Mongodb源码分析--链接池(ConnPool)
好了,开始今天的正文吧!
首先看一下balancer类的run()方法,相关代码如下:
void Balancer::run() {
......
while ( ! inShutdown() ) { // 一直循环直到程序中断或关闭
try {
......
ScopedDbConnection conn( config );
......
conn.done(); // 将conn放到链接池中(为其它后续操作使用)
sleepsecs( _balancedLastTime ? 5 : 10 );
}
catch ( std::exception & e ) {
......
}
}
}
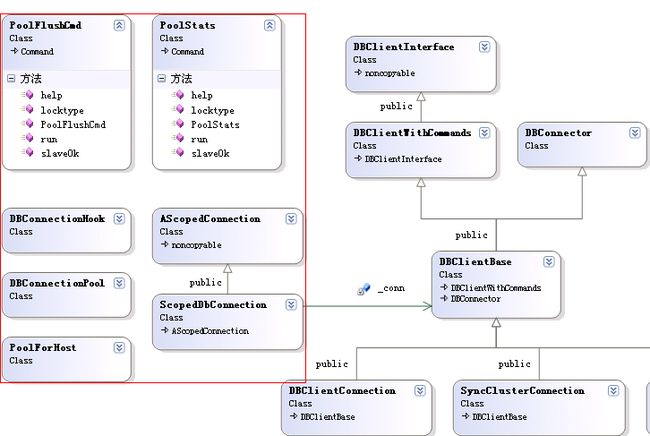
图中的红框所圈的类均为connpool.h头文件中所包含定义的类信息,而这些类中(比如ScopedDbConnection,上面代码提到过)会包含一个DBClientBase属性指针,而DBClientBase的定义位于dbclient.h头文件中,其主要是定义了客户端连接到mongodb服务端时所经常进行的操作(CRUD等)。
图中的类比较多,主要的几个包括:
DBConnectionPool:数据库链接池类,定义链接的创建,获取,flush,以及维护等操作。
PoolForHost:该对象提供以栈式(stack)方式管理pool链接对象。
下面就先看一下ScopedDbConnection的构造方法,其执行流程如下:
ScopedDbConnection::ScopedDbConnection( const Shard & shard )
: _host( shard.getConnString() ) , _conn( pool. get (_host) ) {
}
其中的_host( shard.getConnString() )只是将要链接的mongo服务地址绑定到ScopedDbConnection的_host属性上。重要的是_conn( pool.get(_host))这一行代码,它会从池中(pool类型为DBConnectionPool)获取一个链接,如池中没有则会创建一个链接并返回,如下(详情见注释):
DBClientBase * DBConnectionPool:: get ( const ConnectionString & url) {
// 从池中获取一个链接对象
DBClientBase * c = _get( url.toString() );
// 如获取到则直接返回
if ( c ) {
onHandedOut( c ); // 执行取出时定义的hook方法
return c;
}
string errmsg;
c = url.connect( errmsg );
uassert( 13328 , _name + " : connect failed " + url.toString() + " : " + errmsg , c );
// 以url为链接地址,构造一个链接对象并返回该对象
return _finishCreate( url.toString() , c );
}
上面方法中_get( url.toString() ) 这一行代码主要是用于执行从池中获取对象的操作,它的实现代码如下:
scoped_lock L(_mutex);
PoolForHost & p = _pools[ident]; // 获取指定的链接池
return p. get ();
}
其中_pools类型定义如下,用于实现从“服务器名称”到“相应链接池”的映射,因为不同的服务器会对应不同的链接池:
找到了相应的链接池之后,返回该池所对应的PoolForHost对象的引用,该对象提供以栈式(stack)方式管理pool链接对象。其get()方法定义如下:
DBClientBase * PoolForHost:: get () {
time_t now = time( 0 );
while ( ! _pool.empty() ) {
StoredConnection sc = _pool.top(); // 取出栈顶链接
_pool.pop(); // 移除栈顶的元素
if ( sc.ok( now ) ) // 如链接空闲未超过1小时
return sc.conn;
delete sc.conn; // 释放链接对象
}
return NULL; // 如无有效链接,则返回null
}
现在我们再将注意力放回到主流程DBClientBase* DBConnectionPool::get(const ConnectionString& url)方法的下面一行代码,即:
// 如获取到则直接返回
if ( c ) {
onHandedOut( c ); // 执行取出时定义的hook方法
return c;
}
该方法一个hook方法的调用,它的实现方式有些复杂,很像设置模式中的Observer (观察者)模式,我们先看一下该模式的类图:
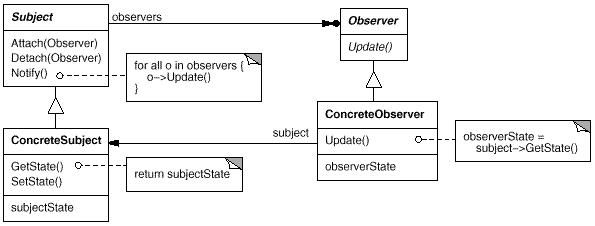
有关该模式的具体讲解可以参见相关资料或在google上搜一下,这里暂不做解释了。
这里我们先看一下该方法的具体实现(onCreate与onHandedOut方式类似,这里仅对onHandedOut进行说明):
if ( _hooks.size() == 0 )
return ;
for ( list < DBConnectionHook *> ::iterator i = _hooks.begin(); i != _hooks.end(); i ++ ) {
( * i) -> onHandedOut( conn );
}
}
可以看出,它进而面使用了for的方式,依次对conn进行onHandedOut()方法处理,而_hooks的定义如下:
// hooks列表,用于收集hook方法并(批量)执行相关方法
list < DBConnectionHook *> _hooks;
看到这里,我们有必要了解一下_hooks是如何添加相关hook对象的。还记得我在这篇文章中介绍在mongos的main()中有如下代码吗?
// set some global state
// 添加对链接池hook的绑定(shardingConnectionHook对象引用),以最终调用其onHandedOut方法
pool.addHook( & shardingConnectionHook );
// 设置链接池名称
pool.setName( " mongos connectionpool " );
对了,就是上面的addHook()方法,添加了对shardingConnectionHook的引用,而shardingConnectionHook则是对shard链接hook的具体实现,如下:
class ShardingConnectionHook : public DBConnectionHook {
public :
virtual void onHandedOut( DBClientBase * conn ) {
ClientInfo:: get () -> addShard( conn -> getServerAddress() );
}
} shardingConnectionHook;
当然这里不是对addShard及相应command命令进行分析的时候,因为mongodb有一个架构设计非常清晰的指令(command)体系,有关该方面内容我也会专门接时间来加以说明。
还是回到程序主流程上,在onHandedOut处理完之后,就可以将获取到的链接实例返回了。但如果没有可能的链接信息,那么就要创建一个链接(cs.connect( errmsg ))并将其入库,如下:
DBClientBase * DBConnectionPool::_finishCreate( const string & host , DBClientBase * conn ) {
{
scoped_lock L(_mutex);
// 获取池中相应host的PoolForHost信息并将创建的链接数(_created属性)加1
PoolForHost & p = _pools[host];
p.createdOne( conn );
}
// 调用绑定到当前pool的DBConnectionHook中的create方法(施加额外操作)
onCreate( conn );
// 调用绑定到当前pool的DBConnectionHook中的onHandedOut方法(施加额外操作)
onHandedOut( conn );
return conn;
}
在完成了这一步,链接池的就会多一个connect对象,并使用该对象来链接configServer. 而当balancer执行并相应均衡chunk操作后,会执行如下代码:
下面就是done()函数代码:
void done() {
if ( ! _conn ) // 如无效则返回
return ;
/* we could do this, but instead of assume one is using autoreconnect mode on the connection
if ( _conn->isFailed() )
kill();
else
*/
pool.release(_host, _conn); // 如有效则进行池化(添加到链接池)
_conn = 0 ;
}
// connpool.h DBConnectionPool类
void release( const string & host, DBClientBase * c) {
if ( c -> isFailed() ) { // 如链接出现异常(比如无法链到服务器),则释放
delete c;
return ;
}
scoped_lock L(_mutex);
_pools[host].done(c); // 否则将其压入链接池供其它操作使用
}
// connpool.h PoolForHost类
void PoolForHost::done( DBClientBase * c ) {
_pool.push(c);
}
好了,今天的内容就先到这里了。按照惯例,最后用一张时序图来对今天的流程做一下回顾。
原文链接:http://www.cnblogs.com/daizhj/archive/2011/06/07/mongos_connpool_source_code.html