新瓶装老酒:实时数据集成_模式
面向服务的体系结构(SOA)目前应该是一个很受欢迎的名词,中间件技术人员几乎到了言必称SOA的程度,数据集成当然也不例外,在Oracle openworld2008大会上,就推出了一堆数据集成的专场演讲,其中和SOA结合最紧密的就是实时数据集成real time data integration。我总结了一下,实时数据集成一般分为两个处理过程:一是对数据按照SOA架构的需要进行整合加工形成可用的信息,二是将信息以符合SOA规范的方式发布出去。具体的实时数据集成模式可以按照对这两个处理过程的设计分为以下四种:
1. 在中间件层上进行数据的加工整合,同时通过中间件层的标准接口将整合后的数据以标准接口发布。
2. 数据源层负责数据的加工处理,然后将整合后的数据以标准的接口发布到中间件层,由中间件层负责数据的访问。
3. 将分散在数据层的数据先整合到ODS或者数据仓库中进行整合加工,然后再将加工整理后的数据以标准接口发布到中间件层。
4. 采用数据网格的方式将数据层的数据整合在中间层,形成数据网格,中间件负责数据的加工,整合,然后以标准的方式发布出去。
我们先看第一种模式,数据集成发生在中间件层,数据发布也发生在中间件层,如下图所示:

在中间层上存在一个虚拟的数据服务层,该层通过JDBC,FILE适配器、应用适配器等与数据层的各种数据源实现连接,将数据源中的各种数据实体映射成中间件的虚拟数据层的表,虚拟数据层中的表都只有元数据,而不存储实际的生产数据。用户可以在虚拟数据层上采用可视化图形界面定义数据映射关系,进行数据加工整合,这些数据加工逻辑一般会以文件或者数据库方式存储。定义好的数据可以通过web service,JDBC,数据对象等多种方式发布出去。当用户通过中间件访问虚拟数据层的数据时,虚拟数据层会根据系统定义的逻辑首先将需要加工的细节数据从各个数据源抽取到虚拟数据层,然后中间件根据设计时的数据加工逻辑对其进行加工,最后中间件将加工好的数据以调用接口要求的格式返回。
上回说到采用虚拟数据层的方式进行数据集成,
采用虚拟数据服务层的优势为:
1. 处理都在中间件服务器上,相对来讲,对数据的处理会比较灵活,应用和底层的数据实现松耦合。
2. 当一个请求涉及到多个底层数据源时,对底层的数据访问可以采用并发方式进行。
3. 借助中间件的灵活性,数据可以采用多种方式对外提供接口,从而大大方便各种应用的开发。
4. 所有的数据都是实时从数据源取来,保证数据的时效性。
问题:
数据的处理在中间件层进行,一是带来从数据源到中间件层的数据传输,二是中间件一般都是J2EE架构,其强项并不是数据处理,在数据量不大时并无大碍,当数据量非常大时,其实现机制就注定了效率会出现问题。
第二种模式的实现方法为:数据源层负责数据的加工处理,然后将整合后的数据以标准的接口发布到中间件层,中间件层只负责数据的接入访问,如下图所示:
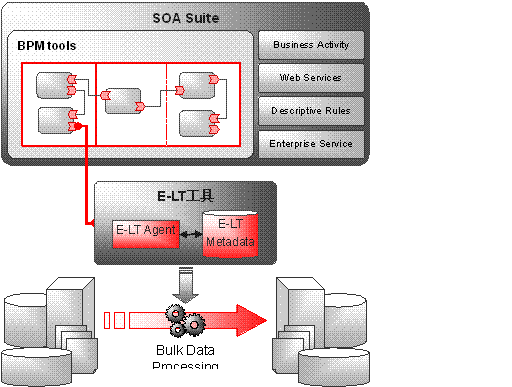
这种处理方式一般是数据库厂商或者ETL厂商推荐的方式,根据用户的业务需求逻辑,首先在数据源层通过ETL工具设计数据转化流程,然后将流程的转化逻辑发布成web服务,同时将转化后的数据也发布成web服务,然后将这些服务注册到中间件层,当前端用户需要数据服务时,它需要调用两个web服务,第一个是转化web服务,该web服务调用相应的ETL工具对数据进行整合加工,然后将整合的数据存储在临时表中。第二个服务是调用数据服务,直接从临时表中取出加工后的数据,与第一种模式的区别在于,它将数据的加工处理放在了数据源层,其优势在于:
1. ETL工具天生就是做数据整合的,而且适合大数据量的整合,所以针对大数据量效率会非常高。
2. 在数据源层整合可以充分利用数据库的处理能力,毕竟数据库才是做数据处理的行家。
3. 依靠E-LT工具的变化数据捕捉功能,可以进行增量数据的处理。
4. 数据转化和数据获取松耦合,可以实现异步处理。
该模式的问题在于:
1. 由于数据的加工处理依赖于数据库的处理能力,因此在所有的数据源中,必须有一个为关系型数据库系统,而第一种模式由中间件负责数据处理,数据源没有限制。
2. 在应用的流程设计中,需要调用两次WEB服务,一次为转化,一次为取数据读取,数据量非常小的情况下,有点画蛇添足的味道。
第三种模式其实是前两种模式的组合,但其数据集成是基于数据仓库的概念发展演化而来,象现在很多企业单位正在建的ODS系统。如下图:
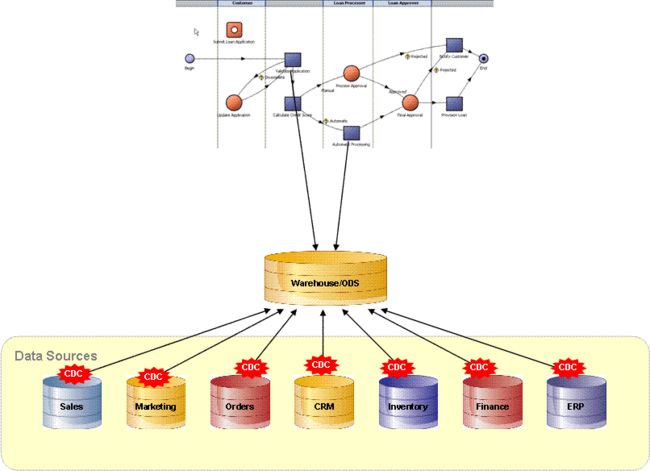
为了保证为企业提供一个全局的数据视图,我们可以通过建立一个全局的操作型数据库ODS(operational data storage),该数据库与企业内的其它数据源通过变化数据捕捉(change data capture)方式保持实时同步,当数据源内的数据发生变化时,CDC会捕捉到变化的数据并通过ETL工具或者其它手段(如主数据管理工具)同步到ODS数据库中。ODS数库内存储的数据可以分为三层,如下图所示:

接口数据层:主要负责接收从各个实时系统收集到的临时变化数据。
统一模型层:针对企业共享数据的要求建立的企业级统一数据模型,接口数据层的数据通过加工整合然后进入统一模型层。统一模型层是ODS对外提供数据供应的主要数据源
汇总数据层:根据用户的业务需要,在ODS上建立一些统计、汇总,提供一些全局的数据报表。从接口层到统一模型层以及从统一模型层到汇总层数据都可以采用异步的方式完成,很多企业目前采用的方式是从接口层到统一模型层采用准实时的方式完成,而从统一模型层到汇总层一般在晚上或者其它时间窗口完成,一方面避免对生产系统的影响,另一方面也可以充分利用机器的处理能力,当客户需要访问一些汇总数据时,可以从汇总表直接取已经汇总好的数据,从而加快系统的响应时间。
最后一点就是数据的发布格式,在该模式中,中间件层负责数据的接入访问,ODS里的数据可以封装成WEB服务发布在中间件层。当前端业务流程需要集成的数据时,可以直接访问ODS内的数据,如果数据集成比较复杂,我们可以根据用户的业务需要,通过ETL工具或者其它工具(第二种模式)对统一模型层的数据进行加工放到汇总数据层,然后再从汇总数据层访问数据。
第四种模式是采用数据网格的技术来实现实时数据集成,它和第一种方式非常相似,数据的整合加工和发布都在中间件层上,唯一不同的是我们采用数据网格技术在中间层增加了一层对象缓存层,如下图示:
数据的整合加工和访问接入都发生在中间件层,当客户端访问数据时,所有的流程方式都和第一种模式没什么区别,但需要访问的数据都通过数据网格层缓存在了中间件层,因此减少了数据源访问和网络传输的时间,访问速度会大大加快,从而可以在一定程度上解决第一种模式的不足,但数据处理仍然发生在中间件层,如果中间件处理能力有限,系统的效率还会受到局限。
在这里需要说明的是数据网格并不是专门来做数据集成的,从上面的示意图中我们也可以看到,数据集成只是数据网格的一个副产品而已,关于数据网格的定义及功能,我们会在其它文章中解释。
该模式的优势:
1. 系统扩展性好,数据网格层的扩展性决定了整个系统的扩展性。
2. 当机器的处理能力不足时,通过集群方式可以大大提高性能。
3. 真正实现了前台数据与后台数据源的松耦合。数据网格负责与各种后台数据源的交互。
问题
1. 中间件层数据的加工整理过程仍然存在。
2. 如果应用已经上线,需要针对数据网格提供的接口修改应用。
总结
以上四个模式各有自己的应用范围,从总体上看,数据的处理越靠近底层,效率越高,灵活性越差;越往上走,效率越低(网络传输和J2EE语言的擅长点不在数据处理),灵活性越好;其实各种数据集成模式无所谓好坏,关键是看业务需求,只要能够满足业务需求就够了。