学习笔记——数学之美番外篇:平凡而又神奇的贝叶斯方法
数学之美番外篇:平凡而又神奇的贝叶斯方法 学习笔记
http://mindhacks.cn/2008/09/21/the-magical-bayesian-method/
概率论只不过是把常识用数学公式表达了出来。
——拉普拉斯
开篇的这句话很重要,贝叶斯方法就是要看常不常见的事物,现实世界中我们能观察到的都是比较靠谱的,简单的事物,符合我们的思想,而贝叶斯中的先验概率就是描述这一点,贝叶斯估计与最大似然估计最大的区别也就是这个先验概率P(A)
The girl saw the boy with a telescope
从表述上,这句话的确存在二义性,然而仔细一想,还是偏向一种意思的几率要大一点,这就是先验概率
贝叶斯公式:
P(B|A) = P(AB) / P(A)
下面重点介绍了拼写纠正的应用:
P(h | D) ∝ P(h) * P(D | h)
P(D | h) 是编辑距离,我会单独弄一篇博文来实现拼写纠正(JAVA)
最大似然概率P(D | h) 确实也可以进行猜测正确词语,比如字母在键盘上的分布,但是考虑到正确词语在语料库中的概率,这更容易接受,符合常识
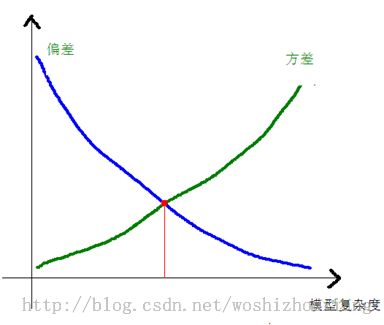
在机器学习中,数据是存在误差的,也存在一些其他因素,模型可能没有考虑到这些因素。对于模型,有比较复杂的模型,高阶的,对数据拟合度很好,偏差很小(bias),但是当数据换一组后,就拟合很差了,或者说训练误差很小,而测试误差大,而一些相对来说比较简单的模型,低阶的,对数据拟合度不如前者,偏差较大,不过数据换一组后,拟合度没变差,或者变好,或者说训练误差和测试误差相差无几,这就是模型选择中方差与偏差的权衡,一般随着模型复杂度的提高,方差会变大,不同的数据拟合度千差万遍,偏差确实变小了,于是这两个指标一个上升,一个下降,选择怎样的复杂度的模型呢,中间的,如图:
trade-off
这也是奥卡姆剃刀的一种思想:如果两个理论具有相似的解释力度,那么优先选择那个更简单的(往往也正是更平凡的,更少繁复的,更常见的)。
似然估计也是存在奥卡姆剃刀的,一个相似的似然概率肯定要大一点,一个8阶的空间生成的数据刚好是直线的,这种概率还是比较小的
从上面就可以看出似然估计本身就存在奥卡姆剃刀
贝叶斯模型可以跟信息论中的一些概念联系在一起,比如信息熵中的条件熵
H(X,Y)=H(Y)+H(X|Y)
中文分词中用到贝叶斯模型,比如:二元模型,就是当前的单词跟前面的单词有关
统计机器翻译中也用到了大量的贝叶斯公式,单词之间在某种情况下一起存在的可能性更大
不过以上两种都是在表象上进行处理的,与人类的认知过程完全不同,贝叶斯模型还是比较浅层的识别方式,更深层的识别应该参照人工智能
EM算法一般分为两部,第一步,求期望过程,根据给的参数求出某个希望求的参数的期望,这个过程相当于似然概率,第二步,把这个期望值带入,再求第一步中的参数,这个过程为贝叶斯求值过程,两步一直迭代
博文中介绍了为什么误差函数一般使用平方误差,与误差一般符合高斯分布有关
朴素贝叶斯,虽然看起来毫无道理,但是效果很好,这里面的原因可能是多方面的,比如
有正影响,也有负影响
层级贝叶斯模型:
隐马尔科夫(HMM)
以语音识别为例,当我们观测到语音信号 o1,o2,o3 时,我们要根据这组信号推测出发送的句子 s1,s2,s3。显然,我们应该在所有可能的句子中找最有可能性的一个。用数学语言来描述,就是在已知 o1,o2,o3,…的情况下,求使得条件概率 P (s1,s2,s3,…|o1,o2,o3….) 达到最大值的那个句子 s1,s2,s3,…
吴军的文章中这里省掉没说的是,s1, s2, s3, .. 这个句子的生成概率同时又取决于一组参数,这组参数决定了 s1, s2, s3, .. 这个马可夫链的先验生成概率。如果我们将这组参数记为 λ ,我们实际上要求的是:P(S|O, λ) (其中 O 表示 o1,o2,o3,.. ,S表示 s1,s2,s3,..)
当然,上面的概率不容易直接求出,于是我们可以间接地计算它。利用贝叶斯公式并且省掉一个常数项,可以把上述公式等价变换成
P(o1,o2,o3,…|s1,s2,s3….) * P(s1,s2,s3,…)
其中
P(o1,o2,o3,…|s1,s2,s3….) 表示某句话 s1,s2,s3…被读成 o1,o2,o3,…的可能性, 而 P(s1,s2,s3,…) 表示字串 s1,s2,s3,…本身能够成为一个合乎情理的句子的可能性,所以这个公式的意义是用发送信号为 s1,s2,s3…这个数列的可能性乘以 s1,s2,s3.. 本身可以一个句子的可能性,得出概率。
这里,s1,s2,s3…本身可以一个句子的可能性其实就取决于参数 λ ,也就是语言模型。所以简而言之就是发出的语音信号取决于背后实际想发出的句子,而背后实际想发出的句子本身的独立先验概率又取决于语言模型
贝叶斯网络