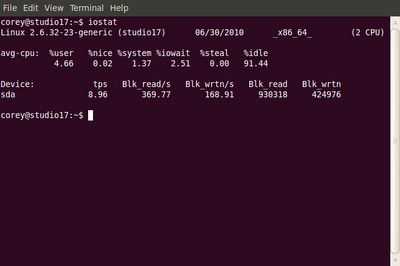
#2:vmstat -系统活动、硬件及系统信息
使用vmstat命令可以得到关于进程、内存、内存分页、堵塞IO、traps及CPU活动的信息。
#vmstat 3
输出样例:
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------ r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 2540988 522188 5130400 0 0 2 32 4 2 4 1 96 0 0 1 0 0 2540988 522188 5130400 0 0 0 720 1199 665 1 0 99 0 0 0 0 0 2540956 522188 5130400 0 0 0 0 1151 1569 4 1 95 0 0 0 0 0 2540956 522188 5130500 0 0 0 6 1117 439 1 0 99 0 0 0 0 0 2540940 522188 5130512 0 0 0 536 1189 932 1 0 98 0 0 0 0 0 2538444 522188 5130588 0 0 0 0 1187 1417 4 1 96 0 0 0 0 0 2490060 522188 5130640 0 0 0 18 1253 1123 5 1 94 0 0
显示内存使用详细信息
# vmstat -m
显示内存活动/不活动的信息
# vmstat -a
相关链接:How do I find out Linux Resource utilization to detect system bottlenecks?
译者推荐链接:Linux系统管理员必备工具系列之vmstat(原创)
#3: w - 显示谁已登录,他们正在做什么?
w命令显示系统当前用户及其运行进程的信息。
# w username
# w vivek
输出样例:
17:58:47 up 5 days, 20:28, 2 users, load average: 0.36, 0.26, 0.24 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root pts/0 10.1.3.145 14:55 5.00s 0.04s 0.02s vim /etc/resolv.conf root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
#4:uptime - 告诉系统已经运行了多久?
uptime命令过去只显示系统运行多久。现在,可以显示系统运行多久、当前有多少的用户登录、在过去的1,5,15分钟里平均负载时多少。
# uptime
输入样例:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
1可以被认为是最优的负载值。负载是会随着系统不同改变得。单CPU系统1-3和SMP系统6-10都是可能接受的。
Linux系统监控的过程中少不了对主机运行时间和系统负责等信息进行查询,这时候就可以使用Linux uptime命令。uptime命令可以显示系统运行多久、当前有多少的用户登录、在过去的1,5,15分钟里平均负载时多少,其用法十分简单。
AD:
linux uptime命令主要用于获取主机运行时间和查询linux系统负载等信息。uptime命令过去只显示系统运行多久。现在,可以显示系统已经运行了多长时间,信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
uptime命令用法十分简单:直接输入
# uptime
即可。
输入样例:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
1可以被认为是最优的负载值。负载是会随着系统不同改变得。单CPU系统1-3和SMP系统6-10都是可能接受的。
另外还有一个参数 -V ,是用来查询版本的。 (注意是大写的字母v)
[linux @ localhost]$ uptime -V
procps version 3.2.7
[linux @ localhost]$ uptime
显示结果为:
10:19:04 up 257 days, 18:56, 12 users, load average: 2.10, 2.10,2.09
显示内容说明:
10:19:04 //系统当前时间
up 257 days, 18:56 //主机已运行时间,时间越大,说明你的机器越稳定。
12 user //用户连接数,是总连接数而不是用户数
load average // 系统平均负载,统计最近1,5,15分钟的系统平均负载
那么什么是系统平均负载呢? 系统平均负载是指在特定时间间隔内运行队列中的平均进程数。
如果每个CPU内核的当前活动进程数不大于3的话,那么系统的性能是良好的。如果每个CPU内核的任务数大于5,那么这台机器的性能有严重问题。
如果你的linux主机是1个双核CPU的话,当Load Average 为6的时候说明机器已经被充分使用了。
11 strace
strace截取和记录系统进程调用,以及进程收到的信号。是一个非常有效的检测、指导和调试工具。系统管理员可以通过该命令容易地解决程序问题。
使用该命令需要指明进程的ID(PID),例如:
strace -p <pid>
图14-11 shows an example of the output of strace.
12 ulimit
ulimit内置在bash shell中,用来提供对shell和进程可用资源的控制
使用选项-a列出可以设置的所有参数:
ulimit -a

-H和-S选项指明所给资源的软硬限制。如果超过了软限制,系统管理员会收到警告信息。硬限制指在用户收到超过文件句炳限制的错误信息之前,可以达到的最大值。
例如可以设置对文件句炳的硬限制:ulimit -Hn 4096
例如可以设置对文件句炳的软限制:ulimit -Sn 1024
查看软硬值,执行如下命令:
ulimit -Hn
ulimit -Sn
例如限制Oracle用户. 在/etc/security/limits.conf输入以下行:
soft nofile 4096
hard nofile 10240
对于Red Hat Enterprise Linux AS,确定文件/etc/pam.d/system-auth包含如下行
session required /lib/security/$ISA/pam_limits.so
对于SUSE LINUX Enterprise Server,确定文件/etc/pam.d/login 和/etc/pam.d/sshd包含如下行:
session required pam_limits.so
这一行使这些限制生效。
2.使用说明
例子1:每2秒输出一条结果
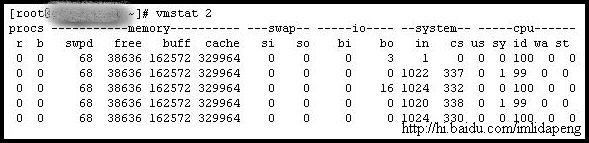
字段说明:
Procs(进程):
r: 运行队列中进程数量
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小
so: 每秒写入交换区的内存大小
IO:(现在的Linux版本块的大小为1024bytes)
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。
cs: 每秒上下文切换数。
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间)
wa: 等待IO时间
例子2:显示活跃和非活跃内存
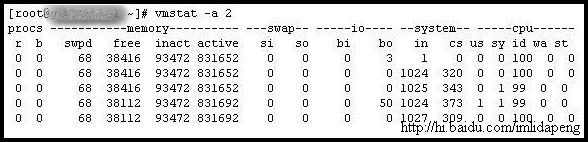
使用-a选项显示活跃和非活跃内存时,所显示的内容除增加inact和active外,其他显示内容与例子1相同。
字段说明:
Memory(内存):
inact: 非活跃内存大小(当使用-a选项时显示)
active: 活跃的内存大小(当使用-a选项时显示)
本文来源:http://hi.baidu.com/imlidapeng/blog/item/51872329329ab8335243c1c9.html
#5:ps - 显示进程
ps命令显示当前运行进程的快照。使用-A或-e显示所有进程。
# ps -A
输出样例:
PID TTY TIME CMD 1 ? 00:00:02 init 2 ? 00:00:02 migration/0 3 ? 00:00:01 ksoftirqd/0 4 ? 00:00:00 watchdog/0 5 ? 00:00:00 migration/1 6 ? 00:00:15 ksoftirqd/1 .... ..... 4881 ? 00:53:28 java 4885 tty1 00:00:00 mingetty 4886 tty2 00:00:00 mingetty 4887 tty3 00:00:00 mingetty 4888 tty4 00:00:00 mingetty 4891 tty5 00:00:00 mingetty 4892 tty6 00:00:00 mingetty 4893 ttyS1 00:00:00 agetty 12853 ? 00:00:00 cifsoplockd 12854 ? 00:00:00 cifsdnotifyd 14231 ? 00:10:34 lighttpd 14232 ? 00:00:00 php-cgi 54981 pts/0 00:00:00 vim 55465 ? 00:00:00 php-cgi 55546 ? 00:00:00 bind9-snmp-stat 55704 pts/1 00:00:00 ps
ps与top非常相似,但ps提供更多的信息。
输出长格式
# ps -Al
输出附加全格式(显示进程在执行时传入的参数)
# ps -AlF
显示进程结构
# ps -AlFH
在进程后显示线程
# ps -AlLm
打印服务器上所有进程
# ps ax
# ps axu
打印进程树
# ps -ejH
# ps axjf
# pstree
打印安全信息
# ps -eo euser,ruser,suser,fuser,f,comm,label
# ps axZ
# ps -eM
查看使用Vivek用户名运行的进程
# ps -U vivek -u vivek u
设置自定义输出格式
# ps -eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm
# ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
# ps -eopid,tt,user,fname,tmout,f,wchan
只显示Lighttpd的进程ID
# ps -C lighttpd -o pid=
或者
# pgrep lighttpd
或者
# pgrep -u vivek php-cgi
显示PID为55977的进程名称
# ps -p 55977 -o comm=
找出消耗内存最多的前10名进程
# ps -auxf | sort -nr -k 4 | head -10
找出使用CPU最多的前10名进程
# ps -auxf | sort -nr -k 3 | head -10
#6:free - 内存使用情况
free命令显示系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。
# free -m
# free -m
total used free shared buffers cached
Mem: 3939 1242 2697 0 69 583
-/+ buffers/cache: 589 3349
Swap: 5951 0 5951
# free
total used free shared buffers cached
Mem: 4033580 1272560 2761020 0 70844 597056
-/+ buffers/cache: 604660 3428920
Swap: 6094840 0 6094840
# free -k
total used free shared buffers cached
Mem: 4033580 1273320 2760260 0 70908 597056
-/+ buffers/cache: 605356 3428224
Swap: 6094840 0 6094840
# free -g
total used free shared buffers cached
Mem: 3 1 2 0 0 0
-/+ buffers/cache: 0 3
Swap: 5 0 5
前段时间有个项目的用C写的,性能测试时发现内存泄露问题。关于怎么观察内存使用问题,free是很好用的一个命令。
bash-3.00$ freetotal used free shared buffers cachedMem: 1572988 1509260 63728 0 62800 277888-/+ buffers/cache: 1168572 404416Swap: 2096472 16628 2079844
Mem:表示物理内存统计-/+ buffers/cached:表示物理内存的缓存统计Swap:表示硬盘上交换分区的使用情况,这里我们不去关心。系统的总物理内存:255268Kb(256M),但系统当前真正可用的内存b并不是第一行free 标记的 16936Kb,它仅代表未被分配的内存。第1行 Mem: total:表示物理内存总量。used:表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。free:未被分配的内存。shared:共享内存,一般系统不会用到,这里也不讨论。buffers:系统分配但未被使用的buffers 数量。cached:系统分配但未被使用的cache 数量。buffer 与cache 的区别见后面。 total = used + free 第2行 -/+ buffers/cached:used:也就是第一行中的used – buffers-cached 也是实际使用的内存总量。free:未被使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存。 free 2= buffers1 + cached1 + free1 //free2为第二行、buffers1等为第一行buffer 与cache 的区别A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and stored for later use 第3行: 第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached.
接下来解释什么时候内存会被交换,以及按什么方交换。当可用内存少于额定值的时候,就会开会进行交换.如何看额定值(RHEL4.0):#cat /proc/meminfo交换将通过三个途径来减少系统中使用的物理页面的个数:1.减少缓冲与页面cache的大小,2.将系统V类型的内存页面交换出去,3.换出或者丢弃页面。(Application 占用的内存页,也就是物理内存不足)。事实上,少量地使用swap是不是影响到系统性能的。
下面是buffers与cached的区别。buffers是指用来给块设备做的缓冲大小,他只记录文件系统的metadata以及 tracking in-flight pages.cached是用来给文件做缓冲。那就是说:buffers是用来存储,目录里面有什么内容,权限等等。而cached直接用来记忆我们打开的文件,如果你想知道他是不是真的生效,你可以试一下,先后执行两次命令#man X ,你就可以明显的感觉到第二次的开打的速度快很多。实验:在一台没有什么应用的机器上做会看得比较明显。记得实验只能做一次,如果想多做请换一个文件名。#free#man X#free#man X#free你可以先后比较一下free后显示buffers的大小。另一个实验:#free#ls /dev#free你比较一下两个的大小,当然这个buffers随时都在增加,但你有ls过的话,增加的速度会变得快,这个就是buffers/chached的区别。
因为Linux将你暂时不使用的内存作为文件和数据缓存,以提高系统性能,当你需要这些内存时,系统会自动释放(不像windows那样,即使你有很多空闲内存,他也要访问一下磁盘中的pagefiles)使用free命令将used的值减去 buffer和cache的值就是你当前真实内存使用 ————– 对操作系统来讲是Mem的参数.buffers/cached 都是属于被使用,所以它认为free只有16936.对应用程序来讲是(-/+ buffers/cach).buffers/cached 是等同可用的,因为buffer/cached是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。 所以,以应用来看看,以(-/+ buffers/cache)的free和used为主.所以我们看这个就好了.另外告诉大家 一些常识.Linux为了提高磁盘和内存存取效率, Linux做了很多精心的设计, 除了对dentry进行缓存(用于 VFS,加速文件路径名到inode的转换), 还采取了两种主要Cache方式:Buffer Cache和Page Cache。 前者针对磁盘块的读写,后者针对文件inode的读写。这些Cache能有效缩短了 I/O系统调用(比如read,write,getdents)的时间。 记住内存是拿来用的,不是拿来看的.不象windows,无论你的真实物理内存有多少,他都要拿硬盘交换 文件来读.这也就是windows为什么常常提示虚拟空间不足的原因.你们想想,多无聊,在内存还有大部分 的时候,拿出一部分硬盘空间来充当内存.硬盘怎么会快过内存.所以我们看linux,只要不用swap的交换空间,就不用担心自己的内存太少.如果常常swap用很多,可能你就要考虑加物理内存了.这也是linux看 内存是否够用的标准哦.———————————————语 法: free [-bkmotV][-s <间隔秒数>]
补充说明:free指令会显示内存的使用情况,包括实体内存,虚拟的交换文件内存,共享内存区段,以及系统核心使用的缓冲区等。
参 数:-b 以Byte为单位显示内存使用情况。-k 以KB为单位显示内存使用情况。-m 以MB为单位显示内存使用情况。-o 不显示缓冲区调节列。-s<间隔秒数> 持续观察内存使用状况。-t 显示内存总和列。-V 显示版本信息。
用途
报告虚拟内存统计信息。
语法
vmstat [ -f ] [ -i ] [ -s ] [ -I ] [ -t ] [ -v ] [ PhysicalVolume ... ] [ Interval [ Count ] ]
描述
vmstat 命令报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息。由vmstat 命令生成的报告可以用于平衡系统负载活动。系统范围内的这些统计信息(所有的处理器中)都计算出以百分比表示的平均值,或者计算其总和。
如果调用 vmstat 命令时不带标志,则报告包含系统启动后虚拟内存活动的摘要。如果指定-f 标志,则vmstat 命令报告自从系统启动后派生的数量。PhysicalVolume 参数指定物理卷的名称。
Interval 参数指定每个报告之间的时间量(以秒计)。第一个报告包含系统启动后时间的统计信息。后续报告包含自从前一个报告起的时间间隔过程中所收集的统计信息。如果没有指定Interval 参数,vmstat 命令生成单个报告然后退出。Count 参数只能和Interval 参数一起指定。如果指定了 Count 参数,其值决定生成的报告数目和相互间隔的秒数。如果Interval 参数被指定而没有Count 参数,则连续生成报告。Count 参数不允许为 0。
在 AIX 4.3.3 及更新版本包含有此方法的增强,用于计算 CPU 等待磁盘 I/O 所花时间(wio 时间)的百分比。某些情况下,AIX 4.3.2 以及该操作系统更早的版本中使用的该方法在 SMP 上会给出夸张的 wio 时间报告。
AIX 4.3.2 和更早版本中使用的方法如下:在每个处理器的每一次时钟中断(每个处理器一秒钟 100 次),确定上一个 10 毫秒时间要归入四种类别(usr/sys/wio/idle)中的哪一个。如果在时钟中断的时候,CPU 正忙于 usr 方式,那么 usr 将获取该时钟周期添加到其类别中。如果在时钟中断的时候,CPU 正忙于内核方式,那么 sys 类别获取该时钟周期。如果 CPU 不忙的话,则检测是否有磁盘 I/O 正在进行。如果有任何正在进行的磁盘 I/ O,则累加 wio 类别。如果没有磁盘 I/O 正在进行且 CPU 不忙,则 idle 类别获取该时钟周期。由于所有的空闲 CPU 都被归入 wio 类别,而不管正在等待 I/O 的线程数量,所以会产生夸大的 wio 时间报告。例如,只有一个 I/O 线程的系统可能会报告 90% 以上的 wio 时间,而不管它拥有的 CPU 数量。sar(%wio)、vmstat(wa)和iostat(% iowait)命令报告 wio 时间。
操作系统 AIX 4.3.3 及其更新版本使用的方法如下:如果一个未完成的 I/O 在空闲的 CPU 上启动,则操作系统 AIX 4.3.3 中的更改将只把该 CPU 标记成 wio。当只有少量线程在进行 I/O 而系统其它部分是空闲的,此方法能报告低得多的 wio 时间。例如,一个有四个 CPU 和一个正在进行 I/O 的线程的系统将报告最多 25% 的 wio 时间。有 12 个 CPU 和一个正在进行 I/O 的线程的系统只报告最大为 8% 的 wio 时间。NFS 客户机通过 VMM 读取/写入,biods 在 VMM 中花费的等待 I/O 完成的时间现在报告为 I/O 等待时间。
内核为内核线程、调页和中断活动维护统计信息,vmstat 命令通过使用perfstat 内核扩展来对其进行访问。磁盘输入/输出统计信息由设备驱动程序维护。对于磁盘,利用活动时间和传送信息数量来确定平均传送速率。活动时间的百分数根据报告期间驱动器忙的时间量来计算。
由 vmstat 命令生成的以下报告示例包含栏标题及其描述:
kthr:内核线程状态在采样间隔期间每秒钟更改一次。
| r |
置于运行队列中的内核线程数目。 |
| b |
置于等待队列(等待资源、等待输入/输出)的内核线程数目。 |
内存:关于使用虚拟内存和实内存的信息。如果虚拟页已经被访问的话,虚拟页可以被认为是活动的。一页为 4096 个字节。
| avm |
活动虚拟页。 |
| fre |
空闲列表的大小。
注:
大部分实内存都用作文件系统数据的高速缓存。对于保持较小的空闲列表,这是很正常的。
|
页:关于缺页故障和调页活动的信息。这些是间隔的平均值,以秒为单位给出。
| re |
页面调度程序输入/输出列表。 |
| pi |
从调页空间调度进的页面。 |
| po |
调出到调页空间的页面。 |
| fr |
释放的页(页面替换)。 |
| sr |
通过页替换算法扫描的页面。 |
| cy |
按页替换算法的时钟周期。 |
故障:采样间隔平均每秒的捕获和中断率。
| in |
设备中断 |
| sy |
系统调用。 |
| cs |
内核线程上下文切换。 |
Cpu:CPU 使用时间故障百分比。
| us |
用户时间。 |
| sy |
系统时间。 |
| id |
CPU 空闲时间。 |
| wa |
CPU 空闲时间,在此期间系统有未完成的磁盘/NFS I/O 请求。请参阅上面的详细描述。 |
磁盘:每秒向指定物理卷提供的传送数目,该过程在采样间隔中发生。PhysicalVolume 参数可以用于指定一到四个名称。每个指定驱动器的传送统计信息按指定顺序给出。该计数代表向物理设备的请求数。它并不暗示读取或写入的数据量。几个逻辑请求可以组合成为一个物理请求。
如果指定一个 -I 标志,I/O 定向视图将会出现以下栏目变化。
| kthr |
除了栏 r 和 b之外,栏p 也将显示。
-
p
-
每秒等待实际物理 I/O 的线程数。
|
| 页 |
将显示新栏 fi 和 fo,代替 re 和 cy 栏。
-
fi
-
每秒调入的文件。
-
fo
-
每秒调出的文件。
|
标志
注:
如果在命令行中输入了
-f(或
-s)标志,系统将仅接受
-f(或
-s)标志,将忽略其它标志。如果同时指定了
-f 和
-s 标志,系统将仅接受第一个标志,忽略第二个标志。
| -f |
报告从系统启动后的派生数目。 |
| -i |
显示从系统启动后每个设备造成的中断数目。 |
| -I |
用新的输出栏显示 I/O 定向视图,p 在标题 kthr 下;栏fi 和fo 在标题页面下,而不是栏下;re 和cy 在页标题中。 |
| -s |
将总数结构中的内容写入到标准输出,该结构包含从系统初始化后调页事件的绝对计数。-s 标志只能与 -v 标志一起使用。如下描述了这些事件:
-
地址翻译错误
-
每次发生地址转换页面故障时增加。解决页面故障可能需要 I/O,也可能不需要。存储保护页面故障(失去锁定)不包含在此计数之内。
-
入页
-
随虚拟内存管理器读入的每页增加。计数随调页空间和文件空间的入页增加。它和出页统计信息一起表示实际 I/O(由虚拟内存管理器启动)的总量。
-
出页
-
随虚拟内存管理器写出的每页增加。计数随调页空间和文件空间的出页而增加。它和入页统计信息一起表示实际 I/O(由虚拟内存管理器启动)的总量。
-
调页空间入页
-
只随 VMM 启动的来自调页空间的入页而增加。
-
调页空间出页
-
只随 VMM 启动的来自调页空间的出页而增加。
-
总回收
-
当不启用一个新的 I/O 请求也可以满足地址翻译错误时增加。如果页面以前已经被 VMM 请求过的,但是 I/O 还没有完成;或者页面被预读算法提前提取,但是被故障段隐藏了;或者如果页面已经被放入空闲列表中,但还没有重新使用,则会发生此情况。
-
零填充页面故障
-
如果页面故障针对的是工作存储器,且可以通过指定一个帧并以零填充帧来满足它的话,则该值增加。
-
可执行填充页面故障
-
随着每个指令页面故障而增加。
-
用时钟检查页面
-
VMM 利用时钟算法实施伪最近最少使用(1ru)的页面替换模式。时钟检查过的页面是
aged。为每个时钟检查过的页面增加此计数值。
-
时钟指针的转动
-
随着每次 VMM 时钟旋转而增加(即在每一次完整的内存扫描后)。
-
用时钟释放的页面
-
随着时钟算法从实内存中选择释放的每一个页面而增加。
|
| |
-
回溯
-
随着解决前一个页面故障时出现的每一个页面故障而增加。(必须首先解决新的页面故障,然后可以
回溯到最初的页面故障。)
-
锁定丢失
-
VMM 通过除去对页面的寻址能力来强制并发性锁定。锁定丢失可能产生一个页面故障,每当此类情况发生时,此计数增加。
-
空闲帧等待
-
在收集可用帧时,每次 VMM 等待一个进程时增加。
-
扩展 XPT 等待
-
每次正在进行提交而使得 VMM 等待一个进程时,随着正在被访问的段而增加。
-
暂挂 I/O 等待
-
每次 VMM 等待一个进程时随着要完成的入页 I/O 而增加。
-
启动 I/O
-
随着每个被 VMM 启动的读取或写入 I/O 请求而增加。此计数应该与入页和出页的总数相等。
-
iodones
-
在每次完成 VMM I/O 请求时增加。
-
CPU 上下文交换
-
随着每次 CPU 上下文交换而增加(新进程的分派)。
-
设备中断
-
每次硬件中断时增加。
-
软件中断
-
每次软件中断时增加。一次软件中断是一个类似于硬件中断(保存一些状态和服务器例程分支)的机器指令。系统调用用软件中断指令来完成,该指令转换控制到系统调用处理程序例程。
-
陷阱
-
不通过操作系统来维护。
-
syscalls
-
随着每次系统调用而增加。
|
| -t |
打印 vmstat 的每一输出行旁边的时间戳记。时间戳记按照 HH:MM:SS 格式显示。
注:
如果指定了
-f、
-s 或
-i 标志,将不打印时间戳记。
|
| -v |
将虚拟内存管理器维护的不同统计信息写入标准输出。-v 标志只能与 -s 标志一起使用。
-
内存页
-
实内存的大小(以 4 KB 的页面数目计)。
-
lruable 页
-
要用于替换的 4 KB 页面的数目。此数目不包含被用于 VMM 内部页和用于内核文本的固定部分的页面。
-
空闲页面
-
空闲 4 KB 页面的数目。
-
内存池
-
指定内存池数目的调整参数(使用
vmo 管理)。
-
固定页面
-
固定的 4 KB 页面的数目。
-
maxpin 百分比
-
指定能被固定的实内存百分数的调整参数(使用
vmo 管理)。
-
minperm 百分比
-
实内存百分比的调整参数(使用
vmo 管理)。它指定一临界点,低于此临界点时阻止页面重新调度算法使用文件页面。
-
maxperm 百分比
-
实内存百分比的调整参数(使用
vmo 管理)。它指定一临界点,高于此临界点时页面取走算法只取走文件页面。
-
numperm 百分比
-
当前由文件高速缓存使用的内存百分数。
-
文件页面
-
当前由文件高速缓存使用的 4 KB 页面的数目。
-
压缩百分比
-
由压缩页面使用的内存百分数。
-
压缩页面
-
压缩内存页面的数目。
-
numclient 百分数
-
被客户机页面占用的内存百分数。
-
maxclient 百分数
-
指定能用于客户机页面的最大内存百分数的调整参数(使用 vmo 管理)。
-
客户机页面
-
客户机页面的数目。
-
已调度的远程出页
-
调度用于客户机文件系统的出页的数目。
-
无 pbuf 而阻塞的暂挂磁盘 I/O
-
没有可用 pbuf 而阻塞的暂挂磁盘 I/O 请求的数目。Pbuf 是用于保存逻辑卷管理器层上的 I/O 请求的固定的内存缓冲区。
-
无 psbuf 而阻塞的调页空间 I/O
-
没有可用 psbuf 而阻塞的调页空间 I/O 请求的数目。Psbuf 是用于保存虚拟内存管理器层上的 I/O 请求的固定内存缓冲区。
|
| -v |
(由 -v显示的统计信息,接上页):
-
无 fsbuf 而阻塞的文件系统 I/O
-
没有可用 fsbuf 而阻塞的文件系统 I/O 请求的数目。Fsbuf 是用于保存文件系统层上的 I/O 请求的固定内存缓冲区。
-
无 fsbuf 而阻塞的客户机文件系统 I/O
-
没有可用 fsbuf 而阻塞的客户机文件系统 I/O 请求的数目。NFS(网络文件系统)和 VxFS(Veritas)是客户机文件系统。Fsbuf 是用于保存文件系统层上的 I/O 请求的固定内存缓冲区。
-
无 fsbuf 而阻塞的外部页面调度程序文件系统 I/O
-
没有可用 fsbuf 而被阻塞的外部页面调度程序客户机文件系统 I/O 请求的数目。JFS2 是一个外部页面调度程序客户机文件系统。Fsbuf 是用于保存文件系统层上的 I/O 请求的固定内存缓冲区。
|
示例
- 要显示引导后的统计信息摘要,请输入:
vmstat
- 要显示 2 秒时间间隔的 5 个摘要,请输入:
vmstat 2 5
第一次摘要包含引导后的时间统计信息。
- 要显示引导后包括逻辑磁盘 scdisk13 和 scdisk14 的统计信息摘要,请输入:
vmstat scdisk13 scdisk14
- 要显示派生统计信息,请输入:
vmstat -f
- 要显示各事件的计数,请输入:
vmstat -s
- 要显示 vmstat的每一输出栏旁边的时间戳记,请输入:
vmstat -t
- 要以另一套输出栏显示新的 I/O 定向视图,请输入:
vmstat -I
- 要显示所有可用的 VMM 统计信息,请输入:
vmstat -vs
文件
| /usr/bin/vmstat |
包含 vmstat 命令。 |
相关信息
iostat 和vmo 命令。
tcpdump采用命令行方式,它的命令格式为:
tcpdump [ -adeflnNOpqStvx ] [ -c 数量 ] [ -F 文件名 ]
[ -i 网络接口 ] [ -r 文件名] [ -s snaplen ]
[ -T 类型 ] [ -w 文件名 ] [表达式 ]
1. tcpdump的选项介绍
-a 将网络地址和广播地址转变成名字;
-d 将匹配信息包的代码以人们能够理解的汇编格式给出;
-dd 将匹配信息包的代码以c语言程序段的格式给出;
-ddd 将匹配信息包的代码以十进制的形式给出;
-e 在输出行打印出数据链路层的头部信息;
-f 将外部的Internet地址以数字的形式打印出来;
-l 使标准输出变为缓冲行形式;
-n 不把网络地址转换成名字;
-t 在输出的每一行不打印时间戳;
-v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息;
-vv 输出详细的报文信息;
-c 在收到指定的包的数目后,tcpdump就会停止;
-F 从指定的文件中读取表达式,忽略其它的表达式;
-i 指定监听的网络接口;
-r 从指定的文件中读取包(这些包一般通过-w选项产生);
-w 直接将包写入文件中,并不分析和打印出来;
-T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程
调用)和snmp(简单 网络管理协议;)
2. tcpdump的表达式介绍
表达式是一个正则表达式,tcpdump利用它作为过滤报文的条件,如果一个报文满足表
达式的条件,则这个报文将会被捕获。如果没有给出任何条件,则网络上所有的信息包将会
被截获。
在表达式中一般如下几种类型的关键字,一种是关于类型的关键字,主要包括host,
net,port, 例如 host 210.27.48.2,指明 210.27.48.2是一台主机,net 202.0.0.0 指明
202.0.0.0是一个网络地址,port 23 指明端口号是23。如果没有指定类型,缺省的类型是
host.
第二种是确定传输方向的关键字,主要包括src , dst ,dst or src, dst and src ,
这些关键字指明了传输的方向。举例说明,src 210.27.48.2 ,指明ip包中源地址是210.27.
48.2 , dst net 202.0.0.0 指明目的网络地址是202.0.0.0 。如果没有指明方向关键字,则
缺省是src or dst关键字。
第三种是协议的关键字,主要包括fddi,ip ,arp,rarp,tcp,udp等类型。Fddi指明是在
FDDI(分布式光纤数据接口网络)上的特定的网络协议,实际上它是"ether"的别名,fddi和e
ther具有类似的源地址和目的地址,所以可以将fddi协议包当作ether的包进行处理和分析。
其他的几个关键字就是指明了监听的包的协议内容。如果没有指定任何协议,则tcpdump将会
监听所有协议的信息包。
除了这三种类型的关键字之外,其他重要的关键字如下:gateway, broadcast,less,
greater,还有三种逻辑运算,取非运算是 'not ' '! ', 与运算是'and','&&';或运算 是'o
r' ,'||';
这些关键字可以组合起来构成强大的组合条件来满足人们的需要,下面举几个例子来
说明。
(1)想要截获所有210.27.48.1 的主机收到的和发出的所有的数据包:
#tcpdump host 210.27.48.1
(2) 想要截获主机210.27.48.1 和主机210.27.48.2 或210.27.48.3的通信,使用命令
:(在命令行中适用 括号时,一定要
#tcpdump host 210.27.48.1 and \ (210.27.48.2 or 210.27.48.3 \)
(3) 如果想要获取主机210.27.48.1除了和主机210.27.48.2之外所有主机通信的ip包
,使用命令:
#tcpdump ip host 210.27.48.1 and ! 210.27.48.2
(4)如果想要获取主机210.27.48.1接收或发出的telnet包,使用如下命令:
#tcpdump tcp port 23 host 210.27.48.1
3. tcpdump 的输出结果介绍
下面我们介绍几种典型的tcpdump命令的输出信息
(1) 数据链路层头信息
使用命令#tcpdump --e host ice
ice 是一台装有linux的主机,她的MAC地址是0:90:27:58:AF:1A
H219是一台装有SOLARIC的SUN工作站,它的MAC地址是8:0:20:79:5B:46;上一条
命令的输出结果如下所示:
21:50:12.847509 eth0 < 8:0:20:79:5b:46 0:90:27:58:af:1a ip 60: h219.33357 > ice.
telne
t 0:0(0) ack 22535 win 8760 (DF)
分析:21:50:12是显示的时间, 847509是ID号,eth0 <表示从网络接口eth0 接受该
数据包,eth0 >表示从网络接口设备发送数据包, 8:0:20:79:5b:46是主机H219的MAC地址,它
表明是从源地址H219发来的数据包. 0:90:27:58:af:1a是主机ICE的MAC地址,表示该数据包的
目的地址是ICE . ip 是表明该数据包是IP数据包,60 是数据包的长度, h219.33357 > ice.
telnet 表明该数据包是从主机H219的33357端口发往主机ICE的TELNET(23)端口. ack 22535
表明对序列号是222535的包进行响应. win 8760表明发送窗口的大小是8760.
(2) ARP包的TCPDUMP输出信息
使用命令#tcpdump arp
得到的输出结果是:
22:32:42.802509 eth0 > arp who-has route tell ice (0:90:27:58:af:1a)
22:32:42.802902 eth0 < arp reply route is-at 0:90:27:12:10:66 (0:90:27:58:af
:1a)
分析: 22:32:42是时间戳, 802509是ID号, eth0 >表明从主机发出该数据包, arp表明是
ARP请求包, who-has route tell ice表明是主机ICE请求主机ROUTE的MAC地址。 0:90:27:5
8:af:1a是主机ICE的MAC地址。
(3) TCP包的输出信息
用TCPDUMP捕获的TCP包的一般输出信息是:
src > dst: flags data-seqno ack window urgent options
src > dst:表明从源地址到目的地址, flags是TCP包中的标志信息,S 是SYN标志, F (F
IN), P (PUSH) , R (RST) "." (没有标记); data-seqno是数据包中的数据的顺序号, ack是
下次期望的顺序号, window是接收缓存的窗口大小, urgent表明数据包中是否有紧急指针.
Options是选项.
(4) UDP包的输出信息
用TCPDUMP捕获的UDP包的一般输出信息是:
route.port1 > ice.port2: udp lenth
UDP十分简单,上面的输出行表明从主机ROUTE的port1端口发出的一个UDP数据包到主机
ICE的port2端口,类型是UDP, 包的长度是lenth
#8:sar - 搜集和报告系统活动
sar命令用来搜集、报告和储存系统活动信息。查看网路计数器,输入:
#
sar -n DEV | more
显示最近24小时网络计数器
# sar -n DEV -f /var/log/sa/sa24 | more
你亦可以用sar显示实时情况
# sar 4 5
输出样例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:45:12 PM CPU %user %nice %system %iowait %steal %idle
06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78
06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52
06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78
06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22
06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19
Average: all 2.02 0.00 0.27 0.01 0.00 97.70
http://www.cyberciti.biz/tips/how-do-i-find-out-linux-cpu-utilization.html
#9:mpstat - 多处理器使用率
mpstat命令可以显示所有可用处理器的使用情况,处理器编号从0开始。mpstat -P ALL显示每个处理器的平均使用率。
# mpstat -P ALL
输出样例:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04
06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31
06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93
06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00
06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80
06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91
06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98
06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75
06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
相关链接: Linux display each multiple SMP CPU processors utilization individually.
#10: pmap - 进程的内存使用
pmap命令可以显示进程的内存映射,使用这个命令可以找出造成内存瓶颈的原因。
#
pmap -d PID
显示PID为47394进程的内存信息。
# pmap -d 47394
输出样例:
mapped: 933712K writeable/private: 4304K shared: 768000K
最后一行非常重要:
* mapped: 933712K 内存映射所占空间大小
* writeable/private: 4304K 私有地址空间大小
* shared: 768000K 共享地址空间大小
相关链接: Linux find the memory used by a program / process using pmap command
#11和#12: netstat和ss - 网络相关信息
netstat可以显示网络链接、路由表信息、接口统计信息、伪装链接和多播成员(multicast memberships),ss命令用来显示网络套接字信息,它允许显示类似netstat一样的信息。关于ss和netstat使用,可参考下列资源。
相关链接:
- ss: Display Linux TCP / UDP Network and Socket Information
- Get Detailed Information About Particular IP address Connections Using netstat Command
#13: iptraf - 网络实时信息
iptraf是一个可交互式的IP网络监控工具。它可以生成多种网络统计信息包括:TCP信息、UDP数量、ICMP和OSPF信息、以太网负载信息、节点状态、IP校验错误等。有下面几种信息格式:
- 不同网络TCP链接传输量
- 不同网络接口IP传输量
- 不同协议网络传输量
- 不同TCP/UDP端口和不同包大小网络传输量
- 不同第二层地址网络传输量
图02:一般接口信息:不同网络接口IP传输量
图03:不同网络TCP链接传输量
#14:tcpdump:详细的网络流量分析
tcpdump是一个简单网络流量转储工具,然而要使用好需要对TCP/IP协议非常熟悉。例如要显示关于DNS的网络流量,输入:
# tcpdump -i eth1 'udp port 53'
显示所有进出80端口IPv4 HTTP包,也就是只打印包含数据的包。例如:SYN、FIN包和ACK-only包输入:
# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
显示所有到的FTP会话,输入:
# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'
显示所有到192.168.1.5的HTTP会话
# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
用wireshark浏览转储文件中的详细信息,输入:
#tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
#15:strace - 系统调用
追踪系统调用和型号,这对于调试Web服务器和其他服务器非常有用。了解怎样追踪进程和他功能。
#16:/proc文件系统 - 各种内核信息
/proc目录下文件提供了很多不同硬件设备和内核的详细信息。更多详情参见Linux kernel /proc。一般/proc例如:
# cat /proc/cpuinfo
# cat /proc/meminfo
# cat /proc/zoneinfo
# cat /proc/mounts
#17:Nagios - 服务器及网络监控
Nagios 是一款非常流行的系统及网络监控软件。你可以轻松监控所有的主机、网络设备及服务。它能在发生故障和重新恢复后发送警讯。FAN是"Fully Automated Nagios"的缩写。FAN的目标就是由Nagios社群提供Nagios的安装。为了使安装Nagios服务器更加容易,FAN提供一个标准ISO格式的光盘镜像。此发行版中还会包含一组增强用户使用体验的工具。
#18:Cacti - 基于Web的监控工具
Cacti是一套完成的网络图形化解决方案,基于RRDTool的资料存储和图形化功能。Cacti提供一个快速的轮询器、进阶的图形化模板、多种数据采集方法和用户管理功能。这些功能都拥有非常友好易用的界面,确保可以部署在一个包含数百台设备的复杂网络中。它提供关于网络、CPU、内存、已登录用户、Apache、DNS等信息。关于怎样在CentOS / RHEL安装配置Cacti,详见:http://www.cyberciti.biz/faq/fedora-rhel-install-cacti-monitoring-rrd-software/
#19:KDE System Guard
KSysguard是在KDE桌面下一个网络化的系统监控工具。这个工具可以通过SSH会话运行。它提供很多功能,例如可以监控本机和远程主机的客户端/服务器架构,前端图形界面使用所谓传感器得到信息并展现出来。传感器返回的可以是一个简单的数值或是一组表格的信息。针对不同的信息类型,提供一个或多个显示。这些显示被组织多个工作表中,可以工作表可以独体储存和加载。所以,KSysguard不只是一个简单的任务管理器,还是一个可以控制多台服务器的强大工具。
图05:KDE System Guard
详细用法参见: the KSysguard handbook
#20:Gnome System Monitor
System Monitor可以显示系统基本信息、监控系统进程、系统资源及文件系统使用率。你也可以使用System Monitor监控和修改系统行为。尽管没有KDE System Guard功能强大,但其提供的基本信息对于入门用户还是非常有用的。
* 显示关于计算机硬件和软件的各种基本信息。
* Linux内核版本
* GNOME版本
* 硬件
* 安装的内存
* 处理器及其速度
* 系统状态
* 当前可用的硬盘空间
* 进程
* 内存及交换空间
* 网络使用率
* 文件系统
* 所有挂载的文件系统及其基本信息
图06:The Gnome System Monitor application
1.htop—— http://htop.sourceforge.net/
一个可以让用户与之交互的进程查看器。作为文本模式的应用程序,主要用于控制台或 X 终端中。当前具有按树状方式来查看进程,支持颜色主题,可以定制等特性。
2.dstat —— http://dag.wieers.com/home-made/dstat/
一个用来替换vmstat, iostat, netstat, nfsstat 和ifstat 这些命令的工具,是一个全能系统信息统计工具。
3.BMon——http://freshmeat.net/projects/bmon/
一个易于使用的软件,该软件可以帮助您监测蓝牙设备。
4.Iftop——http://www.ex-parrot.com/pdw/iftop/
主要用来显示本机网络流量情况及各相互通信的流量集合,如单独同那台机器间的流量大小,非常适合于代理服务器和iptables服务器使用
5.ifstat——http://gael.roualland.free.fr/ifstat/
一个非常不错的检测网络活动状态的软件
6.Sysstat——http://pagesperso-orange.fr/sebastien.godard/
包含监测系统性能及效率的一组工具,这些工具对于我们收集系统性能数据,比如CPU使用率、硬盘和网络吞吐数据,这些数据的收集和分析,有利于我们判断系统是否正常运行,是提高系统运行效率、安全运行服务器的得力助手。