嵌入式Linux系统工程师系列之ARM920T的MMU与Cache
嵌入式Linux系统工程师系列之ARM920T的MMU与Cache
宋劲杉
目录
虚拟地址和物理地址的概念
虚拟内存管理
ARM920T的CP15协处理器
MMU
Cache
操作MMU和Cache的内核启动代码
参考资料 索引
视频欣赏
虚拟地址和物理地址的概念
CPU通过地址来访问内存中的单元,地址有虚拟地址和物理地址之分,如果CPU没有MMU(Memory Management Unit,内存管理单元),或者有MMU但没有启用,CPU核在取指令或访问内存时发出的地址将直接传到CPU芯片的外部地址引脚上,直接被内存芯片(以下称为物理内存,以便与虚拟内存区分)接收,这称为物理地址(Physical Address,以下简称PA),如下图所示。
图 1. 物理地址示意图
如果CPU启用了MMU,CPU核发出的地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address,以下简称VA),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将虚拟地址映射成物理地址,如下图所示[1]。
图 2. 虚拟地址示意图
MMU将虚拟地址映射到物理地址是以页(Page)为单位的,对于32位CPU通常一页为4K。例如,虚拟地址0xb700 1000~0xb700 1fff是一个页,可能被MMU映射到物理地址0x2000~0x2fff,物理内存中的一个物理页面也称为一个页框(Page Frame)。
思考与练习
1 以下程序中用到的BASEADDR是虚拟地址还是物理地址?
#define BASEADDR 0x00008000;
int i;
unsigned int *p;
p = (unsigned int *)BASEADDR;
for(i=0;i<100;i++)
{
*(p + i) = i;
}
2 下图中内存芯片的地址范围是多少?这个地址范围是指虚拟地址还是物理地址的范围?
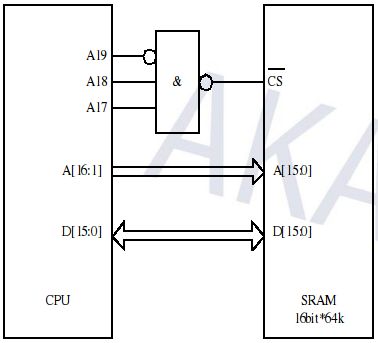
图 3. 练习题
虚拟内存管理
现代操作系统充分利用MMU提供的VA到PA的映射机制来做内存管理,以下称为虚拟内存管理(Virtual Memory Management)。首先看下面的例子:
$ ps
PID TTY TIME CMD
9612 pts/2 00:00:00 bash
32070 pts/2 00:00:00 ps
$ pmap 9612
9612: bash
08048000 668K r-x-- /bin/bash
080ef000 24K rw--- /bin/bash
080f5000 2056K rw--- [ anon ]
b7c6d000 36K r-x-- /lib/tls/i686/cmov/libnss_files-2.7.so
b7c76000 8K rw--- /lib/tls/i686/cmov/libnss_files-2.7.so
b7c78000 32K r-x-- /lib/tls/i686/cmov/libnss_nis-2.7.so
b7c80000 8K rw--- /lib/tls/i686/cmov/libnss_nis-2.7.so
b7c82000 80K r-x-- /lib/tls/i686/cmov/libnsl-2.7.so
b7c96000 8K rw--- /lib/tls/i686/cmov/libnsl-2.7.so
b7c98000 8K rw--- [ anon ]
b7c9a000 28K r-x-- /lib/tls/i686/cmov/libnss_compat-2.7.so
b7ca1000 8K rw--- /lib/tls/i686/cmov/libnss_compat-2.7.so
b7cb4000 252K r---- /usr/lib/locale/en_US.utf8/LC_CTYPE
b7cf3000 900K r---- /usr/lib/locale/en_US.utf8/LC_COLLATE
b7dd4000 4K rw--- [ anon ]
b7dd5000 1316K r-x-- /lib/tls/i686/cmov/libc-2.7.so
b7f1e000 4K r---- /lib/tls/i686/cmov/libc-2.7.so
b7f1f000 8K rw--- /lib/tls/i686/cmov/libc-2.7.so
b7f21000 16K rw--- [ anon ]
b7f25000 8K r-x-- /lib/tls/i686/cmov/libdl-2.7.so
b7f27000 8K rw--- /lib/tls/i686/cmov/libdl-2.7.so
b7f29000 180K r-x-- /lib/libncurses.so.5.6
b7f56000 12K rw--- /lib/libncurses.so.5.6
b7f59000 4K r---- /usr/lib/locale/en_US.utf8/LC_NUMERIC
b7f5a000 4K r---- /usr/lib/locale/en_US.utf8/LC_TIME
b7f5b000 4K r---- /usr/lib/locale/en_US.utf8/LC_MONETARY
b7f5c000 4K r---- /usr/lib/locale/en_US.utf8/LC_MESSAGES/SYS_LC_MESSAGES
b7f5d000 4K r---- /usr/lib/locale/en_US.utf8/LC_PAPER
b7f5e000 4K r---- /usr/lib/locale/en_US.utf8/LC_NAME
b7f5f000 4K r---- /usr/lib/locale/en_US.utf8/LC_ADDRESS
b7f60000 4K r---- /usr/lib/locale/en_US.utf8/LC_TELEPHONE
b7f61000 4K r---- /usr/lib/locale/en_US.utf8/LC_MEASUREMENT
b7f62000 28K r--s- /usr/lib/gconv/gconv-modules.cache
b7f69000 4K r---- /usr/lib/locale/en_US.utf8/LC_IDENTIFICATION
b7f6a000 8K rw--- [ anon ]
b7f6c000 4K r-x-- [ anon ]
b7f6d000 104K r-x-- /lib/ld-2.7.so
b7f87000 8K rw--- /lib/ld-2.7.so
bfad4000 84K rw--- [ stack ]
total 5948K
例 1. 进程的地址空间
这是bash进程的虚拟地址空间,32位CPU的虚拟地址空间是4GB,也就是0x0000 0000-0xffff ffff,该进程占用的地址范围近似为0x0000 0000-0xbfff ffff,地址范围0xc000 0000-0xffff ffff由内核占用,用户进程不允许访问。在这个bash进程的地址空间中,从0x0804 8000开始的668K的权限为r-x--,表示代码段,从0x080e f000开始的24K的权限是rw---,表示数据段,从0x080f 5000开始的2056K的权限也是rw---,但是没有对应任何磁盘文件,而是用[ anon ](anonymous,匿名)来表示,这是堆所占的空间,从0xb7c6 d000开始是共享库和资源文件的映射空间,每个共享库也分为代码段和数据段,用不同的权限表示,可以看到,从堆空间到下面的共享库映射空间之间有很大的地址空洞,最末从0xbfad 4000开始的84K是栈空间。
为什么需要虚拟内存管理呢?可以从以下几个方面来理解。
第一,让每个进程有独立的地址空间是引入虚拟内存管理的最主要目的。所谓独立的地址空间是指,不同进程中的同一个VA被MMU映射到不同的PA,并且在某一个进程中访问任何地址都不可能访问到另外一个进程的数据,这样使得任何一个进程由于程序BUG或恶意代码所导致的非法内存访问都不会意外改写其它进程的数据,不会影响其它进程的运行,从而保证了整个系统的稳定性。另一方面,每个进程都认为自己独占4GB的地址空间,编写程序会比较方便,不必为每个进程分配一个地址范围,而是每个进程都可以使用一个完整的地址空间中的任何地址。
我们继续用上面的例子来理解,再打开一个shell窗口,用pmap命令看一下这个新的bash进程的地址空间,可以发现和刚才的地址空间布局差不多:
$ ps
PID TTY TIME CMD
32371 pts/1 00:00:00 bash
32387 pts/1 00:00:00 ps
$ pmap 32371
32371: bash
08048000 668K r-x-- /bin/bash
080ef000 24K rw--- /bin/bash
080f5000 2000K rw--- [ anon ]
b7c71000 36K r-x-- /lib/tls/i686/cmov/libnss_files-2.7.so
b7c7a000 8K rw--- /lib/tls/i686/cmov/libnss_files-2.7.so
......
该进程也占用了0x0000 0000-0xbfff ffff的地址空间,代码段也是从0x0804 8000开始的668K,数据段也是从0x080e f000开始的24K,共享库的内存布局也差不多。这个进程和刚才的例子是同一个系统中同时运行着的两个进程,它们都认为自己占有0x0000 0000-0xbfff ffff的地址空间,并且它们的数据段的地址范围是重合的,但是两个进程各自干各自的事情,显然数据段中的数据是不同的,正是因为不同进程中的同一个VA被映射到了不同的PA,所以两个进程的数据段其实是在不同的物理地址上,如下图所示。
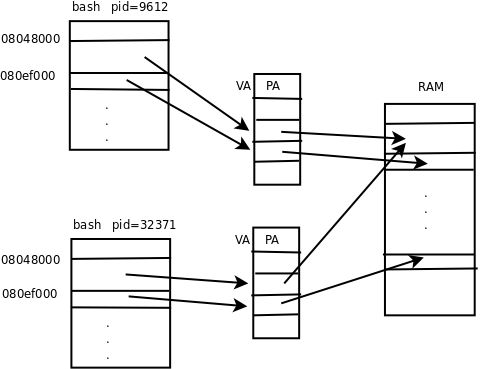
图 4. 进程地址空间是独立的
从图中还可以看到,两个进程都是bash进程,代码段是一样的,并且代码段是只读的,不会被改写,因此操作系统会安排两个进程的代码段共享相同的物理内存。由于每个进程都有自己的一套VA到PA的映射表,整个地址空间中的任何VA都在每个进程自己的映射表中查找相应的物理地址,因此不可能访问到其它进程的地址,也就没有可能意外改写其它进程的数据。
第二,引入VA到PA的映射也会给分配和释放内存带来方便,物理上不连续的空间可以映射为逻辑上连续的虚拟地址空间。比如要malloc一块很大的内存空间,而物理内存虽然有足够的空闲内存,却没有足够大的连续空闲内存,这时就可以分配多个不连续的物理页面,而映射为连续的虚拟地址范围。如下图所示。
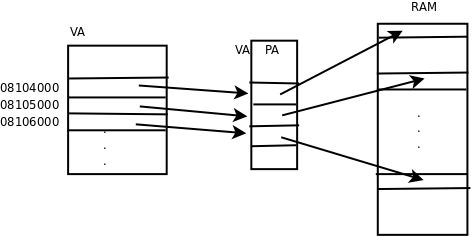
图 5. 不连续的PA可以映射为连续的VA
第三,一个系统如果同时运行着很多进程,为各进程分配的内存之和可能会大于实际可用的物理内存,虚拟内存管理使得这种情况下各进程仍然能够正常运行。因为各进程分配的只不过是虚拟内存的页,这个页的内容可以映射到物理内存的页框,也可以临时保存到磁盘上而不占用物理内存的页框,磁盘上这一部分称为交换设备(Swap Device),可能是一个磁盘分区,也可能是一个磁盘文件。当物理内存不够时将物理内存中不常用的页框临时保存到磁盘上,而当用到这些页框时再从磁盘加载回内存,这称为换页(Paging)因此:
系统中可分配的内存总量 = 物理内存的大小 + 交换设备的大小
如下图所示。第一张图是换出(Page out),将物理页面的内容保存到磁盘,并解除地址映射,释放物理页面。第二张图是换入(Page in),从空闲的物理页面中分配一个,将磁盘暂存的页面加载回内存,并建立地址映射。
图 6. 换页
第四,虚拟内存管理可以控制物理页面的访问权限。物理内存本身是不限制访问的,任何地址都可以读写,而操作系统要求实现各种不同的访问权限,在先前的例子中我们已经看到,代码段要求是rx的,数据段要求是rw的,用户进程不能访问属于内核的地址空间,这些都是操作系统和MMU配合实现的。
MMU中还实现了一种访问限制是关于Cache的。Cache(高速缓存)是CPU内的一小块高速RAM,用来缓存最近访问过的内存数据,CPU访问Cache的速度是访问内存速度的数十倍,所以有效地利用Cache可以大大提高计算机的整体性能。CPU核要访问数据时首先发出VA,Cache利用VA查找相应的数据有没有被缓存[2],如果有就通知CPU核,如果是读操作就直接将Cache中的数据传给CPU核中的寄存器,如果是写操作就直接改写Cache中的数据,而不需要访问物理内存。但是,有些VA所对应的PA并不是物理内存中的地址而是设备寄存器的地址,对这些寄存器进行读写并不是为了保存数据,而是对设备做特殊操作,这种VA通常是不允许缓存的,因为如果缓存了,对VA的读写将只在Cache中起作用,而不会传到设备寄存器对设备进行操作。以串口的收发寄存器为例,如果收发寄存器地址被缓存了会出现什么问题呢?如下图所示。
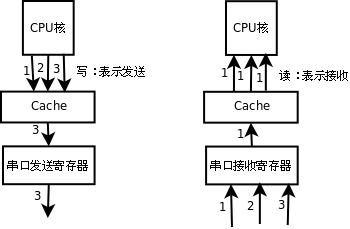
图 7. 串口收发寄存器如果被缓存会出什么问题
如果发送寄存器的地址被缓存起来,CPU核往发送寄存器的地址做写操作都写到Cache中去了,发送寄存器并没有及时得到数据,也就不能及时发送,此外,CPU核先后发出的1、2、3三个数据都会写到Cache中的同一个地址,最后Cache中只保存了第3个数据,如果这时Cache的数据写回到发送寄存器去,只能把第3个数据发送出去,前两个数据就丢失了。与此类似,如果接收寄存器的地址被缓存起来,CPU核在读第1个数据时,Cache会从接收寄存器读进来缓存,然而接收寄存器后面收到2、3两个数据Cache并不知道,因为Cache把接收寄存器当作内存,并且相信内存中的数据是不会自己变的,所以以后每次CPU核读接收寄存器时,Cache都提供给CPU核第1个数据。
ARM920T的CP15协处理器
ARM920T的MMU和Cache都集成在CP15协处理器中,MMU和Cache的联系非常密切,本节首先从总体上介绍MMU、Cache和CPU核是如何协同工作的,后面两节分别讲解MMU和Cache的细节。三星公司的S3C2410是一种很常见的采用ARM920T的芯片,涉及到具体的芯片时我们以S3C2410为例。
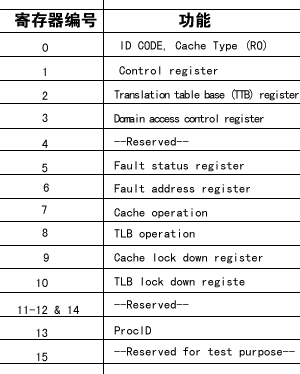
以下是CP15协处理器的寄存器列表(摘自[S3C2410用户手册]),和CPU核的r0到r15寄存器一样,协处理器寄存器也是用0到15来编号,在指令中用4个bit来表示寄存器编号,有些协处理器寄存器有影子寄存器,这种情况下对同一个编号的寄存器使用不同的选项读或者写实际上访问的是不同的寄存器,后文用到某个寄存器时会详细说明它的功能。
表 1. CP15协处理器的寄存器列表
对CP15协处理器的操作使用mcr和mrc两条协处理器指令,这两条指令的记法是从后往前看:mcr是把r(CPU核寄存器)中的数据传送到c(协处理器寄存器)中,mrc则是把c(协处理器寄存器)中的数据传送到r(CPU核寄存器)中。对CP15协处理器的所有操作都是通过CPU核寄存器和CP15寄存器之间交换数据来完成的。下图是协处理器的指令格式(摘自[S3C2410用户手册])。
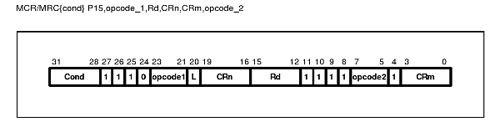
图 8. 协处理器指令格式
和其它ARM指令一样,Cond是条件码,bit 20是L位,表示该指令是读还是写,如果L=1就表示Load,从外面读到CPU核中,也就是mrc指令,如果L=0就表示Store,也就是mcr指令。[11:8]这四个位是协处理器编号,CP15的编号是15,因此是4个1。CRn是CP15寄存器编号,Rd是CPU核寄存器编号,各占4个位。对于CP15协处理器,规定opcode1应该为0,opcode2和CRm是指令的选项,具体含义取决于不同的寄存器。
虽然这里介绍了协处理器的寄存器编号和相关指令,但读者只需了解对协处理器是这样进行操作的就可以了,我们的重点是讲解MMU和Cache的基本概念,具体各种操作的指令该怎么写可以参考[S3C2410用户手册]。
MMU是如何把VA映射成PA的呢?从图 4 “进程地址空间是独立的”来看,好像是有一张VA转PA的表,给一个VA查表就可以查到PA,实际上并不是这么简单,通常要有一个多级的查表过程,对于ARM体系结构是两级查表,对于一些64位体系结构则需要更多级。看下面的图示。

图 9. Translation Table Walk
首先将32位的VA[3]分成三段,前两段[31:20]和[19:12]作为两次查表的索引,第三段[11:0]作为页内的偏移。查表的步骤如下:
1 CP15协处理器的TTB寄存器(看看表 1 “CP15协处理器的寄存器列表”中这是第几个寄存器?)中保存着第一级页表(Translation Table)的基地址,这个基地址指的是PA,也就是说页表是直接按这个地址存在物理内存中的。
2 以TTB中的内容为基地址,以VA[31:20]为索引在表中查出一项(想一下这个表中一共有多少项?),这个表项中保存着第二级页表(Coarse Page Table)的基地址,同样是物理地址,也就是说第二级页表也是直接按这个地址存在物理内存中的。
3 以VA[19:12]为索引在第二级页表中查出一项(想一下这个表中一共有多少项?),这个表项中就保存着物理页面的基地址,先前我们说虚拟内存管理是以页为单位的,一个虚拟内存的页映射到一个物理内存的页框,从这里就可以得到印证,因为查表是以页为单位来查的。
4 有了物理页面的基地址之后,加上VA[11:0]这个偏移量就可以取出相应地址上的数据(想一下一个页是多少字节?)。
这个过程称为Translation Table Walk,Walk这个词用得非常形象。从TTB走到一级页表,又走到二级页表,又走到物理页面,一次寻址其实是三次访问物理内存。注意这个“走”的过程完全是硬件做的,每次CPU寻址时MMU就自动完成以上四步,不需要编写指令指示MMU去做,前提是操作系统要维护页表项的正确性,每次分配内存时填写相应的页表项,每次释放内存时清除相应的页表项,在必要的时候分配或释放整个页表。
有了以上基本概念,我们来看CPU访问内存时的硬件操作顺序(摘自[ARM参考手册])。
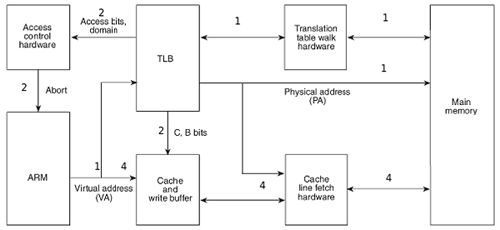
图 10. CPU访问内存时的硬件操作顺序
我们以CPU读内存为例解释一下图中的步骤,各步骤在图中有对应的标号。
1 CPU核(图中的“ARM”框)发出VA请求读数据,TLB(Translation Lookaside Buffer)接收到该地址。TLB是MMU中的一块高速缓存(也是一种Cache),它缓存最近查找过的VA对应的页表项,如果TLB里缓存了当前VA的页表项就不必做Translation Table Walk了,否则去物理内存中读出页表项保存在TLB中,TLB缓存可以减少访问物理内存的次数。
2 页表项中不仅保存着物理页面的基地址,还保存着权限位和是否允许Cache的标志。MMU首先检查权限位,如果没有访问权限,就引发一个异常给CPU核。然后检查是否允许Cache,如果允许Cache就启用Cache和CPU核互操作,图中的“C, B bits”可以理解为选通线,后面再详细解释这两个位的作用。
3 如果不允许Cache,则直接发出PA从物理内存中读取数据到CPU核。
4 如果允许Cache,则以VA为索引到Cache中查找是否缓存了要读取的数据,如果Cache中已经缓存了该数据(称为Cache Hit)则直接返回给CPU核,如果Cache中没有缓存该数据(称为Cache Miss),则发出PA从物理内存中读取数据并缓存到Cache中,同时返回给CPU核。然而Cache并不是只取CPU核所要的数据,而是把相邻的数据都取上来缓存,这称为一个Cache Line。ARM920T的Cache Line是32字节,例如CPU核要读取地址0x134-0x137的4字节数据,Cache会把地址0x120-0x13f(对齐到32字节地址边界)的32字节都取上来缓存。
思考与练习
每个进程有独立的地址空间是怎么实现的?也就是说,为什么两个进程的同一个虚拟地址会映射到不同的物理地址?
MMU
我们已经简单了解了一下查页表的过程,实际上ARM920T支持多种尺寸规格的页表,图 9 “Translation Table Walk”所示的只是其中一种情况。下图示意了所有可能的情况(本节的图表均摘自[S3C2410用户手册])。

图 11. 查页表的过程
回顾一下查表的过程,首先从CP15的TTB寄存器找到一级页表的基地址,再把VA[31:20]作为索引从表中找出一项,这个表项称为一级页描述符(Level 1 Descriptor),一个这样的表项占4个字节,可以是以下四种格式之一:
图 12. 一级页描述符
如果描述符的最低两位是00,属于Fault格式,表示该范围的VA没有映射到PA。如果描述符的最低两位是10,属于Section格式,这种格式没有二级页表而是直接映射到物理页面,一个Section是1M的大页面,描述符中[31:20]位就是这个页面的基地址,基地址的[19:0]低位全为0,对齐到1M地址边界,描述符中的Domain和AP位控制访问权限,C、B两位控制缓存,后面再详细解释每个位的含义。如果描述符的最低两位是01或11,则分别对应两种不同规格的二级页表。根据地址对齐的规律想一下,这两种页表分别是多大?从一级描述符中取出二级页表的基地址,再把VA的一部分作为索引去查二级描述符(Level 2 Descriptor)(如果是Coarse Page Table则VA[19:12]是索引,如果是Fine Page Table则VA[19:10]是索引),二级描述符可以是以下四种格式之一:

图 13. 二级页描述符
描述符最低两位是00属于Fault格式,其它三种情况分别对应三种不同规格的物理页面。Large Page和Small Page有四组AP权限位,每组两个bit,这样可以为每1/4个物理页面分别设置不同的权限,也就是说,Large Page可以为每16K设置不同的权限,Small Page可以为每1K设置不同的权限。
ARM920T提供了多种页表和页面规格,但操作系统只采用其中一种,Linux采用的就是图 9 “Translation Table Walk”所示的规格,一级描述符是Coarse Page Table格式,二级描述符是Small Page格式,每个物理页面4K。我们以此为例,结合前面的的解释和页描述符的格式,再看一下Translation Table Walk的详细过程:

图 14. Translation Table Walk的详细过程
从上到下依次解释如下:
1 VA被划分为三段用于地址映射过程,各段的长度取决于页描述符的格式。
2 TTB寄存器中只有[31:14]位有效,低14位全为0,因此一级页表的基地址对齐到16K地址边界,而一级页表的大小也是16K。
3 一级页表的基地址加上VA[31:20]左移两位组装成一个物理地址。想一想为什么VA[31:20]要左移两位占据[13:2]的位置,而空出[1:0]两位呢?
4 用这个组装的物理地址从物理内存中读取一级页描述符,这是一个Coarse Page Table格式的描述符。
5 通过Domain权限检查后,Coarse Page Table的基地址再加上VA[19:12]左移两位组装成一个物理地址。
6 用这个组装的物理地址从物理内存中读取二级页描述符,这是一个Small Page格式的描述符。
7 通过AP权限检查后,Small Page的基地址再加上VA[11:0]就是最终的物理地址。想一想为什么这次不左移两位了呢?
下面解释一下Domain和AP位。CP15的Domain访问控制寄存器(见表 1 “CP15协处理器的寄存器列表”寄存器3)表示了16个Domain,每两位表示一个Domain的访问权限,以下是该寄存器的格式:
<Palign=center>
图 15. Domain Access Control Register
每个Domain的两个位可以取值为00、01、10或11,如果取值为00或10则表示该Domain不可访问,如果取值为01则表示访问该Domain需要进一步检查AP位,如果取值为11则表示可以直接访问该Domain而无需检查AP位。回想一下,一级页描述符中的Domain字段由4个位组成,可以有16个不同的取值,就表示该描述符所描述的二级页表或Section属于这16个Domain中的哪一个。快速上下文切换、Domain和多种规格的页表是ARM特有的机制,是针对嵌入式系统软件的特点而设计的,其它处理器不一定有类似的机制,例如也许没有Domain和快速上下文切换的概念,也许只有一种规格的页表。为了能够在多种不同的平台上移植,Linux内核代码不会利用ARM特有的这些机制。除了这些特例之外,我们在这里介绍的其它机制都具有普遍性,读者应重点把握具有普遍意义的基本原理和基本概念。
CP15的控制寄存器(见表 1 “CP15协处理器的寄存器列表”寄存器1)中的S和R位与页描述符的AP位合在一起决定访问权限,如下所示:
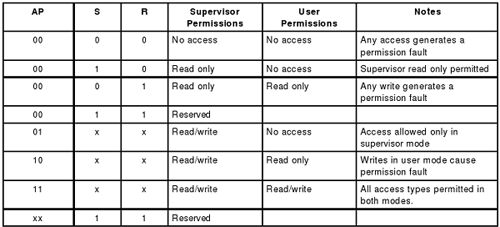
图 16. AP权限检查
可见,同样的AP、S、R位对用户模式和特权模式来说具有不同的意义,特权模式的权限都不低于用户模式的权限。最后将各种由内存访问产生的异常总结如下:
Alignment Fault——以Word为单位的数据访问指令地址未对齐到4字节边界,或者以Half Word为单位的数据访问指令地址未对齐到2字节边界。
Translation Fault——页描述符的[1:0]为00,属于Fault格式,无效表项。
Domain Fault——一级页描述符或Section所属Domain的权限位为00或10。
Permission Fault——根据AP位和CP15寄存器1的S、R位检查访问权限,若所属Domain的权限位为11则跳过这一步检查。
External Abort——总线异常,例如此物理地址上没有挂RAM芯片,或者其它硬件故障。
思考与练习
1 从VA到PA的映射为什么要采用多级页表的方式?如果只有一级页表,那么一次寻址就只需两次访问物理内存的操作(一次是页表,一次是物理页面),不是比多级页表更快吗?
2 多个进程可以共享同一段物理内存,比如两个bash进程共享同一个bash代码段,比如所有进程共享libc代码段,这是怎么实现的?
3 用户进程不能访问属于内核的地址空间,否则会出段错误,这是怎么实现的?
Cache
ARM920T有16K的数据Cache和16K的指令Cache,这两个Cache是基本相同的,数据Cache多了一些写回内存的机制,后面我们以数据Cache为例来介绍Cache的基本原理。我们已经知道,Cache中的存储单位是Cache Line,ARM920T的一个Cache Line是32字节,因此16K的Cache由512条Cache Line组成。要了解Cache的基本原理,我们从如何设计Cache这个问题入手。
设计Cache的一种最朴素的想法是,把VA分成以32字节为单位,从任何一个对齐到32字节地址边界的VA开始连续的32个字节(比如0x00-0x1f,0x20-0x3f,0x40-0x5f等等)都可以缓存到512条Cache Line中的任何一条。那么一条Cache Line中的32个字节怎么知道是来自哪个VA的呢?这就需要把VA也保存在Cache中,由于这32字节的起始地址是对齐到32字节地址边界的,末5位全为0,因此只需要保存VA[31:5]即可,这称为VA Tag[4],Tag是VA的一部分,是Cache Line中数据的标识,表明这32字节数据来自哪个VA。这样设计的Cache称为全相联Cache(Fully Associative Cache),图示如下:
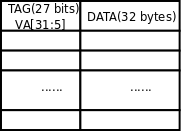
图 17. 全相联Cache
给定一个VA,如何在Cache中查找对应的数据呢?首先到Cache中比较查找哪一行的Tag等于VA[31:5],找到对应的Cache Line后,再根据VA[4:0]决定要访问的是该Cache Line缓存的32个字节中的哪一个字节。由于有512条Cache Line,如果这个VA没有缓存在Cache中则需要比较512次才知道,这是最坏的情况,也是最常见的情况,下面我们要改进Cache的设计来解决这个问题。
全相联Cache的特点是任何VA都可以缓存到任何一条Cache Line,给定一个VA做查找时,由于它有可能缓存在512条Cache Line中的任何一条,就只好全部都找一遍了。如果限定某一个VA只允许缓存在某一条Cache Line中,那么查找的过程就快多了:检查一下应该缓存这个VA的那条Cache Line,看Tag一致不一致,如果一致就是Cache Hit,如果不一致就是Cache Miss,可以直接访问物理内存而不必再找其它Cache Line了。这种设计称为直接映射Cache(Direct Mapped Cache),如下图所示:
图 18. 直接映射Cache
地址0~31应该缓存在第1条Cache Line中,地址32~63应该缓存在第2条Cache Line中,依此类推,地址16352~16383应该缓存在第512条Cache Line中,下一个地址应该是16384(16K)了,我们又回到开头,地址16K~16K+31应该缓存在第1条Cache Line中,地址16K+32~16K+63应该缓存在第2条Cache Line中,依此类推,再次回到开头的地址应该是32K,32K~32K+31应该缓存在第1条Cache Line中,32K+32~32K+63应该缓存在第2条Cache Line中,依此类推。读者应该可以总结出规律了:给定一个VA,将它除以16K得的余数决定了它应该缓存在哪一条Cache Line中,那么除以16K的商数部分就应该是VA Tag,用以区别Cache Line中缓存的到底是0还是16K还是32K地址上的数据。那么除以16K的商数和余数怎么表示呢?VA[31:14]就是除以16K的商数,VA[13:0]就是余数,所以上图的Tag处标着VA[31:14]。余数VA[13:0]是16K Cache里的一个字节偏移量,而Cache是按32字节一个Cache Line组织的,所以余数中的高位VA[13:5]决定了是第几条Cache Line,余数中的低位VA[4:0]决定了Cache Line内的字节偏移量。验算一下,VA[13:5]一共是9位,作为Cache Line的编号可以表示的Cache Line数目正是512条。
直接映射Cache虽然查找速度很快,但也有缺点。比如,地址0~31、16K~16K+31、32K~32K+31都应该缓存到第1条Cache Line中,假如我们程序第一次访问地址30,地址0~31的数据就从内存加载到第1条Cache Line,以便下次访问能更快一些,但是我们程序第二次访问的却是地址32770,地址32K~32K+31的数据就要从内存加载到第1条Cache Line,把Cache Line里原来存的地址0~31的数据替换掉,以便下次访问能更快一些,但是我们程序第三次访问的却是地址16392……这样下去,Cache起不到任何加速作用,形同虚设,这种问题称为Cache抖动(Cache Thrash)。全相联Cache就不会有这种问题,因为任何VA都可以缓存到任何一条Cache Line,可以把先后几次访问的VA缓存到不同的Cache Line,就不会相互冲突。
全相联Cache和直接映射Cache各有优缺点,全相联Cache查找很慢,但没有抖动问题,直接映射Cache则正相反。为了得到更好的性能,实际CPU的Cache设计是取两者的折衷,把所有Cache Line分成若干个组,每一组有n条Cache Line,称为n路组相联Cache(n-way Set Associative Cache)。ARM920T采用64路组相联Cache,如下图所示:
图 19. 64路组相联Cache
有了前面两种Cache概念的基础,这种Cache应该很好理解,512条Cache Line分成8组,每组64条,地址0-31、256-587、512-543等等可以缓存到第1组64条Cache Line中的任何一条,地址32-63、288-319、544-575等等可以缓存到第2组64条Cache Line中的任何一条,依此类推。为什么说组相联Cache是全相联和直接映射Cache的一个折衷呢?如果把组分得很大,把全部Cache Line都分到一个组里面去,就变成了全相联Cache;如果把组分得很小,每组只有一个Cache Line,就变成了直接映射Cache。作为练习,请读者自己计算一下为什么VA Tag是VA[31:8],为什么组的编号用VA[7:5]表示。
那么,为什么组相联Cache的性能比直接映射Cache要好呢?一方面,组相联Cache把一条Cache Line上的冲突分散到了64条Cache Line上,起到了64倍的积极作用。而另一方面,应该缓存到同一个组的VA更多了:对于直接映射Cache,在同一个组(也就是同一条Cache Line)互相冲突的VA有4G/512个;对于组相联Cache,在同一个组(64条Cache Line)互相冲突的VA有4G/8个。从这个数量关系来看,组相联Cache又起到了64倍的消极作用。难道这两种作用不会完全抵销吗?我不打算从数学上严格证明,这不是本节的重点,读者可以通过一个生活常识的例子来理解:层数一样多的两栋楼,其中一栋楼是一部电梯,每层三户,而另一栋楼是两部电梯,每层六户,每户的平均人数一样多,你认为在哪个楼里等电梯的时间较短呢?
接下来解释一下有关Cache写回内存的问题。Cache写回内存有两种模式:
Write Back:Cache Line中的数据被CPU核修改时并不立刻写回内存,Cache Line和内存中的数据会暂时不一致,在Cache Line中有一个Dirty位标记这一情况。当一条Cache Line要被其它VA的数据替换时,如果不是Dirty的就直接替换掉,如果是Dirty的就先写回内存再替换。
Write Through:每当CPU核修改Cache Line中的数据时就立刻写回内存,Cache Line和内存中的数据总是一致的。如果有多个CPU或设备同时访问内存,例如采用双口RAM,那么Cache中的数据和内存保持一致就非常重要了,这时相关的内存页面通常配置为Write Through模式。
通过读写CP15的相关寄存器,可以对Cache做以下操作:
Clean:将Cache Line中的数据写回内存,清除Dirty位。在程序中的某些同步点上用于确保Cache Line和内存中的数据一致。
Invalidate:在Cache Line中有一个Invalid位表示无效,将这个位置1,下次要访问时即使VA Tag匹配也重新从内存读取数据。例如进程切换时需要声明前一个进程缓存在Cache中的数据无效。
Lock:将某个地址的数据锁定在Cache中,确保不被替换掉。在实时系统中,这样做可以保证某个地址的数据能在一个确定的时间内访问到。
从Cache中查找要访问的数据时用的是VA,但是Cache写回内存要用PA,如果写回内存时还需要查一遍页表就太没有效率了,所以实际上每条Cache Line中还保存了PA[31:5](PA Tag),完整的Cache构造如下图所示:
图 20. PA Tag
最后解决我们前面遗留的一个问题:页描述符中的C、B位具体是什么意思?
表 2. 页描述符中C、B位的含义

C位为1表示允许Cache,这种情况下用B位来表示Write Through还是Write Back。有些页面不允许Cache,置C位为0,这种情况下可以用B位来选择是否允许使用Write Buffer。Write Buffer也是一种简单的Cache,CPU核执行写指令时可以把数据交给Write Buffer,然后由Write Buffer负责写回内存,这时CPU可以执行后续指令而不必等待写回内存这个较慢的操作结束。想一下,既然有Write Buffer,为什么没有Read Buffer?
思考与练习
ARM920T的Cache是64路组相联的,而PC和服务器CPU的Cache往往只有4路组相联,路数越多查找越慢,为什么ARM要设计这么多的路数?
操作MMU和Cache的内核启动代码
bootloader加载linux内核到内存并解压之后,Linux内核首先在汇编代码中读取CPU的基本信息,对CPU做一些基本设置,创建最简单的临时页表,然后开启MMU和Cache,启用虚拟内存管理(此后CPU核发出的地址都是虚拟地址),然后跳到C代码中完成其它初始化工作,比如创建完整的页表、初始化各种内核子系统、初始化硬件设备等。本节以Linux 2.4内核的启动代码为例,了解一下操作MMU和Cache的具体指令是怎么写的,通过实例来加深对前面内容的理解。本节的内容改编自[ARM Linux演义]。
假设目标板的RAM物理地址是从0x0800 0000开始的(也就是说,RAM芯片连接到CPU芯片上从0x0800 0000开始的bank)。经过内核的若干初始化代码之后,寄存器的内容如下:
表 3. 寄存器的初始值

接下来的步骤是:
1 创建简单的临时页表和临时映射
2 配置与MMU和Cache相关的CP15寄存器
3 启用MMU和Cache
临时页表存放在物理内存地址0x0800 4000开始的16K(回想一下,第一级页表是16K,有4096个页描述符)。后面将会把页描述符填写成Section格式,也就是直接映射到1M的大页面,这些都是内核初始化阶段临时用的,为了是写尽可能少的汇编代码,尽快启用MMU并跳到C代码中做剩下的初始化工作,在完整的两级页表建立之后临时页表就没有用了。首先将16K的临时页表清零:
mov r0, r4
mov r3, #0
add r2, r0, #0x4000 @ 16k of page table
1: str r3, [r0], #4 @ Clear page table
str r3, [r0], #4
str r3, [r0], #4
str r3, [r0], #4
teq r0, r2
bne 1b
下面我们将使用Section格式的页描述符来填充表项,由于是内核初始化阶段,还没有用户进程,我们只映射4M的地址空间,覆盖内核本身的代码和数据就可以了。思考一下,为什么首先要把这16K临时页表清零,即使没用到的表项也要清零?由于Linux内核在编译时确定的代码加载地址是0xc000 8000(虚拟地址),而bootloader将内核代码加载到物理地址0x0800 8000,我们需要把物理地址从0x0800 0000开始的4M映射到虚拟地址从0xc000 0000开始的4M。
但是这里有一个问题:设置好页表之后,最终有一条指令是启用MMU的,假设该指令的PA是0x0800 810c,根据我们要做的映射关系,它的VA应该是0xc000 810c,没有启用MMU之前CPU核发出的都是物理地址,从0x0800 810c地址取这条指令来执行,然而该指令执行之后,CPU核发出的地址都要被MMU拦截,CPU核就必须用虚拟地址来取指令了,因此下一条指令应该从0xc000 8110处取得,然而这时pc寄存器(也就是r15寄存器)的值并没有变,CPU核取下一条指令仍然要从0x0800 8110处取得,此时0x0800 8110已经成了非法地址了。如下图所示。
图 21. 启用MMU的那条指令导致的问题
为了解决这个问题,要求启用MMU的那条指令及其附近的指令虚拟地址跟物理地址相同,这样在启用MMU前后,附近指令的地址不会发生变化,从而实现平稳过渡。因此需要将物理地址从0x0800 0000开始的1M再映射到虚拟地址从0x0800 0000开始的1M,也就是做一个等价映射(identity map)[5]。现在把需要建立的映射项总结如下:
表 4. 需要建立的映射项
以下代码建立上面所说的等价映射。
回头看一下表 3 “寄存器的初始值”,r8的值是页描述符标志位,r5的值是RAM起始物理地址0x0800 0000,由于要做的是等价映射,这里的r5既是PA同时也是VA,第一条指令将r5当作PA,r3=r8+r5=0x0800 0c1e得到完整的页描述符,比对一下看看各bit的含义。
![]()
图 22. 等价映射的页描述符
add r3, r8, r5 @ mmuflags + start of RAM
add r0, r4, r5, lsr #18
str r3, [r0] @ identity mapping
该描述符所描述的Section属于第0个Domain,AP位是11,可读可写,C、B位都是1,允许Cache,并且Cache是Write Back方式的。第二条指令,将虚拟地址r5右移18位(对照图 14 “Translation Table Walk的详细过程”看一下为什么是右移18位),加到页表基地址上,得到该描述符在页表中的地址,结果保存在r0中。第三条指令,将第一条指令计算出的页描述符的值r3保存在第二条指令计算出的r0地址处,这样就填写好了页表项。
下面映射物理地址从0x8000 0000开始的4M到虚拟地址0xc000 0000,其中TEXTADDR是Linux内核在编译时确定的代码加载地址0xc000 8000,PAGE_OFFSET定义为0xc000 0000。请读者自己分析以下代码。
add r0, r4, #(TEXTADDR & 0xfff00000) >> 18 @ start of kernel 注:r0 = r4+ 0x3000 = 0800 4000 + 3000 = 0800 7000 str r3, [r0], #4 @ PAGE_OFFSET + 0MB 注:0800 7000地址的内容为0800 0c1e add r3, r3, #1 << 20 注:r3=0810 0c1e str r3, [r0], #4 @ PAGE_OFFSET + 1MB 注:0800 7004地址的内容为0810 0c1 e add r3, r3, #1 << 20 注:r3=0820 0c1e str r3, [r0], #4 @ PAGE_OFFSET + 2MB 注:0800 7008地址的内容为0820 0c1e add r3, r3, #1 << 20 注:r3=0830 0c1e str r3, [r0], #4 @ PAGE_OFFSET + 3MB 注:0800 700c地址的内容为0830 0c1e
设置好了页表,接下来设置与MMU和Cache相关的CP15寄存器:
mov r0, #0
mcr p15, 0, r0, c7, c7 @ invalidate I,D caches on v4
mcr p15, 0, r0, c7, c10, 4@ drain write buffer on v4
mcr p15, 0, r0, c8, c7 @ invalidate I,D TLBs on v4
mcr p15, 0, r4, c2, c0 @ load page table pointer
mov r0, #0x1f @ Domains 0, 1 = client
mcr p15, 0, r0, c3, c0 @ load domain access register
mrc p15, 0, r0, c1, c0 @ get control register v4
/*
* Clear out 'unwanted' bits (then put them in if we need them)
*/
@ VI ZFRS BLDP WCAM
bic r0, r0, #0x0e00
bic r0, r0, #0x0002
bic r0, r0, #0x000c
bic r0, r0, #0x1000 @ ...0 000. .... 000.
/*
* Turn on what we want
*/
orr r0, r0, #0x0031
orr r0, r0, #0x2100 @ ..1. ...1 ..11 ...1
#ifdef CONFIG_CPU_ARM920_D_CACHE_ON
orr r0, r0, #0x0004 @ .... .... .... .1..
#endif
#ifdef CONFIG_CPU_ARM920_I_CACHE_ON
orr r0, r0, #0x1000 @ ...1 .... .... ....
#endif
这一段有很多协处理器指令,请读者对照[S3C2410用户手册]和代码中的注释查看各指令的含义。大体上来说做了以下事情:首先禁用指令和数据Cache,等待Write Buffer写回内存,然后用r4寄存器的值设置CP15的TTB寄存器,然后设置Domain权限位,我们先前填写的页描述符都属于第0个Domain,Domain寄存器中第0个Domain的权限位设置为11,表示访问不必检查AP位。接下来读出CP15的控制寄存器的值来修改,准备启用MMU,根据内核配置决定是否启用数据和指令Cache,修改之后一并写回控制寄存器,使设置生效:
mcr p15, 0, r0, c1, c0
参考资料
[S3C2410用户手册] User's Manual S3C2410A - 200MHz & 266MHz 32-Bit RISC Microprocessor. 1.0. 版权 © 2004 Samsung Electronics.
[ARM参考手册] ARM Architecture Reference Manual. 版权 © 1996-2000 ARM Limited.
[ARM Linux演义] 网上到处转载的帖子: ARM Linux演义. 作者已不可考,据说是r58452网友.
索引
C
Cache,高速缓存, 虚拟内存管理
Cache Hit, ARM920T的CP15协处理器
Cache Line, ARM920T的CP15协处理器
Cache Miss, ARM920T的CP15协处理器
Cache Thrash,Cache抖动, Cache
Direct Mapped Cache,直接映射Cache, Cache
Fully Associative Cache,全相联Cache, Cache
n-way Set Associative Cache,n路组相联Cache, Cache
M
MMU,Memory Management Unit,内存管理单元, 虚拟地址和物理地址的概念
P
Page Frame,页框,物理页面, 虚拟地址和物理地址的概念
Page Table,页表, ARM920T的CP15协处理器
Page,页, 虚拟地址和物理地址的概念
(参见 Page Frame,页框)
Paging,换页, 虚拟内存管理
Page in,换入, 虚拟内存管理
Page out,换出, 虚拟内存管理
PA,Physical Address,物理地址, 虚拟地址和物理地址的概念
(参见 VA,Virtual Address,虚拟地址)
S
Swap Device,交换设备, 虚拟内存管理
T
Tag, Cache
TLB,Translation Lookaside Buffer, ARM920T的CP15协处理器
Translation Table Walk, ARM920T的CP15协处理器
V
VA,Virtual Address,虚拟地址, 虚拟地址和物理地址的概念
(参见 PA,Physical Address,物理地址)
Virtual Memory Management,虚拟内存管理, 虚拟内存管理
W
Write Back, Cache(参见 Write Through)
Write Through, Cache(参见 Write Back)
1 对于32位的CPU,从CPU核这边看地址线是32条(图中只是示意性地画了4条地址线),可寻址空间是4GB,但是通常嵌入式处理器的CPU外部地址引脚不会有这么多条地址线,因为引脚是芯片上十分有限而宝贵的资源,而且也不太可能用到4GB这么大的物理内存。另一方面,在启用MMU的情况下VA地址空间和PA地址空间是完全独立的,PA地址空间既可以小于也可以大于VA地址空间,例如有些32位的服务器可以配置大于4GB的物理内存。
2 这里说Cache是用VA来索引数据的,只是针对一些嵌入式处理器,实际上大多数PC和服务器的CPU都有两级Cache,靠近CPU核的一级缓存是以VA来索引数据的,而靠近物理内存的二级缓存则是以PA来索引数据的。
3 如果读者看了[S3C2410用户手册]可能会注意到有MVA(Modified Virtual Address)这个概念,这属于ARM的快速上下文切换(Fast Context Switch)机制,适用于一些小型的RTOS,每个进程的地址空间不超过32M,Linux并没有利用快速上下文切换机制,因此在我们的讨论当中,VA和MVA不加区分,认为是相同的。
4 我们说Cache的大小是16K,是指Cache能缓存16K的内存数据,其实Cache还需要保存相应的Tag和其它标志位,其存储容量应该是大于16K的。另外,Cache的构造和内存不同,不必以字节为单位来存储,例如VA[31:5]这个Tag有27个bit,既不是3个字节也不是4个字节。
5 事实上,以上解释并不完全正确,这里还有一个更复杂的细节,启用MMU的指令在执行时,后面两条指令已经预取到CPU流水线里了,如果利用那两条指令跳转到0xc000 8110不就行了?但是流水线是靠不住的,跳转和异常都会清空流水线,[ARM参考手册]的Chapter A2详细解释了这种情况,按该手册的建议应该采用等价映射的方法解决这个问题。