编程珠玑(第二版)读书笔记第一章
前言:
这本书也是看了别人的博客推荐过来的一本好书,先读了文章的前言,建议我们的学习的速度不要太快,而是要认真思考每一章的东西,要仔细阅读,一次读一章。
大概翻了一下这本书,总体上感觉是比较容易接受的,讨论的问题也都是比较常见的问题,算法方面也没有用到多么高深的算法,但是最大的感触在于这本书教给了我们思考的方式,对于一个问题提出的不同的解决方案,或者从时间的优化,或者从空间上的优化,或者两者之间的一个平衡。对于一些常见的题目,给出了一些非常精巧的解法,这些解法确实是大师级的人物才能想到的,也确实受益匪浅。
第一章
关键词:Bit-Map 集合 分治法 排序
本章开头便引出这样一个问题:
一个文件最多包含一千万条记录,每条记录都是7位数的整数,并且无重复,内存只有1M,如何实现排序。
分析如下:
1.计算1千万条记录需要的内存=1000,0000 *4Byte=40M,显然内存不够,不可以一次读入进行直接排序。
2.最先想到的可用分治法,在磁盘上分批读入,然后归并排序。
3.1M内存可以存放100,0000Byte/ 4=25,0000个号码,总共1000,0000个号码,那么可以分40趟来分批排序,比如第一趟排0-249999,遍历磁盘文件,将0到249999之间 的整数读入内存进行排序,然后输出。这样带来的代价是需要40次读取磁盘文件。
4.有木有更优秀的方案,最好能一次读入所有数据,然后经过某种排序算法,一次输出最终的排序结果?
5.于是不得不想,怎么样才能将这一千万的记录存到1M的内存中呢?进一步的思考也就是能不能用大约1M=800万位去表示这一千万的记录呢?
6.Bit-Map便应运而生,看起来很牛逼的一个位图说法,其实很简单,就是用一个长度大约为800万的字符串来表示这一千万的记录,字符串的长度就是能表示的最大整数值-1,如数i存在,那么第i位为1,否则为0,说白了其实就是个集合的向量表示方法。看过算法书的人,应该对这个很了解了,就不详细说了。
7.于是乎,我们的解法也便呼之欲出,就用一个长度为800万的字符串,来表示这1千万的整数,若某个整数存在,那么对应的位就为1了,否则就为0,然后程序输出的时候遍历一下字符串,从第0位开始遍历,若为1,就输出i的值。这样就实现了,一次读入内存,经过一次排序,全部输出结果的方案了,如是第一次见Bit-Map应该是比较吃惊这种处理方式的,至少笔者我是没有想到还可以这样来搞,不得不感叹前人那些大家的智慧啊。
下面是测试的一些代码:
//BitMap -----test
#include<iostream>
#include<set>
//能表示的数的最大值
const int n = 10;
using namespace std;
int main()
{
char a[n];
int data[n];
//生成0-9不重复的数字
for(int i = 0; i < n; i++)
data[i] = i;
//将前6个随机打乱顺序
for(int i = 0; i < 6; i++)
{
int j = i + int((n - i) * (rand()/(RAND_MAX*1.0)));
swap(data[i],data[j]);
}
//打乱后数据
cout<< "打乱后的前6个数据:" << endl;
for(int i = 0; i < 6; i++)
cout << data[i] << " ";
cout << endl;
//对bitmap初始化
//初始bitmap情况
cout<< "初始bitmap情况:" << endl;
for(int i = 0; i < n; i++)
{
a[i] = 0;
cout << (a[i] == 0?"0 " : "1 ");
}
//遍历文件若对应整数存在对应位置为1
cout<< endl << "处理后的bitmap情况:" << endl;
for(int i = 0; i < 6; i++)
{
a[data[i]] = 1;
}
for(int i = 0; i < n; i++)
cout << (a[i] ==0?"0 " : "1 ");
cout << endl;
//排序
cout << "排序后前6个数据情况:" << endl;
for(int i = 0; i < n; i++)
if(a[i])cout << i << " ";
cout << endl;
system("pause");
return 0;
}
运行效果:
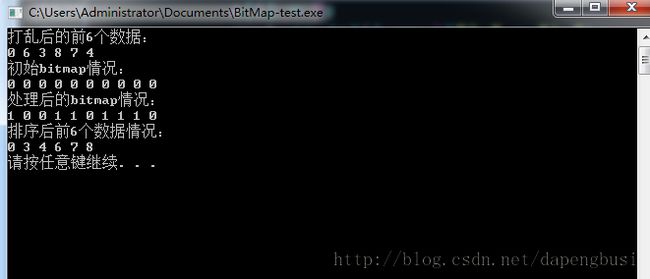
关于代码的几点说明:
- 关于随机产生某个区间的随机数处理,还有产生不重复的小于n的k(k<=n)的处理方法是个重点,后面我们还会深入讨论,若看不明白可暂且跳过。
- 这里只是为了讨论一般性,所以采用随机产生了一些数据,也可完全手工设置一些数据去测试。
- 思想确定了,但是要实现还有一段路要走,建议都去电脑上实现下,就知道作者谆谆教诲的一定要在电脑上测试下的深刻含义,只有那样才会发现更多的问题。
部分习题总结
1.如果不缺内存,如何使用一个具有库的语言来实现一种排序算法以表示和排序集合?
排序算法:qsort(a,n,sizeof(int),comp)
排序集合:stl中的set
2.如何使用位逻辑运算实现位向量?