第三章:BIRT数据源的配置
第三章:BIRT数据源的配置
转载至:http://blog.csdn.net/birtbird/article/details/8479824
选择数据资源管理器(Data Explorer)。如果使用缺省报表设计透视图,则数据资源管理器位于布局编辑器的左边,在画板(Palette)的旁边,如图所示。如果它尚未打开,则选择窗口->显示视图->数据资源管理器。
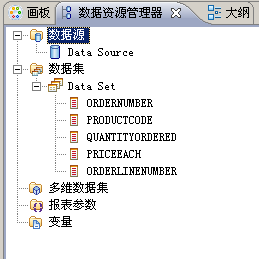
图3-1 数据资源管理器
右键单击Data Sources然后从上下文菜单中选择新建数据源。新建数据源显示可以创建的数据源的类型,如图所示。
图3-2 新建数据源
Classic Models Inc.Sample DataBase ———上面说过是BIRT样本数据库。 Flat File Data Source ———从CSV、SSV、TSV、PSV四种格式的平面文件获取数据源。 JDBC Data Source ——— 通过配置jdbc连接数据库。 Script Data Source ——— 通过编写脚本获取数据源。 Web Services Data Source ——— 通过web service方式获取数据源。 XML Data Source ——— 从xml文件获取数据源。
3.1 JDBC数据源
在数据源上新建数据源,出现如下对话框,
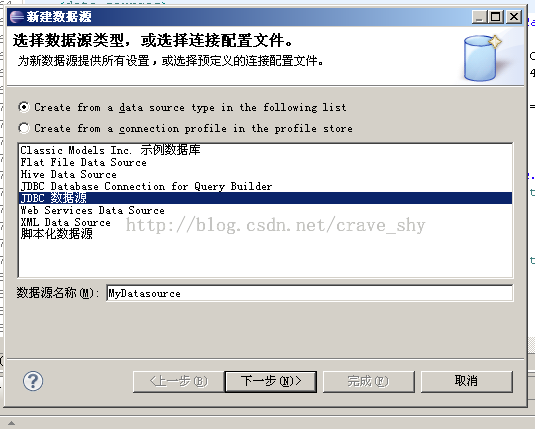
图3-3 新建JDBC数据源
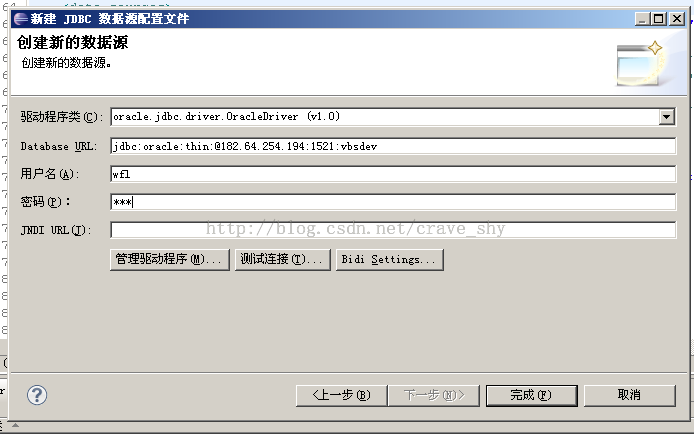
图3-4 配置JDBC数据源
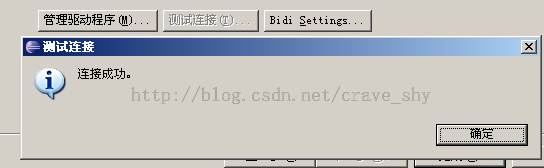
图3-5 测试JDBC数据源
各参数含义如下:
驱动程序类:JDBC 驱动类名。该列表默认会有“org.apache.derby.jdbc.EmbeddedDriver (Apache Derby Embedded Driver)”、“org.eclipse.birt.report.data.oda.sampledb.Driver (Classic Models Inc. 示例数据库驱动程序)”两个选项,分别对应于Derby数据库和BIRT 自带的示例数据库。用户可点击“管理驱动程序…”来添加/删除JDBC 驱动包(jar或zip),该包中的所有JDBC 驱动类类名将被添加到此列表供用户选择。用户添加的JDBC驱动包将被复制到“\\plugins\org.eclipse.birt.report.data.oda.jdbc_xxx\drivers”目录下(其中“xxx”代表版本号)。
驱动程序URL:JDBC连接URL。各JDBC 驱动有其对应的URL格式,可参考具体JDBC 驱动的文档。
用户名:数据库登录名。
密码:数据库登录密码。
JNDI URL:如果JDBC连接信息是以JNDI 数据源的方式配置在部署报表的应用服务器上,此处为应用服务器上该JNDI 数据源的URL。例如,Tomcat上JNDI 数据源的URL格式为“java:/comp/env/jdbc/xxx”(其中“xxx”为JNDI 数据源名)。
注意:如果提供JNDI URL,只在把报表部署到应用服务器后才生效。在设计报表时,使用的<驱动程序类,驱动程序URL,用户名, 密码>组合。
可点击“测试连接…”来测试能否使用输入的<驱动程序类,驱动程序URL,用户名, 密码>与数据库连接成功。
在XML中会出现如下的配置信息:
<oda-data-source extensionID="org.eclipse.birt.report.data.oda.jdbc" name="MyDatasource" id="187"> <text-property name="displayName"></text-property> <property name="odaDriverClass">oracle.jdbc.driver.OracleDriver</property> <property name="odaURL">jdbc:oracle:thin:@182.64.254.194:1521:vbsdev</property> <property name="odaUser">wfl</property> <encrypted-property name="odaPassword" encryptionID="base64">d2Zs</encrypted-property> </oda-data-source> </data-sources>
其中birt designer自带的数据库配置如下图:
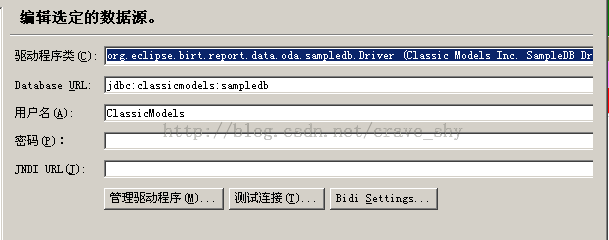
图3-6 示例数据库配置
如果测试连接未通过,除了Database URL可能不对之外,用户名,密码都可能不对。另外,驱动程序找不到也可能导致测试未通过。这个时候需要管理驱动程序。
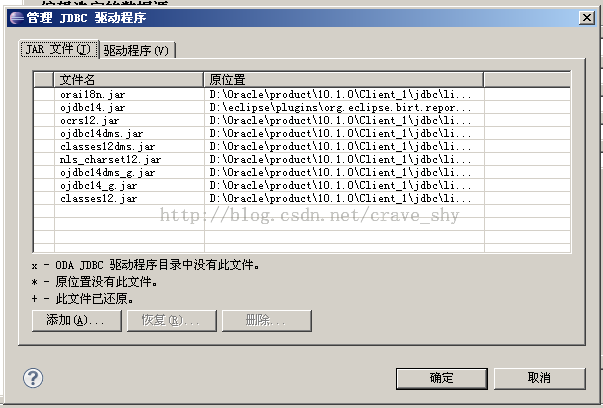
图3-7 oracle数据库JDBC数据库驱动程序管理
各个数据库的Database URL大多不同,
derby的URL:jdbc:derby://【host】:1527/【database】, oracle的URL:jdbc:oracle:thin:@【host】:1521:【database】, mysql的URL:jdbc:mysql://【host】:port/【database】, DB2的URL:jdbc:db2://【host】:port/【database】
其它的数据库连接具体参考各自的说明。
我们在开发报表的时候,是使用jdbc链接数据库的,但为提高报表的运行效率和稳定性,使用连接池进行管理比较好。比较简便和低耦合的解决办法,使用jndi连接池。
jdbc和jndi的区别:
JDBC -最基本的连接数据库的方式, 每次对数据库打交道的时候 ,连接数据库是需要实例下你实现连接数据库的方法或者类。
JNDI DataSource 英文全称是:Java Naming and Directory Interface java 命名接口,当服务启动时 事先把连接数据库的已经连好多条,具体多少条你可以设置,存放在tomcat容器里,用的时候可以直接使用, 不用再实例化得到连接,相对与jdbc效率要快点
在eclipse设计报表的时候,我们使用jdbc链接数据库做测试,当到了tomcat运行环境中切换到jndi连接池,这是比较方便的开发方法。
1.tomcat配置jndi连接池
在 {tomcat目录}\webapps\{项目名}\META-INF 中新增context.xml文件,配置代码如下
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resource
auth="Container"
name="jdbc/travel_agency"
type="javax.sql.DataSource"
maxIdle="5"
maxWait="-1"
driverClassName="com.mysql.jdbc.Driver"
username="itravel"
password="709394"
url="jdbc:mysql://192.168.1.100/travel_agency?useUnicode=true&characterEncoding=UTF-8"
maxActive="10"/>
</Context>
2.在web.xml中加入配置
<resource-ref> <description>Database Source</description> <res-ref-name>jdbc/travel_agency</res-ref-name> <res-type>javax.sql.DataSource</res-type> <res-auth>Container</res-auth> </resource-ref>
3.实例报表中数据源代码
<data-sources> <oda-data-source extensionID="org.eclipse.birt.report.data.oda.jdbc" name="数据源" id="227"> <property name="odaDriverClass">com.mysql.jdbc.Driver</property> <property name="odaURL">jdbc:mysql://192.168.1.100/travel_agency</property> <property name="odaUser">itravel</property> <encrypted-property name="odaPassword" encryptionID="base64">NzA5Mzk0</encrypted-property> <property name="odaJndiName">java:comp/env/jdbc/travel_agency</property> </oda-data-source> </data-sources>
除了第7行 <property name="odaJndiName">java:comp/env/jdbc/travel_agency</property>,其余是我们的之前的配置。用了第7行的代码,表示该报表支持jndi数据源,birt在运行报表的时候,会先用jndi去连接,如果失败了再用jdbc链接,这样做的好处就是,我们在开发报表的时候,没有放到web环境中,可以使用jdbc,当放到tomcat中,因为有了第7行的配置。默认采用jdni连接。
如果是weblogic,一般都事先配置好了JNDI,我们只需要在报表运行的路径下的WEB-INF中添加context.xml,
图3-8 context.xml的位置
内容如下即可
<resource-ref> <description>Database Source</description> <res-ref-name>jdbc/wfl</res-ref-name> <res-type>javax.sql.DataSource</res-type> <res-auth>Container</res-auth> </resource-ref>
然后再配置BIRT数据源的JNDI
图3-9 JNDI数据源的配置
在XML中会出现以下配置信息:
<oda-data-source extensionID="org.eclipse.birt.report.data.oda.jdbc" name="数据源" id="8"> <property name="odaDriverClass">oracle.jdbc.driver.OracleDriver</property> <property name="odaURL">jdbc:oracle:thin:@182.64.254.111:1521:vbsdev</property> <property name="odaUser">wfl</property> <encrypted-property name="odaPassword" encryptionID="base64">d2Zs</encrypted-property> <property name="odaJndiName">java:comp/env/jdbc/wfl</property> </oda-data-source> </data-sources>
连接的顺序:先连接JNDI,如果找不到就连接公共数据源,如果再找不到就连接自定义数据源。
另外一种降低耦合性的方法便是调用平台的配置文件,从配置文件中读取JNDI,URL,DriverClass,User,Password等等信息
birt用脚本javascript创建数据源,并从配置文件中读数据库信息
图3-10 用脚本配置数据源
可以定义一个参数去指定properties文件的路径,然后创建datasource。
在datasource的script中编辑beforeOpen事件,参考下面的代码:
importPackage( Packages.java.io );
importPackage( Packages.java.util );
fin = new java.io.FileInputStream( new String(params["propFile"]) );
props = new java.util.Properties( );
props.load(fin);
extensionProperties.odaURL = new String(props.getProperty("url"));
extensionProperties.odaDriverClass = new String(props.getProperty("driver"));
extensionProperties.odaUser = new String(props.getProperty("userid"));
extensionProperties.odaPassword = new String(props.getProperty("password"));
fin.close();
这样就可以从properties文件中动态读取数据源配置信息。
你可以把配置文件在代码里写死,也可以定义为报表参数,请注意params["propFile"]这里。
这里的代码只支持绝对路径,在deployment的情况下可能不太适用,可以修改一下支持相对路径,相对于你发布的应用根目录。
importPackage( Packages.java.io,Packages.java.util,Packages.java.net );
importPackage( Packages.javax.servlet.http );
req = reportContext.getHttpServletRequest( );
propPath = new String(params["propFile"]);
if ( propPath.charAt(0) != "/" )
propPath = "/" + propPath;
url = req.getSession( ).getServletContext( ).getResource( propPath );
if ( url != null )
{
props = new java.util.Properties( );
props.load( url.openStream( ) );
extensionProperties.odaURL = new String(props.getProperty("url"));
extensionProperties.odaDriverClass = new String(props.getProperty("driver"));
extensionProperties.odaUser = new String(props.getProperty("userid"));
extensionProperties.odaPassword = new String(props.getProperty("password"));
}
说明,下面这一段必须在runtime中测试,否则req = reportContext.getHttpServletRequest( );取值为空,不能获取数据源。
或者还有另外一种写法如下,:
this.setExtensionProperty("odaURL", props.getProperty("url"));
this.setExtensionProperty("odaDriverClass", props.getProperty("driver"));
this.setExtensionProperty("odaUser", props.getProperty("userid"));
this.setExtensionProperty("odaPassword", props.getProperty("password"));
配置后,重新启动,无任何问题,报表生成成功。
3.2 在BIRT中使用存储过程
概述
存储过程和函数都是包含了一系列的SQL语句的集合体。通常来说,存储过程可以用来执行一系列的操作或是调用某些函数去计算一个值。因此,我们可以把存储过程看作是一个无返回值的方法调用,而函数则可以看作是一个有返回值的方法调用。
由于各个关系型数据库对存储过程支持程度的差别,以及输出结果返回方式的不同,用户需要有一个通用的方式来访问存储过程。BIRT(BIRT报表) 提供了一个简单,易用的方式来支持对存储过程数据的获取,方便的让用户将存储过程作为数据源来定制自己的报表。
本文演示了如何使用BIRT 2.3.0创建存储过程数据源。
BIRT支持的存储过程返回值类型
BIRT支持5种类型的存储过程返回值:
单结果集
结果集通常是通过使用SELECT语句选择数据产生的。结果集可以从永久表,临时表或者局部变量中产生。
输出参数
输出参数经常用来从存储过程中检索出的结果。输出参数可以是整型,或是字符型等数据类型。
RETURN参数返回状态
这是一种从存储过程返回错误码的方法。存储过程会返回一个整型的状态值。用户可以使用RETURN语句返回自己的状态。
游标
某些 DBMS允许从存储过程中返回游标的一个引用,JDBC并不支持这个功能,但是Oracle, Postgre SQL和DB2等都支持这种返回类型。我们同样可以通过BIRT来访问这些数据类型。
多数据集
这种结果是指返回结果包含多个结果集或游标。
BIRT调用存储过程的语法
JDBC API 提供了一套存储过程SQL转义语法,该语法允许对所有的关系型数据库使用标准方式调用存储过程。它的调用方式有两种,一种是带有返回值的调用,另一种是不含返回值的调用
{?= call <procedure-name>[<arg1>,<arg2>, ...]}
{call <procedure-name>[<arg1>,<arg2>, ...]}
在BIRT中,所有的对存储过程的调用遵循JDBC3.0规范。所以以上语法适用于BIRT,在这里<arg1>…参数可以用占位符或者是默认值来代替。
创建存储过程数据源/集
创建存储过程数据源的过程如下.
创建一个JDBC的数据源。
当创建数据源时,选择SQL存储过程数据类型。
建立存储过程查询语句。
如图所示:
图3-11 JDBC调用SQL存储过程
在BIRT中使用存储过程
本章讨论如何在BIRT里使用不同类型的存储过程返回结果。
在示例1,2,3中用到的数据库是Sybase数据库,示例中用的的表是Customers表,它记录了所有用户的信息。 由于Sybase不支持游标,所以在示例4,5中,我们将使用到Oracle数据库。在存储过程4中,我们会调用到OFFICES表,通过游标来返回该表的所有信息。在示例5中,我们会调用到CUSTOMERS表。对该表进行若干次的查询定义来返回多个结果集。
调用返回单结果集的存储过程。
示例1:存储过程定义如下:
CREATE PROCEDURE get_All_Customers AS SELECT * FROM Customers GO
该存储过程返回CUSTOMERS表中的所有记录。使用BIRT调用方法如下:
调用语句: { call get_All_Customers () }
下图给出了上述存储过程在BIRT数据集编辑器中的结果:
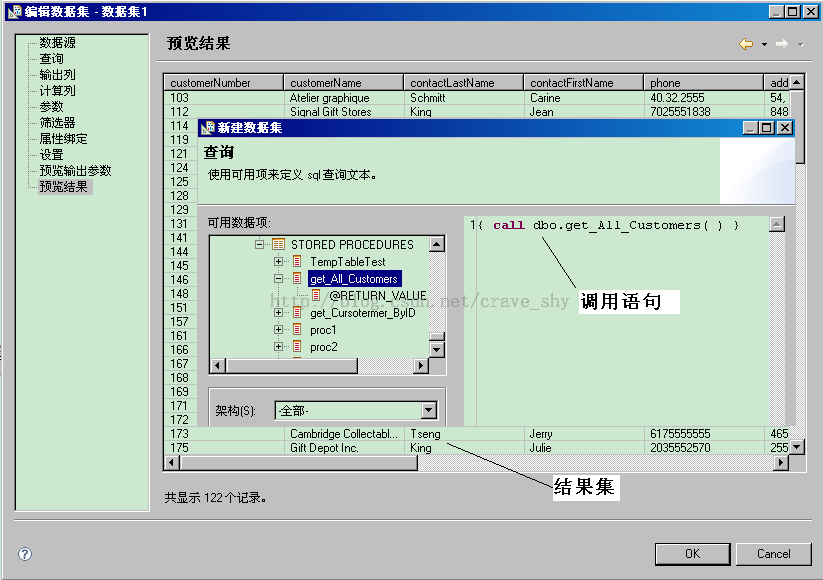
图3-12 JDBC调用SQL存储过程
调用一个含有参数的存储过程,并且有输出参数。
在存储过程中用户通过输入参数,想选择出满足条件的结果集。比如:我们想查找某一ID用户的所有信息。定义的存储过程如下:
CREATE PROCEDURE get_Cursotermer_ByID
(@id int, @name varchar(50) output,@phone varchar(50) output)
AS
SELECT @name=customerName,@phone=phone
FROM Curstomers
WHERE customerNumber =@id
GO
调用语句:{ call get_Cursotermer_ByID (?,?,?)}
图3-13 JDBC调用SQL存储过程
在“参数”项里,我们可以看到BIRT会自动列出来的所有的参数。用户只需填入输入参数的默认值,就可以直接预览结果了。在某些特殊情况下,由于数据库驱动驱动/数据连接的一些内部问题而无法正确获取参数列表,用户也可以手动添加所需用到的参数,也一样可以达到相同效果。
调用含有RETURN参数的存储过程
在2中,我们同样可以得到该存储过程的RETURN参数。
调用语句:{ ?=call dbo.get_Cursotermer_ByID (?,?,?) }, 这里和2中唯一的不同是,在“参数”页面中,可以看到自动增加了一个 “@RETURN_VALUE”的参数,一般情况下,如果用户需要调用函数,则可以通过这种方式获取函数的返回值。
调用返回游标的存储过程
并不是所有的DBMS都支持游标类型。这里我们用ORACLE数据库中的存储过程为例。
在ORACLE中我们创建存储过程实例如下:
CREATE OR REPLACE PAGKAGE TESTPACKAGE AS TYPE TEST_CURSOR IS REF CURSOR; END TESTPACKAGE; CREATE OR REPLACE PROCEDURE TESTLIN2 ( TEST_CUSROR OUT TESTPACKAGE.TEST_CURSOR) AS BEGIN OPEN TEST_CURSOR FOR SELECT * FROM OFFICES; END TESTLIN2
由于JDBC标准中,并没有支持游标这一数据类型,因此,我们对游标类型是以java.sql.Types.Others类型来处理。对于上面的这个存储过程,我们调用过程如图所示:
图3.14调用返回多个结果集的存储过程
存储过程实例如下:
CREATE OR REPLACE PROCEDURE TESTMULTIPLE
(
P_CUSTOMERNUMBER IN NUMBER,
P_CUSTOMERCURSOR1 OUT SYS_REFCURSOR,
P_CUSTOMERCURSOR2 OUT SYS_REFCURSOR,
P_CUSTOMERNAME OUT VARCHAR2,
P_COUNTRY OUT VARCHAR2
)
AS
BEGIN
OPEN P_CUSTOMERCURSOR1 FOR
SELECT * FROM CUSTOMERS
WHERE CUSTOMERNUMBER>P_CUSTOMERNUMBER;
SELECT COUNTRY INTO P_COUNTRY
FROM CUSTOMERS
WHERE CUSTOMERNUMBER=P_CUSTOMERNUMBER;
OPEN P_CUSTOMERCURSOR2 FOR
SELECT * FROM CUSTOMERS;
SELECT CUSTOMERNAME INTO P_CUSTOMERNAME
FROM CUSTOMERS
WHERE CUSTOMERNUMBER=P_CUSTOMERNUMBER;
END;
调用语句为:{ CALL TESTMULTIPLE(?,?,?,?,?) }
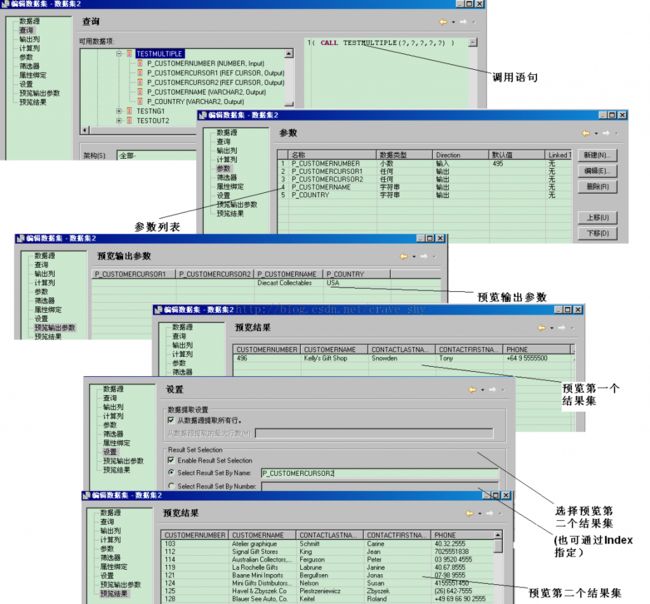
图3-15 JDBC调用SQL存储过程
3.3 XML数据源
3.3.1新建XML文件
1. 自定义XML文件一定要遵循XML1.0的标准和规范.具体信息见:
http://www.w3.org/TR/REC-xml/
2. 新建以后缀名为xml的 文件,名称为XmlSource.
3. XmlSource.xml文件的内容为:
<?xml version="1.0" encoding="utf-8" ?> <root> <user> <name>henry</name> <email>[email protected]</email> </user > <user> <name>john</name> <email>[email protected]</email> </user > </root>
3.3.2新建XML数据源
1. 在birt资源管理器的左上方选择数据源,新建数据源.
2. 选中xml数据源,数据源名称为XmlDataSource.
3. 点击Next,选择xml文件路径.
4. 如图选择XmlSource.xml文件路径:
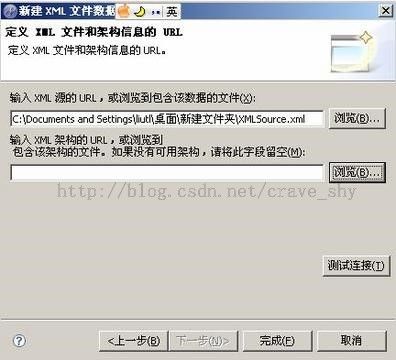
图3-16
5.点击完成.
3.3.3. 新建XML数据集
1. 新建数据集,名称为XmlDataSet,选择刚才新建的数据源XmlDataSource.
2. 点击Next.
3. 在XPath表达式中输入/root/user,如图:
图3-17
4. 点击Next.
5. 映射字段,选择name字段,点击小箭头按钮.
6. 选择name的字段的类型,字符串类型.如图:
图3-18
7. 点击确定,然后把eamil字段也相同映射.
8. 点击完成.
3.3.4 预览效果
1. 把数据集XmlDataSet拖入到报表编辑页面,点击预览,就可看到效果.如图:
图3-19
3.4脚本化数据源
我们新建一个报表application_session_integrationBF.rptdesign,用来把浏览器的参数对封装成脚本数据源在报表中显示出来。
新建数据源-选择脚本数据源,名称为setScript
图3-20
在大纲视图下,我们单击application_session_integrationBF.rptdesign,在报表编辑器的脚本中,我们在beforeFactory下拉款选项中输入以下内容:
图3-21
// Create a hash table which will contain lists of other lists
var topMap = new Packages.java.util.Hashtable();
// Request Attributes
var request = reportContext.getHttpServletRequest();
var requestAttrMap = new Packages.java.util.Hashtable();
var attrNames = request.getAttributeNames();
do {
var aName = attrNames.nextElement();
requestAttrMap.put(aName, request.getAttribute(aName).toString());
} while (attrNames.hasMoreElements())
topMap.put("requestAttributes", requestAttrMap);
// Request Parameters
var requestParamMap = new Packages.java.util.Hashtable();
var paramIter = request.getParameterMap().entrySet().iterator();
do{
var entry = paramIter.next();
requestParamMap.put(entry.getKey(), (entry.getValue()[0]));
} while (paramIter.hasNext())
topMap.put("requestParameters",requestParamMap);
// Session Attributes
var sessionAttrMap = new Packages.java.util.Hashtable();
var session = request.getSession();
// Insert a variable on the session
session.setAttribute("ReportAttribute", "arbitrary value to pass to container");
var sessionAttrNames = session.getAttributeNames();
var i = 0;
do {
i ++;
var aaa = sessionAttrNames.nextElement();
sessionAttrMap.put(aaa, session.getAttribute(aaa));
} while (sessionAttrNames.hasMoreElements())
topMap.put("sessionAttributes", sessionAttrMap);
// Get the system properties
topMap.put("systemProps", Packages.java.lang.System.getProperties());
// Store top map as a global
reportContext.setPersistentGlobalVariable("topMap", topMap);
然后我们新建数据集setEnvironmentVars,选择数据源setScript,在输出列中添加三列
图3-22
报表编辑区的XML编辑区中我们会看到如下内容:
<list-property name="resultSetHints">
<structure>
<property name="position">1</property>
<property name="name">propName</property>
<property name="dataType">string</property>
</structure>
<structure>
<property name="position">2</property>
<property name="name">propValue</property>
<property name="dataType">string</property>
</structure>
<structure>
<property name="position">3</property>
<property name="name">propType</property>
<property name="dataType">string</property>
</structure>
</list-property>
预览以下是没有结果集的,因为我们还没有编写数据集的open和fetch方法,在大纲视图中选中数据集setEnvironmentVars,在报表编辑区的脚本编辑区,我们输入以下内容
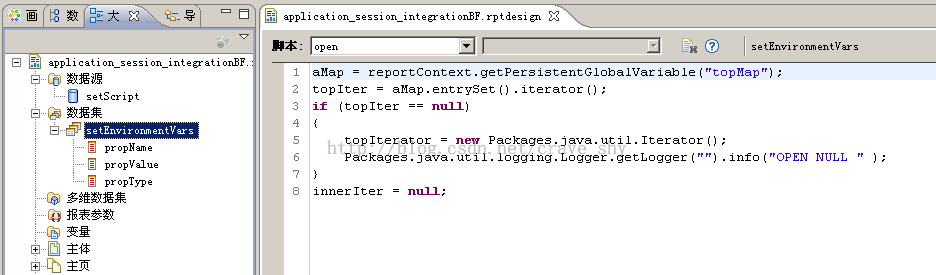
图3-23
aMap = reportContext.getPersistentGlobalVariable("topMap");
topIter = aMap.entrySet().iterator();
if (topIter == null)
{
topIterator = new Packages.java.util.Iterator();
Packages.java.util.logging.Logger.getLogger("").info("OPEN NULL " );
}
innerIter = null;
图3-24
do
{
if (innerIter == null || innerIter.hasNext() == false)
{
if (topIter.hasNext())
{
outerObject = topIter.next();
innerIter = outerObject.getValue().entrySet().iterator();
}
else
{
return false;
}
}
}
while (innerIter.hasNext() == false)
innerObject = innerIter.next();
row["propName"] = innerObject.getKey();
row["propValue"] = innerObject.getValue().toString();
row["propType"] = outerObject.getKey();
return true;
在大纲视图的脚本设计里面我们会看到
图3-25
之后我们可以切换到画板中开始设计报表的布局。
图3-26
添加分组
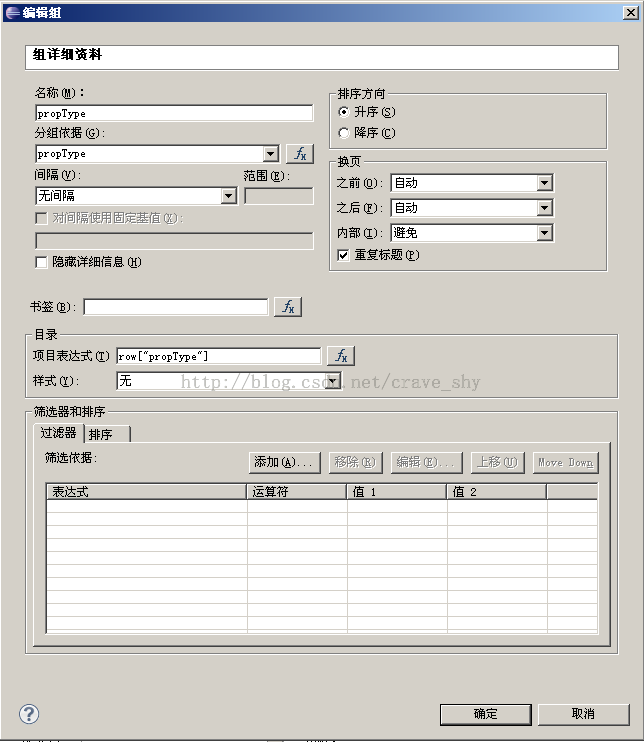
图3-27
设置适当的格式,在web查看器中查看报表,我们可以看到如下的结果
图3-28
更常用的用法是,我们在脚本数据源里调用JavaBean,通过Java的方式来获取数据集,一般是在beforeFactory中创建JavaBean,在open中通过数据库连接绑定JavaBean和数据库值,在fetch中指定row。还可以通过指定事件处理函数来指定外部的数据源类,详细的用法见后文——BIRT的事件处理机制。
图3-29