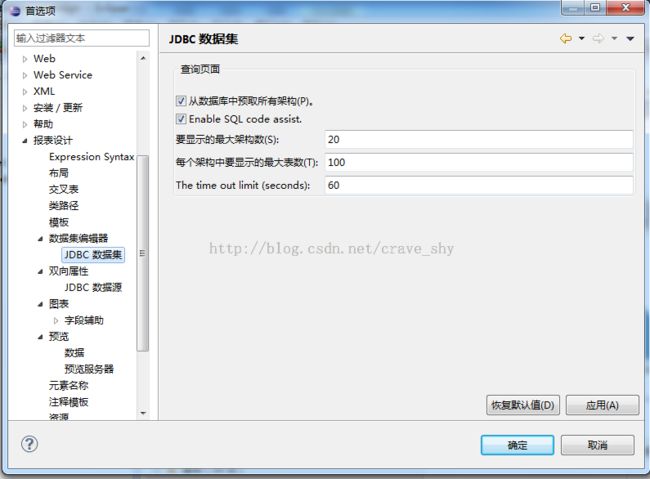
图4-3
JDBC 编辑界面设置
该设置界面中参数的含义如下:
从数据库中预取所有架构:该项设置只对支持Schema的数据库有效。如果选中,“可选数据项”中初始显示从数据库中读出的Schema;如果未选中,“可选数据项”中初始为空,直到用户输入相应过滤条件,点击“应用筛选器”后才显示满足用户条件的项。
要显示的最大架构数:“可选数据项”中最多显示的Schema数目。只对支持Schema的数据库有效。
每个架构中要显示的最大表数:“可选数据项”中每个Schema下最多显示的表数目。如果数据库不支持Schema,则指“可选数据项”中最多显示的表数据。
架构(Schema)
该列表列出从数据库中读出的所有Schema。用户可以选择某个Schema,点击“应用筛选器”,使“可选数据项”只显示指定Schema下的项。
如果数据库不支持Schema,则该列表是无效的(disable)。
筛选器
输入字符串,点击“应用筛选器”,使“可选数据项”只显示其名称起始部分可与用户指定字符串相匹配的表/视图/存储过程。在用户输入的字符串中,“%”代表任意多个字符(Character),“_”代表任何一个字符。
类型
有“-全部-”/“表”/“视图”/“存储过程”四个选项。用户可选择一个选项,点击“应用筛选器”,使“可选数据项”只显示指定类型的项。
使用标志符引用
如果选中,则双击“可选数据项”中某个非根结点时,该结点对应文本的每项的两侧都会被加上某个符号再自动添加到右侧的SQL查询语句输入框。事实上,该符号是从对应JDBC 驱动中读出的(通过java.sql.DataBaseMetaData接口的getIdentifierQuoteString()方法)。如双击“可选数据项”内的“Products”结点,则添加到右侧SQL查询语句输入框的是:”ROOT”.”PRODUCTS”。
显示系统表
是否在“可选数据项”中显示系统表。点击“应用筛选器”后生效。
在右侧输入框,用户可输入对应JDBC驱动支持的SQL查询语句。
动态配置“SQL选择查询”数据集
对于已创建的“SQL选择查询”数据集,其SQL查询语句以及查询最大执行时间是可以在报表运行时动态配置的。在“编辑数据集”对话框,选择“属性绑定”,如下图所示:
图4-5
各个主要参数如下:
查询文本
用户输入的JavaScript表达式的值在报表运行时动态计算出并被作为该数据集的SQL查询语句。例如图 6中的“查询文本”为:
“select * from ” + params[“tableName”].value
这样,根据报表参数“tableName”的值动态构造SQL查询语句。
查询超时(秒)
用户输入的JavaScript表达式的值在报表运行时动态计算出并作为SQL查询语句的最大执行时间(以秒计)。执行查询时,该值会通过java.sql.Statement的setQueryTimeout( int seconds )方法传递给JDBC驱动。
用户可点击“fx”按钮打开“表达式生成器”对话框来帮助构造JavaScript表达式。
运行带参数的SQL查询语句
如果数据集的SQL查询语句带有参数,如下图 7所示:

图7带参数的SQL查询语句
可按顺序将SQL查询语句中的参数与某个报表参数绑定,以便报表运行时,将报表参数的值赋值给SQL查询语句中对应的参数。
点击图 7左侧“参数”即进入参数绑定列表界面,如图 8所示:
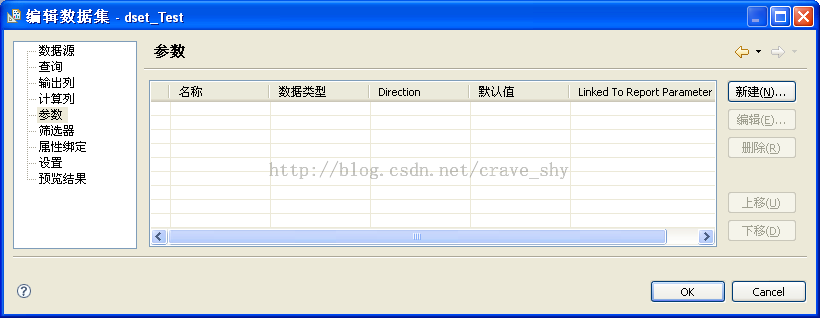
按顺序通过“新建…”将SQL语句中的参数与报表参数绑定或为其提供默认值,如图 9所示:
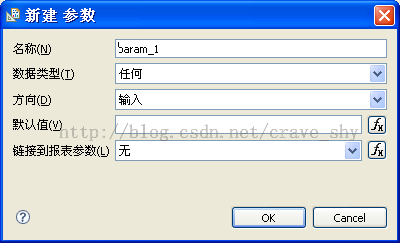
对于某个SQL参数,如果不想让其与某个报表参数绑定,则必须为其提供默认值:在“默认值”中输入JavaScript表达式。
“SQL选择查询”数据集的其它设置
在“编辑数据集”对话框,点击左侧“设置”,进入设置界面,如图 10所示:
图 10 “SQL选择查询”数据集设置界面
各主要参数含义如下:
数据提取设置
设置将SQL查询语句执行结果集中的前多少条记录作为数据集的数据源。事实上,如果用户设置了某个具体值,在查询执行时,该值会通过java.sql.Statement的setMaxRows( int max )方法传递给JDBC驱动。
注意:该项设置不只是在报表设计时有效,在报表运行时依然有效。
Result Set Selection
当SQL执行结果中包含多个结果集(Result Set)时(如“SQL存储过程查询”数据集),此设置用于指定那个结果集作为数据集的数据源。“SQL选择查询”数据集的SQL查询语句执行结果一般为一个结果集,因此无需设置。
添加JDBC驱动搜索路径
由章节“2创建JDBC数据源”知,BIRT中JDBC驱动的默认搜索路径为“\\plugins\org.eclipse.birt.report.data.oda.jdbc_xxx\drivers”目录(其中“xxx”代表版本号)。如果需要,你也可以以API调用方式通过应用程序上下文(AppContext)来添加JDBC驱动搜索路径。相对应的应用程序上下文关键字定义如表 1所示:
| 关键字 |
描述 |
| 由org.eclipse.birt.report.data.oda.jdbc.IConnectionFactory. DRIVER_CLASSPATH定义的常量 |
可以是一个字符串以添加一个路径;也可以是一个java.util.Collection实例以添加多个路径:其中每项的toString()结果表示一个路径。 每个路径是一个jar/zip包或一个目录的绝对路径。表 1与JDBC驱动搜索路径对应的应用程序上下文关键字 |
用户添加的JDBC驱动搜索路径优先于BIRT的默认搜索路径。
另外,我们可以在脚本中动态改变数据集的查询sql,在报表编辑器的脚本编辑区,我们选中beforeOpen下拉框,在里面输入:
var a = reportContext.getParameterValue("kemu");
if(a==1)
{
this.queryText +="and (a.dbtranamt !=0 or a.crtranamt !=0)";
}
if(a==0)
{
this.queryText +="and (a.dbtranamt !=0 or a.crtranamt !=0)";
}
this.queryText+="order by a.trandate asc,a.subctrlcode asc";
图4-11
说明:
reportContext.getParameterValue()代表获取报表参数;
this.queryText代表数据集的查询sql;
4.1.2 多维数据集
新建一个数据集Data Set,基于样本数据源
SELECT CLASSICMODELS.PRODUCTS.PRODUCTLINE, CLASSICMODELS.PRODUCTS.PRODUCTNAME, (CLASSICMODELS.ORDERDETAILS.PRICEEACH * CLASSICMODELS.ORDERDETAILS.QUANTITYORDERED) AS TOTAL FROM CLASSICMODELS.PRODUCTS, CLASSICMODELS.ORDERDETAILS WHERE CLASSICMODELS.PRODUCTS.PRODUCTCODE = CLASSICMODELS.ORDERDETAILS.PRODUCTCODE
新建一个参数pMinDealSize,默认值是8000.00
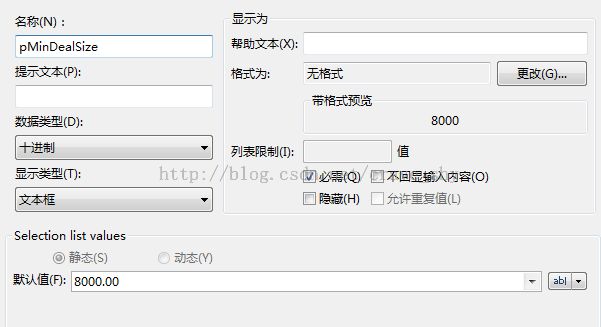
图4-12
设置Data Set,添加过滤器row["TOTAL"] 大于 params["pMinDealSize"].value
图4-13
预览数据:
图4-14
我们以此数据集为基础,创建多维数据集Data Cube:
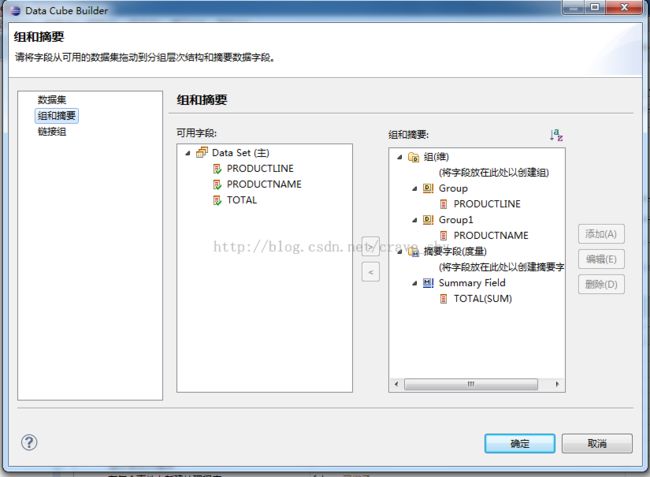
图4-15
分别把productline,productname拖到组中,把total拖到摘要字段中。当然,组和摘要都可以用表达式生成器去编辑,聚合条件也可以编辑。
我们新建一个交叉报表,把productline,productname分别拖入交叉表的行数据字段和列数据字段,把total拖入交叉表的统计字段。

图4-16
在报表查看器中查看,如下图所示的效果:
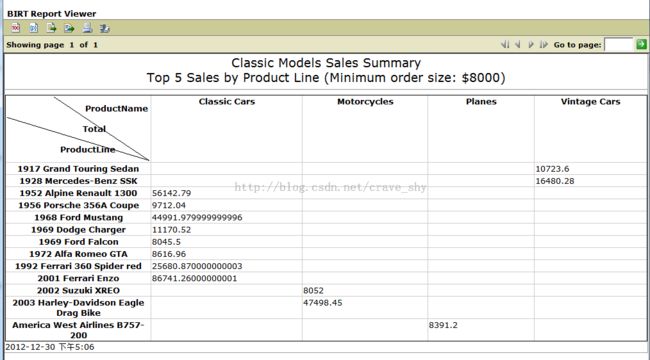
图4-17
至此,多维数据集建立完毕。后文再详细介绍如何建立交叉报表,怎么画斜线,怎么制作多重交叉报表。
4.1.3 联接数据集
BIRT报表中允许用户对已经创建的两个数据集进行联接操作,形成新的数据集,该数据集就称为联接数据集。
由于联结数据集操作是在BIRT报表数据引擎内部执行的,因此它也无法达到数据库的运算效率。因此,在实际运用这个功能时,一定要考虑相关性能问题。我们建议只针对无法避免的情况才使用。比如异构的(即来源于不同类型数据源的)、离线的而且是报表系统无法直接进行编程的数据集之间的联结运算。
在创建联接数据集之前,您需要首先创建了两个数据集,这两个数据集之间需要有一个共同的字段用于联接操作。
打开“数据资源管理器”窗口,右键点击“数据集”,在弹出的菜单中选择“新建联接数据集”。
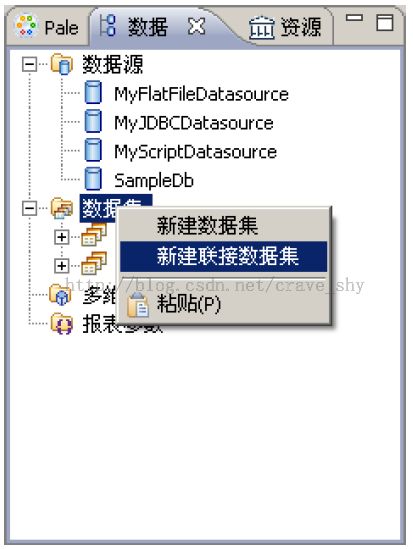
图4-18
在弹出的新建联接数据集窗口中,输入数据集名称。在下拉列表中分别选择进行联接的数据集,并选择联接的依据字段以及联接类型。

图4-19
点击“完成”,在编辑数据集窗口中预览数据结果,或继续编辑数据集。
图4-20