linux内核链表
链表是一种常用的数据结构,它通过指针将一系列数据节点连接成一条数据链。相对于数组,链表具有更好的动态性,建立链表时无需预先知道数据总量,可以随机分配空间,可以高效地在链表中的任意位置实时插入或删除数据。链表的开销主要是访问的顺序性和组织链的空间损失。
一、链表结构
单链表结构如下:

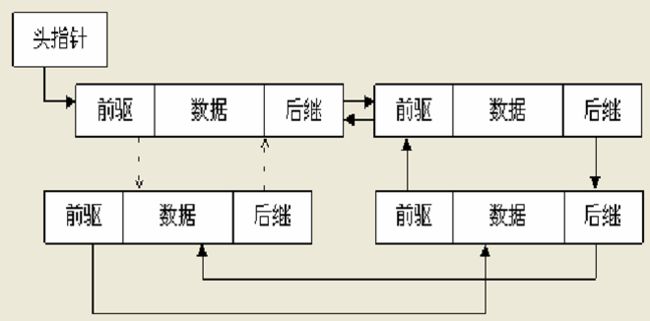
双链表结构如图:
struct list_head {
struct list_head *next, *prev;
};
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
} 初始化链表,将next、prev指针都初始化为指向自己;
三、判断链表是否为NULL
Linux用头指针的next是否指向自己来判断链表是否为空:
/**
* list_empty - tests whether a list is empty
* @head: the list to test.
*/
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}四、插入链表
对链表的插入操作有两种:在表头插入和在表尾插入。Linux为此提供了两个接口:
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);/* 在表头插入:插入在head之后 */
}
/**
* Insert a new entry before the specified head.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head); /* 在表尾插入:插入在head->prev之后 */
} 调用函数:
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}五、删除节点
static inline void list_del(struct list_head *entry)六、合并链表
/**
* list_splice - join two lists, this is designed for stacks
* @list: the new list to add.
* @head: the place to add it in the first list.
*/
static inline void list_splice(const struct list_head *list,
struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head, head->next);
}
七、移动链表
将list节点移动到链表head的头部;
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}
将list节点移动到链表head的尾部;
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}八、提取节点
#define list_entry(ptr, type, member) \ container_of(ptr, type, member)
container_of将在下一blog讲解;
九、扫描链表(遍历)
/** * list_for_each_entry - iterate over list of given type * @pos: the type * to use as a loop cursor. * @head: the head for your list. * @member: the name of the list_struct within the struct. */ #define list_for_each_entry(pos, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member); \ &pos->member != (head); \ pos = list_entry(pos->member.next, typeof(*pos), member))遍历head指向的链表,扫描的对象是链表中的元素,即member所在的pos对应的结构体;pos表示正在扫描的对象。
后续会利用函数来一一说明上述函数如何使用。
链接地址http://blog.csdn.net/iamonlyme/article/details/7172148
参考资料:
https://www.ibm.com/developerworks/cn/linux/kernel/l-chain/
linux-3.1.6内核版本