第一章 REST简介
很多人觉得Web是理所当然存在的东西。而你,作为一名程序员,有没有认真坐下来想想为何web会变得如此成功?它怎样从研究所和学术机构的一个简单网络编程一个世界范围内联系的社区?是什么特性使得web如此流行?
有一个人,Roy Fielding,在他的博士论文“基于网络的软件架构的风格与设计”中问了这个问题,在其中,他定义了清晰的结构准则并回答了下列问题:
为何web如此流行?
什么造成了web的规模?
我可以将web架构应用在自己的程序中吗?
这一系列的架构准则被称为“表述性状态转移”,定义如下:
--可寻址的资源:REST架构中的信息与数据的关键抽象就是资源,每个资源采用必须是可寻址的URI。
--统一严格的接口:REST使用一系列良好定义的方法控制资源。
--表示性导向的:与服务交互时,你使用的其实是该服务的表示。与一个URI相关的资源可具有多种格式。不同平台需要不同的格式,举例来说,浏览器需要HTML格式,JS需要JSON(Java On Notation)格式,而一个Java应用需要XML。
--交互无状态性
--超媒体作为应用状态的引擎:让你的数据格式来驱动状态转移。
可寻址的资源
在URI中,问号参数“?”将路径与查询字串隔开。查询字串是一系列参数,以name/value对表示。每个对之间用"&"符号隔开,这是URI中的一个查询字串实例:
http://www.example.com/customers?lastname=Bruce&zipcode=02115
特定参数名可以在查询串里重复,同个参数可以有多个值。
在URI字串中,并不是所有字符都被允许的,一些字符必须按照特定格式编码。
使用唯一URI标示的每个服务使你的资源具有可连接性。资源的引用可嵌入文档甚至Email。举例来说,设想一下这个情况,有个人打给你们公司的服务台说,你们的SOA应用有个问题。那一个链接可以表示出用户遭遇的问题,用户支持部门可以将该链接发送给可以解决该问题的开发者,开发者通过点击链接,就可以检查这个问题。
更重要的是,采用URI标示每个服务,使得服务发布的数据可以轻松被组合进一个大数据流之中。
<order id="111">
<customer>http://customers.myintranet.com/customers/32133</customer>
<order-entries>
<order-entry>
<quantity>5</quantity>
<product>http://products.myintranet.com/products/111</product>
在这个例子中,该XML文档描述了一个电子商务订单实体,我们可以访问由公司不同部门提供的数据,通过访问,我们不仅可以获得相关消费者与产品的信息,而且还可以得到这个服务的唯一标示,如果我们愿意的话,还可以更进一步与这些数据交互,并操作他们。
统一、严格的接口
REST约束中统一接口的准则,恐怕对长期从事CORBA和SOAP的开发者来说是难以下咽的。这准则背后的观念是,你要把你的服务建立在仅有的几个操作之上,这意味着在你的URI中没有行为参数,而只能使用你web服务的HTTP方法。HTTP仅有少量而固定的操作方法,每个方法具有其明确的目的和意义,让我们来回顾一下:
GET:GET是个只读操作,它用查询服务器上的特定信息,同时它也是幂等和安全的操作。幂等意味着无论你实施这操作多少次,结果都一样。读一个文档并不会改变它。安全意味着GET不会改变服务器的状态,这意味着,除了请求被响应之外,GET操作不会影响服务器。
PUT:在PUT请求中,服务器存储随请求发来的消息主体,该消息会附加一个已分配地址。该请求经常用于插入和更新数据,它也是幂等的。当使用PUT请求时,客户端知道资源的唯一URI是创建还是更新,它是幂等的,因为多次发送PUT请求不会影响基础服务。这类似于微软的word文档编辑器,无论你点击保存按钮多少次,你存储的都是同一个文件。
DELETE:该请求用于删除资源,它也是幂等的。
POST:POST方法是HTTP方法中唯一一个既不幂等也不安全的。每个POST方法都被允许以一种独一无二的方式修改服务,你可能会随该请求发送信息,但也可能不会。你可能会从响应中获得信息,但也可能不会。
HEAD:HEAD方法正如GET方法所期望的那样,它返回的 仅仅是响应代码和与请求有关的头文件,而不是返回响应主体。
OPTIONS:OPTIONS用于请求资源用于交流的可选项。它允许客户端决定接不接受一个服务器的响应,以及接不接受一个不引起任何动作或数据检索的资源。
还有其他HTTP方法,比如Trace和Connect,但是他们再设计和实施RESTful web服务中不重要。
你可能已经抓狂了,然后在想:“这怎么可能只用四个方法去写一个分布式的服务?”
好吧,SQL只有四种操作,Select、insert、update和delete。JSM和其他消息驱动的中间件只有两种逻辑操作:send和receive。这些工具的力量多强大啊!对于SQL和JSM来说,交互的复杂性仅限于数据模型上,访问和操作都是良好定义和统一的,最困难的部分托付给了数据模型(在SQL中)或者消息主体(在JMS中)。
为什么统一接口是重要的?
对你的服务接口进行约束的好处远大于坏处。让我们来看些例子:
友好性:如果你有个指向服务的URI,你已清楚的知道该资源具有的方法,你不需要一个接口文件来描述可以使用哪些方法。你不需要这玩意儿,你只需要一个HTTP客户端库。如果你有这么一个文件,该文件中包含各个服务提供的数据的链接,从这些连接中你已知道该采用什么方法接受和发送数据。
协同性
HTTP是个很普遍的协议,很多编程语言都提供自己的HTTP库。所以如果你的服务是以HTTP形式暴露的话,那么想用你服务的人除了知道怎样转换服务需要的数据格式外,不需要其他多余技能就可以使用它。如果你使用CORBA或者WS,用户必须安装供应商特别的客户端库,还要下载接口文件和WSDL升级代码。你们中有多少人在让CORBA和WS协同运作的过程中遇到问题?这过程一贯是充满问题的。WS的系列规范在随着时间改变。所以,如果使用CORBA和WS,你不仅要为供应商之间的协同性担忧,还要确保你的客户端和服务器使用的是同一版本的协议。有了基于HTTP的REST,你不用再担心这些问题,只需要将注意力放在数据格式上就好了。我希望你可以去考虑真正重要的事情:应用协同性,而不是供应商之间的协同性。
可伸缩性
因为REST将你限制在一系列良好定义的方法里,你的服务拥有了可预测的行为,这些行为具有极大的性能优势。GET方式是最好的例证。当浏览网页的时候,你注意到第二次打开同个网页时速度变快了吗,这是因为浏览器已缓存了页面。HTTP具有丰富而可配置的协议去定义缓存语义。因为GET是个幂等且安全的制度方法,浏览器及HTTP代理都可缓存其服务器响应,这样可以节省很大的流量,为你的服务增加缓存语义,你会拥有极其丰富的方法为你的服务定义缓存策略。我们将在第十章讨论HTTP缓存细节。
现在还不能结束有关缓存的讨论。考虑一下PUT和DELETE,因为它们是幂等的,客户端和服务器都不用去担心递交重复消息,这将节省很多复杂代码。
表示性导向的
REST的第三个架构准则是你的服务应该是表示性导向的。通过特定URI每个服务都是可寻址的,且表示在服务器端和客户端之间来回转移。通过GET操作,你可以得到资源目前的状态,一个PUT或POST给服务器传递一个资源表示,然后就改变了下层资源状态。
在RESTful系统中,客户-服务器的交互复杂性表现在那些传来传去的表示中,这些表示可以是XML、Json、YAML、或者任何一个你能想到的格式。
在HTTP中,表示是你请求或响应的消息主体。一个HTTP消息主体可以以任何格式呈现,只要服务器与客户端愿意使用。HTTP使用Content-type头信息,告诉服务器或客户端它要接受什么格式。
Content-type头信息的值在MIME格式中,MIME格式很简单:
![]()
type是主要的格式族,而subtype是其中的一类,MIME类型有一系列的name/value值对,它们是可选属性,以”;“号结尾。
这有些值对的例子是:

一个更有趣的HTTP特性是允许服务器与客户端协商它们之间交换的信息格式,这可以改变MIME类型。内容协商对于web应用来说是个有力的工具。通过Accept头信息,客户端可以列出它们喜欢的响应格式。Ajax客户端可以请求JSON格式,Java客户端请求XML格式,Ruby请求YAML格式。另一个有用的东西是标示服务版本,同一个服务可通过请求同一个URI的同一个方法得到,它们的区别只有MIME类型。MIME类型在老服务中可能是application/vnd+xml,在新的服务中可能采用application/vnd+xml;version=1.1MIME类型来交换数据。我们将在第八章看到有关这部分概念的更多内容。
总的来说,因为REST和HTTP在可寻址性、方法选择和数据格式上,具有一系列解决方法,它是个更松耦合的协议,允许你的服务连贯的与各种不同的客户端交互。
交互无状态性
我要讨论的RESTful约束的第四个准则是无状态性,当我谈到无状态性,并不是说你的服务不能有状态,在REST中,无状态意味着在服务器端不存储客户端的会话数据,服务器只记录和管理它暴露的资源状态。如果交互时需要明确的会话数据,这些数据将被保存在客户端,并且在需要时随请求一起发送给服务器。不保存客户状态的服务器更易扩展,因为它在分布式环境中具有更小的响应开销,它更易扩展,因为你只需多增加几台机器就够了。
不难想象一个服务器不保存会话状态的世界,你只需回想12-15年前,那时许多分布式应用都具有VB或VC写成的胖客户端,将远程过程调用传递给数据库之上的一个中间件,服务器时无状态的,它只负责处理数据。胖客户端保有所有会话状态,而此架构的问题是在操作上面的。在大环境中,更新、打补丁、保持客户端交互都很困难。
web应用解决了这个问题,因为应用可以从一个中心服务器传给浏览器,然后我们开始在服务器端存储数据,因为浏览器的能力有限。而现在,大约从08年开始,ajax、Flex和java FX的流行使得浏览器已足够成熟可以保存自己的应用状态,就如同90年代中期富客户端所做的那样。我们现在可以使用过去被我们喜爱的无状态、可伸缩的中间层了。有时挺有意思的,事情只是转了个圈。
HATEOAS
最后一个REST准则是超媒体作为应用状态的引擎(Hypermedia As The Engine Of Application State)。超媒体是个以文件为中心的解决方案,它把链接嵌入其他服务和符合该文件格式的信息中。我已在第六页“可寻址性”一节中讨论过HATEOAS, 那时我们讨论了从服务获取信息的格式中使用超链接。
超媒体和超链接的其中一个用途是从不同源头中组合信息。信息可以再一个公司的内部网中,或分散在互联网上。超链接允许我们引用和聚合外部数据。第六页“可寻址性”中的商务订单案例印证了这一点:
在本例中,嵌入文档的链接允许我们根据需要加入外部信息。聚集体并不能完全描述HATEOS的概念。HATEOS中更有趣的部分是“引擎”一词。
应用状态的引擎
如果你在Amazon.com上买一本书。你跟踪一系列链接,填写了一两张表格,然后付款。通过与递交表单和跟随链接得到的响应互动,引起了订购过程的变换,服务器在购物过程中引导着你,通过嵌入浏览器中的HTML数据,指出下一步你该前往何处。
这与传统分布式应用的做法是不同的。老旧的应用通常提供一堆可用服务列表,并让用户与一个中心服务器交互,以获得定位。HATEOAS的不同之处在于,从服务器发回的每个响应都可以告诉你下步能做什么,下一步该怎样改变你的应用状态。
举例来说,假设我们希望在一个web商店里得到有货的产品列表,我们向http://example.com/webstore/products发出GET请求,并得到响应:

如果我们有成千上万个商品的话,这样的表示会给客户端带来问题。它会超载,或者在响应加载结束前会一直等待。我们可以换个做法,只显示五条商品信息,然后提供一个链接指向下一组商品:
当第一次查询商品列表的时候,客户端并不需要知道它们只得到了一个有五条商品的列表。数据格式会告诉他们还未得到全部商品列表,然后通过跟随next链接可以得到下个列表。然后得到一个含有外链的新文档:
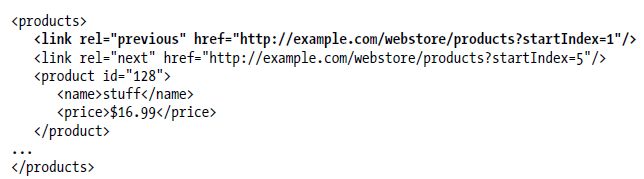
在该文档中,多了一个previous链接告诉浏览器它可以返回上一个状态。next和previous链接看起来不是很重要,不过想象一下其他的状态类型:payment、inventory或sals,情况就会不一样。
超媒体驱动赋予服务器很大的灵活性,因为状态转移的地点和途径可以被即时改变。它为浏览网页提供了新而有趣的选择,在第九章,我们将再次深入研究HATEOAS。
总括
REST风格指出了令万维网如此流行的关键架构原则。web的下一步发展是将这些原则应用于语义网和web服务的世界中。REST为创建web服务提供了一个简单、互通、灵活的方法,与传统RPC方法如CORBA和WS-*方法有很大不同,我们中的很多人都受训于RPC方法。下章我们将通过在一个业务逻辑模型基础上建造分布式REST接口来实践REST的概念。