NETDEV 协议 八
The checksum algorithm is simply to add up all the 16-bit words in one's complement and then to take the one's complement of the sum.
校验和的计算可以分为两步:累加、取反。这个划分很重要,它大大减少了校验和计算的消耗。校验和计算首要要明确一点:校验和计算是很耗时的!原因并不在于算法复杂,而是在于输入数据的庞大,试想传送500M文件,则内核要校验500M字节的数据,并且对于每个报文,都是要进行校验和。所以协议栈的校验和实现并不是简单明了的,使用了很多方法来规避这种开销。
第一:推迟校验和计算
按照协议的规定,报文到达每一层,首先验证校验和是否正确,丢弃掉不正确的报文,再才会进行后续操作。对于传输层下的协议,内核是这样做的,因为IP只需要校验IP报头,最多60字节;而对于网络层上的协议,内核就不是这样做的,ICMP/TCP/UDP都需要校验报文的内容,而这部分消耗是很大的。
以UDP为例,在报文传递到UDP处理时,它并不会去验证校验和是否正确,而是直接将报文skb插入到相应socket的接收队列sk_receive_queue中。等到真正有程序要接收这个报文,从接收队列中取出时,内核才去计算校验和。考量下这种做法,由于推迟了校验和计算,因此很多错误的报文都被接收了,它们会占用处理报文的流程,直到报文准备进入用户空间时,这时候才计算了校验和,发现错误并丢弃掉。这样看似乎平白无故增加了开销,必竟校验和的计算是一定要进行的。但这样做,将校验和计算推迟到了拷贝报文到用户空间时,这两个操作的绑定是很关键的。本来,校验和计算要遍历一次报文,而拷贝又要遍历一次报文,这样就是两次遍历操作,合并后用一次遍历搞定,它所节约的开销是远远多于额外支付的。
第二:分离校验和计算步骤
开始提到校验和的计算分为两步:累加、取反,将这两步分开后,会发现校验和是可以一部分一部分计算的,最后再用每部分计算的值求和取反。这个特性在另一方面对拷贝和校验和计算同时进行提供了支持。并且,由于报文可能是分片重组的,这样报文内容并不是一起存储在线性地址空间中,而是将分片挂在第一个分片skb的frag_list上,这部分内容是存储在非线性地址空间的。因此,拷贝会一个分片一个分片的进行,由于校验和计算的划分,它也可以一个分片一个分片的计算。csum_partial()和csum_fold()就是为此而生的,前者计算累加,后者计算取反。
所以一般校验和会这样计算,skb_checksum()计算skb的累加和,并和之前已经计算出的累加和skb->csum相加,然后csum_fold()对最后结果取反,就是得到的校验和。
第三:改进校验和计算
RFC1071中校验和计算是每16bit为单位的,但实际在累加这一步是可以调整的,内核计算是每32bit计算的,单位越大,循环就少,效率也自然会高。下面要说明的是32bit累加与16bit累加结果是一致的。
假设要计算8个字节的校验和,这8字节按每16bit分成4份:1,2,3,4。左边是每16bit累加的过程,右边是每32bit累加的过程:

会出现疑惑的地方就是累加的进位问题,左边16bit累加进位加到sum中,右边32bit累加进位也要加到sum中,至于2,4相加产生的进位,和16bit累加进位的结果是一样的。下面就是32bit累加的代码段,w>result判断是否产生了进位,假设X+Y=Z产生了进位溢
unsigned int carry = 0;
do {
unsigned int w = *(unsigned int *) buff;
count--;
buff += 4;
result += carry;
result += w;
carry = (w > result);
} while (count);
result += carry;
result = (result & 0xffff) + (result >> 16);
第四:校验和计算技巧
节省校验和最好的办法就是不计算校验和,这在某些情况下是可行的,比如大流量发包时或局域网中,这时效率比正确性更为重要。skb->ip_summed参数就是为此目的,CHECKSUM_UNNECESSARY就跳过校验和计算。或者用户在发包时设置校验和字段checksum=0,也会跳过校验和计算。
skb->ip_summed = CHECKSUM_UNNECESSARY;
另外为了加速校验和计算,很多网卡都提供了硬件计算校验和,特别的,linux使用了skb->ip_summed和skb->csum来使用硬件计算能力来帮助校验TCP/UDP报文。CHECKSUM_COMPLETE表示硬件进行了计算,计算结果存储在skb->csum中。
skb->ip_summed == CHECKSUM_COMPLETE;
在很多芯片的实现上,校验和的计算代码都是用汇编来实现了,这也是出于校验和计算的效率考虑。
最后,简单分析下校验和计算的两个核心函数。
do_csum() 校验和累加
校验和计算的主体部分是32bit为单位计算的,并假设buff起始地址是对齐过的,长度也是对齐过的。因此,传入的buff要进行处理以满足假设。
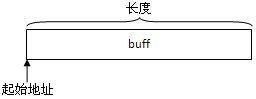
保证计算的起始地址是字节对齐
这里的对齐有16bit对齐和32bit对齐。起始地址是对齐是为了效率,比如起始地址是奇数,那么累加时用16bit或32bit就很可能跨越一个int范围,即读一个数要两次内存操作;对齐后读一个数都只用一次内存操作。
如果不是偶数字节,则odd=1,处理掉第一个字节,使超地址变成偶数。
当然处理掉第一个字节后,从buff计算校验和与从buf+1计算校验和结果显然是不同的,下面这步在校验和计算完成后,就是为了处理这种差异的。
if (odd) result = ((result >> 8) & 0xff) | ((result & 0xff) << 8);
还是以例子说明,一个5字节的buff,起始地址addr(1)=0x1,下面是传统计算和从偶数地址开始计算的对比,要注意的是累加进程中是循环进位的,即溢出的进位会加到最低位。因此,无论哪种方法,1,3,5累加进位会加到2+4中,而2,4累加进位会加到1+3+5中,这也是最后调换前后8bit的值就可以保证两者相等原因。

保证计算的长度是偶数字节
长度对齐理由很简单,累加是以16bit为单位的,因此主体部分只计算偶数字节,如果有多余的一个字节len & 1,则进行如下处理。
最后是计算的主体部分,可以看到,它并不是单纯的16bit累加,而是用32bit累加do-while循环。当然,为了进行32bit累加,要将起始地址处理成32bit对齐,长度也要处理成32bit对齐。
csum_fold() 校验和取反
取反操作很简单,~sum
在前一篇”IP协议”中对报文接收时IP层的处理进行了分析,本篇分析将针对报文发送时IP层的处理。
传输层处理完后,会调用ip_push_pending_frames()将报文传递给IP层:
ip_push_pending_frames() -> ip_local_out() -> __ip_local_out()
在ip_push_pending_frames()中,会设置第一个IP分片的报头字段,tot_len和check不会设置。
__ip_local_out():设置IP报头字节总长度tot_len,校验和check。
最后调用dst_output()发送数据给IP层,dst_output()实际调用skb_dst(skb)->output(skb),skb_dst(skb)就是skb所对应的路由项。skb_dst(skb)指向的是路由项dst_entry,它的input在收到报文时赋值ip_local_deliver(),而output在发送报文时赋值ip_output()。
return nf_hook(PF_INET, NF_INET_LOCAL_OUT, skb, NULL, skb_dst(skb)->dev, dst_output);
在IP层的调用过程如下:
ip_output() -> ip_finish_output() -> ip_finish_output2() -> hh->hh_output()
在ip_output()中,设置了dev与协议号,从IP层往下,就是以dev驱动数据传输了。
在ip_finish_output()中,判断如果报文过大,则先调用ip_fragment()进行分片(后面会对这个函数进行分析),然后调用ip_finish_output2()发送。
if (skb->len > ip_skb_dst_mtu(skb) && !skb_is_gso(skb)) return ip_fragment(skb, ip_finish_output2); else return ip_finish_output2(skb);

情况一:ip_fragment()
ip_fragment()与ip_append_data()是IP层传送报文很重要的两个函数,弄清它们之间的关系很重要。
ip_append_data()是上层构造向IP层传送数据的skb使用的,它会根据MTU值对传送数据进行分片,后续分片链在第一个分片的frag_list上;如果设备支持SG,那么同一个分片内容(当分片内容是多次输入得到的)不一定在一个线性空间上,后续输入的分片内容存在分片的frags数组中。只有第一个分片才有frag_list,而每个分片都能拥有frags。由ip_append_data()构造好的skb大致如下图所示:
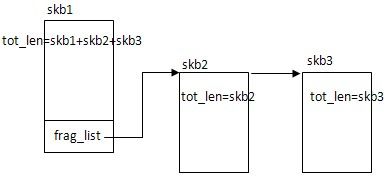
ip_fragments()字面意思是分片,但实际上分片工作已经由ip_append_data()完成了,它只在上层分片出现问题时重新进行分片。它的主要作用还是完成分片的后续工作。假设一个报文被分成了三份skb1, skb2, skb3,它们将独立的传递到网络上,但显然ip_append_data()得到的skb还不是独立的,skb1包含了整个报文的信息,分片报文也链在frag_list上;而skb2, skb3则缺少IP报头的信息,如分片的偏移,分片的标识,校验和等。ip_fragments()做的主要工作就是将skb拆分成能独立发送的报文。由ip_fragments()处理后的skb如图所示:

两张图只列出了IP报头tot_len字段的不同,其它诸如check, frag_list, frag_off等字段也是不同的。
先是对第一个分片的更新,让它脱离后续分片,成为独立包。frag_list置为空,当然frag_list得保存下来(到frag)中,后续分片要从frag_list中取出。更新skb_datalen和skb->len为第一个分片自身的值,在之前ip_append_data()处理后它是代表全部分片的值。ip报头的tot_len, frag_off和check分别设置。关于first_len的值,下面这张图可以清晰的解释(frags是支持SG的设备可能会出现的,不支持的话,skb->data_len=0):

frag = skb_shinfo(skb)->frag_list; skb_frag_list_init(skb); skb->data_len = first_len - skb_headlen(skb); skb->truesize -= truesizes; skb->len = first_len; iph->tot_len = htons(first_len); iph->frag_off = htons(IP_MF); ip_send_check(iph);
下面是循环每个分片的代码,中间省略了每个分片的处理,这部分单独拿出来说明,frag是从skb中取出的skb_shinfo(skb)->frag_list。
for (;;) {
if (frag) {
…… // 分片处理
if (err || !frag)
break;
skb = frag;
frag = skb->next;
skb->next = NULL;
}
}
对于后续分片,要生成它的IP报头,设置好其中字段,这里根据分片的排列设置了片偏移iph->frag_off,以及偏移标识(前续分片打上IP_MF标签)。ip_copy_metadata()从前一个分片中拷贝些数据,比如pkt_type, protocol, dev, priority, mark, flags等。ip_options_fragment()处理分片的IP选项部分,因为很多选项只要第一个分片有就可以了,后续分片可以去除。
frag->ip_summed = CHECKSUM_NONE; skb_reset_transport_header(frag); __skb_push(frag, hlen); skb_reset_network_header(frag); memcpy(skb_network_header(frag), iph, hlen); iph = ip_hdr(frag); iph->tot_len = htons(frag->len); ip_copy_metadata(frag, skb); if (offset == 0) ip_options_fragment(frag); offset += skb->len - hlen; iph->frag_off = htons(offset>>3); if (frag->next != NULL) iph->frag_off |= htons(IP_MF); /* Ready, complete checksum */ ip_send_check(iph);
对于每一个分片,在处理完后,调用发送函数向下发送,这里output就是ip_finish_output2()。
情况二:ip_finish_output2()
调用相应发送函数发送给下一层。有关hh和neighbour参考”ARP模块”。
if (dst->hh) return neigh_hh_output(dst->hh, skb); else if (dst->neighbour) return dst->neighbour->output(skb);
在创建邻居表项时neighbour->output()被赋值,比如收到arp报文,在arp_process() -> neigh_event_ns()中创建报文相应的邻居表项,而neigh->ops和neigh->output根据情况赋予不同的值。
if (dev->header_ops->cache) neigh->ops = &arp_hh_ops; else neigh->ops = &arp_generic_ops; if (neigh->nud_state&NUD_VALID) neigh->output = neigh->ops->connected_output; else neigh->output = neigh->ops->output;
邻居表项创建后,相应的hh缓存项并没有创建,当向邻居表项中的主机发送报文时,先调用neigh->output(),假设neigh->ops被赋值arp_generiv_ops,则neigh->output= neigh_resolve_output,而在neigh_resolve_output()函数中,会创建hh缓存项,其中hh->output= dev_queue_xmit()。
所以,无论哪种情况,hh->output还是neigh->output,最终都是调用dev_queue_xmit()向下层传送报文的。这也是IP层下传送报文的统一方式-dev_queue_xmit()。虽然调用接口相同,但IP层下的各个协议模块都是有设备的概念的,因此每个模块的设备都不相同,在每个模块中都会更换skb->dev为下层的设备,而dev_queue_xmit()最终使用的是skb->dev特定的函数进行发送的,这样实现了各模块的接口一致。
dev_queue_xmit() 发送函数
skb_needs_linearize()判断是否要对报文进行线性处理,如果需要,它返回1,由__skb_linearize()完成线性处理。线性处理就是将报文的所有内容放到线性地址空间,不能有分片的存在。在发送报文时,ip_append_data()对过长的报文进行了分片frag_list,多次添加时使用了SG特性frags(如果支持)。skb_needs_linearize()就是判断设备能否处理ip_append_data()所做的分片工作。判断条件很简单:skb有分片即frag_list,但设备不支持分片NETIF_F_FRAGLIST;skb应用了SG但设备不支持NETIF_F_SG或者是有一个分片在highmem中。最后的线性化函数__skb_linearize()也很简单,它调用__pskb_pull_tail(skb, skb->data_len),data_len就是非线性空间的长度,__pskb_pull_taill会将这部分数据拷贝到skb->data,从而完成线性化。明显看到,不支持分片的设备在做线性化处理时会多一次数据拷贝操作。
ip_summed==CHECKSUM_PARTIAL表示协议栈并没有计算完校验和,只计算了IP头,伪头等,将传输层的数据部分留给了硬件进行计算。dev_can_checksum()判断设备是否能计算校验和,如果不能的话,则skb_checksum_help()软件的计算校验和。
if (skb->ip_summed == CHECKSUM_PARTIAL) {
skb_set_transport_header(skb, skb->csum_start - skb_headroom(skb));
if (!dev_can_checksum(dev, skb) && skb_checksum_help(skb))
goto out_kfree_skb;
}
每个设备在创建时都会新建传送队列,dev->_tx。以B4401网卡创建为例,alloc_etherdev()创建的队列_tx数为1,即单队列的,dev_pick_tx()取出这个队列dev->_tx[0] -> txq中。其它支持多队列的网卡会根据skb->sk_tx_queue_mapping来选择_tx队列。
txq = dev_pick_tx(dev, skb); q = rcu_dereference_bh(txq->qdisc);
支持queue discipline(队列排序)会由q->enqueue和q->dequeue来管理队列,发送报文。支持的网卡设备则由其后的代码来处理报文发送。B4401不支持,其q->enqueue为空。
下面是不支持qdisc的网卡设备发送数据的代码段:dev->falgs & IFF_UP判断网卡是否UP状态,netif_tx_queue_stopped()判断传送队列是否在运行状态。两者满足的话,调用dev_hard_start_xmit()向下传输报文。dev_xmit_complete()检查传输结果。
if (dev->flags & IFF_UP) {
……
if (!netif_tx_queue_stopped(txq)) {
rc = dev_hard_start_xmit(skb, dev, txq);
if (dev_xmit_complete(rc)) {
HARD_TX_UNLOCK(dev, txq);
goto out;
}
}
……
}
dev_hard_start_xmit()核心语句如下,ops->nod_start_xmit()调用设备skb->dev特定的发送操作将skb向下传送,紧接检查发送值rc,更新发送状态计数。如果此时dev指向vlan设备,则ops->ndo_start_xmit()指向vlan_dev_hard_start_xmit(),它生成vlan报文,更换skb->dev,更新计数,再次调用dev_queue_xmit();如果此时dev指向网卡设备(如b4401),则ops->ndo_start_xmit()指向b44_start_xmit(),它会将数据发送物理介质。
rc = ops->ndo_start_xmit(skb, dev); if (rc == NETDEV_TX_OK) txq_trans_update(txq);
简单总结下,在不支持QDISC的网卡上,从IP层向下的传输,循环的调用dev_queue_xmit()向下层传输报文,直到最后真正的网卡设备将数据发送到物理介质上,完成报文的发送。其循环调用的图示如下:

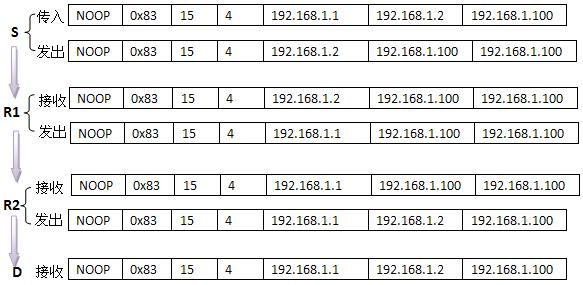
先看一个源站路由选项的例子,下文的说明都将以此为例。
主机IP:192.168.1.99
源路由:192.168.1.1 192.168.1.2 192.168.1.100[dest ip]
源站路由选项在各个主机上的情况:

该图与<TCP/IP卷一>上的示例不同,因为这里的选项[#R1, R2, D]是以实际传输中的形式标注的,下图是源站路由选项在此过程中的具体形式:
创建socket时,可以使用setsockopt()来设置创建socket的各种属性,setsockopt()最终调用系统接口sys_setsockopt()。
sys_setsockopt()
level(级别)指定系统中解释选项的代码:通用的套接口代码,或某个特定协议的代码。level==SOL_SOCKET是通用的套接口选项,即不是针对于某个协议的套接口的,使用通过函数sock_setsockopt()来设置选项;level其它值:IPPROTO_IP, IPPROTO_ICMPV6, IPPROTO_IPV6则是特定协议套接口的,使用sock->ops->setsockopt(套接字特定函数)来设置选项。
下面具体说明这个例子,生成选项 - 使用setsockopt()可以设置IP选项,形式如下:
setsockopt(fd, IPPROTO_IP, IP_OPTIONS, &opt, optlen);
其中传入的opt格式如下:

无论是何种报文(对应不同的sock),设置IP选项最终都会调用ip_setsockopt()。比如创建的UDP socket,则调用流程为:sock->ops->setsockopt() => udp_setsockopt() -> ip_setsockopt()。而处理IP选项的主要是由do_ip_setsockopt()来完成的。
do_ip_setsockopt() 处理ip选项
根据optname来决定处理何种类型的选项,决定setsockopt()中参数的optval如何解释。当是IP_OPTIONS时为IP选项,按IP选项来处理optval。
ip_options_get_from_use()根据用户传入值optval生成选项结构opt,xchg()这句将inet->opt和opt进行了交换,即将opt赋值给了inet->opt,同时将inet->opt作为结果返回。
err = ip_options_get_from_user(sock_net(sk), &opt, optval, optlen); opt = xchg(&inet->opt, opt); kfree(opt);
ip_options_get_from_user()
分配内存给IP选项,struct ip_options记录了选项相关的一些内部数据结构,最后的属性__data[0]才指向真正的IP选项。因此在分配空间时是struct ip_options大小加上optlen大小,当然,还要做4字节对齐。
分配空间后,拷贝用户设置的IP选项到opt->__data中;最后调用ip_options_get_finish()完成选项的处理,包括了用户传入选项的再处理、一些内部数据的填写,下面会进行详细讲解。
ip_options_get_finish()
选项头部的空字节用IPOPT_NOOP来补齐,选项尾部的空字节用IPOPT_END来补齐,IPOPT_NOOP和IPOPT_END都占用1字节,因此optlen递增,记录选项长度到opt中。然后调用ip_options_compile()。
while (optlen & 3) opt->__data[optlen++] = IPOPT_END; opt->optlen = optlen;
ip_options_compile()实际完成选项的处理,它在两个地方被调用:生成带IP选项的报文时被调用,此时处理的是用户传入的选项;接收带有IP选项的报文时被调用,此时处理的是报文中的IP选项,下面详细看下该函数,以LSRR选项为例子。
ip_options_compile(net, opt, NULL); kfree(*optp); *optp = opt;
ip_options_compile()
这里对应于该函数应用的两种情况:
1. 如果是生成带IP选项的报文,传入的参数skb为空(此时skb还没有创建),optptr指向opt->__data,而上面已经看到用户设置的选项在函数ip_options_get_from_user()中被拷贝到其中;
2. 如果接收到带IP选项的报文,传入skb不为空(收到报文时就创建了),optptr指向报文中IP选项的位置。iph指向IP报头的位置,当然,如果是生成选项,iph所指向的位置是没有意义的。
if (skb != NULL) {
rt = skb_rtable(skb);
optptr = (unsigned char *)&(ip_hdr(skb)[1]);
} else
optptr = opt->__data;
iph = optptr - sizeof(struct iphdr);
IP选项是按[code, len, ptr, data]这样的块排列的,每个块代表一个选项内容,多个选项可以共存,每个块4字节对齐,不足的用IPOPT_NOOP补齐。for循环处理每个选项,其中IPOPT_END和IPOPT_NOOP只是特殊的占位符,需要另外处理。然后按照选项块的格式,取出选项长度len到optlen,再根据选项的code分别进行处理,可以看到获取选项块长度的代码段在IPOPT_END和IPOPT_NOOP之后。
for (l = opt->optlen; l > 0; ) {
switch (*optptr) {
case IPOPT_END: ….
case IPOPT_NOOP: ...
…...
optlen = optptr[1];
if (optlen<2 || optlen>l) {
pp_ptr = optptr;
goto error;
}
case …...
…...// 处理代码段
}
l -= optlen;
optptr += optlen;
}
还是以宽松源路由为例子:
case IPOPT_LSRR:
首先会作一些检查,选项长度optlen不能比3小,到少有3字节的头部:code, len, ptr。指针ptr不能比4小,因为头部就有4字节。这里optlen是去除了头部的IPOPT_NOOP后的长度,而ptr的计算是包括IPOPT_NOOP的,因此一个是3一个是4;另外,选项中只能有一个源路由选项,因此当srr有值时,表示正在处理的是第二个源路由选项,则有错误。
if (optlen < 3) {
pp_ptr = optptr + 1;
goto error;
}
if (optptr[2] < 4) {
pp_ptr = optptr + 2;
goto error;
}
/* NB: cf RFC-1812 5.2.4.1 */
if (opt->srr) {
pp_ptr = optptr;
goto error;
}
当skb==NULL,对应于第一种情况(生成报文选项时);取出源路由选项的第一跳,记录到选项opt的faddr中,作为下一跳地址;源路由选项依次前移。对应于开头给出的例子,这里处理后结果如图所示:
if (!skb) {
if (optptr[2] != 4 || optlen < 7 || ((optlen-3) & 3)) {
pp_ptr = optptr + 1;
goto error;
}
memcpy(&opt->faddr, &optptr[3], 4);
if (optlen > 7)
memmove(&optptr[3], &optptr[7], optlen-7);
}
![]()
最后记录,is_strictroute是否是严格的路由选路,srr表示选项到IP报头的距离,同样,它只对处理收到的报文中选项时有效。
opt->is_strictroute = (optptr[0] == IPOPT_SSRR); opt->srr = optptr - iph;
以上是关于IP选项报文的生成,下面从ip_rcv()来看IP选项报文的接收。
ip_rcv() -> ip_rcv_finish()
ip_rcv()中重置IP的控制数据struct inet_skb_param为0,在IP章节已经说过,控制数据是skb中48字节的一个字段,在各层协议中含义不同,在IP层,它被解释为inet_skb_parm,包含opt和flags,其中前者与IP选项有关。
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
struct inet_skb_parm {
struct ip_options opt; /* Compiled IP options */
unsigned char flags;
};
ip_rcv_finish()中如果头部长度字段ihl大于4,则表示含有IP选项,此时调用ip_rcv_optins()来接收IP选项。
if (iph->ihl > 5 && ip_rcv_options(skb)) goto drop;
ip_rcv_options()
iph指向IP头;opt指向控制数据的opt,对IP选项处理的结构会存放在此,作为skb的一部分,在其它地方起作用;设置opt->optlen选项长度,这里的长度包括了开头的IPOPT_NOOP字段,是4的整数倍。
iph = ip_hdr(skb); opt = &(IPCB(skb)->opt); opt->optlen = iph->ihl*4 - sizeof(struct iphdr);
调用ip_options_compile()处理选项,这是该函数被调用的第二种情况(收到带IP选项报文时),传入参数skb是报文的skb,函数的详细说明见上文(还是以LSRR为例),实际上ip_options_compile()在这种情况下只相应设置了opt->is_strictroute和opt->srr,而不像在生成选项时对IP选项进行处理,对接收到IP选项的处理要留带到发送报文时。
if (ip_options_compile(dev_net(dev), opt, skb)) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
goto drop;
}
如果是LSRR,opt->srr在上一步中被设置,为选项到报头的距离,对于带SSRR或LSRR选项的报文来说,opt->srr值不为0,进入调用ip_options_rcv_srr()完成LSRR选项的处理。
if (unlikely(opt->srr)) {
……
if (ip_options_rcv_srr(skb))
goto drop;
}
return 0;
ip_options_rcv_srr()
该函数的主要作用是根据源站选项重新设置skb的路由项,从而改变报文的正常流程。它不会对选项进行其它操作,真正的操作在发送时完成。
首先会进行一些检查,报文的目的MAC必须是本主机,这里检查skb->pkt_type==PACKET_HOST;如果报文的目的IP不是本机(而是在本机的邻居),则本主只是源路径的一个中转站,此时不用再次查找路由表,直接返回,这里检查rt->rt_type==RTN_UNICAST,这种情况在LSRR中是允许的,SSRR是不允许的;如果报文的目的IP对本机来说不是直接可达,则错误返回。
if (skb->pkt_type != PACKET_HOST)
return -EINVAL;
if (rt->rt_type == RTN_UNICAST) {
if (!opt->is_strictroute)
return 0;
icmp_send(skb, ICMP_PARAMETERPROB, 0, htonl(16<<24));
return -EINVAL;
}
if (rt->rt_type != RTN_LOCAL)
return -EINVAL;
从LSRR选项中取出下一跳地址,记录到nexthop中,并查询路由表从saddr到nexthop的路由项,记录到skb中。如果没有这样的路由项,则返回错误;如果有这样的路由项且不是本机(如果下一跳是本机,则表示报文到达目的主机了),则break跳出循环;如果下一跳就是本机,则拷贝下一跳地址到iph->daddr中。
需要注意的是这里重新查找了一次路由表(ip_route_input)。而我们知道,在IP层会查找路由表(ip_rcv_finish函数中),它决定报文是否该被接收还是该被转发。而这里重查一次路由表也是源站选项的意义所在,IP报头中的目的地址并不是最终地址,它只决定路径中的一站,真正的目的地由选项中的值决定,因此需要根据选项中的值作为目的地址再查找一次,以便决定接下来的动作,用查找到的路由项rt2作为报文skb的路由项。
IP选项中的srr_is_hit和is_changed含义是不同的,srr_is_hit表示下一跳地址是从源路由选项中提取的,换言之,本机仍不是目的主机;is_changed表示IP报头是否被改变,被改变的话就需要重新计算IP报头的校验和(这里由于IP选项LSRR可能会改变IP报头的目的地址或选项LSRR中的值)。
if (srrptr <= srrspace) {
opt->srr_is_hit = 1;
opt->is_changed = 1;
}
根据ip_options_rcv_srr()处理的结果,即再次查询路由表的结果rt2,决定报文是进行转发还是进行接收。转发的话input=ip_forward(),表明主机只是到达目的地址的中转站;接收的话,input=ip_local_deliver(),表明主机是目的地址。
先看转发的情况,主机只是到达目的地址的中转站,调用ip_forward() -> ip_forward_finish() -> ip_forward_options(),该函数完成IP选项的处理。
ip_forward_options()
optptr指向IP选项头的位置,其中的for循环找出LSRR选项中与路由项下一跳地址rt->rt_dst相同的选项,记录在srrptr中。ip_rt_get_source()将本机地址填入LSRR选项(源站选项要求用主机的地址取代选项中的地址),然后设置IP报头的目的地址为LSRR选项中的下一跳地址,最后LSRR中指针optptr[2]右移4个字节。
还是以开头的例子为例,在主机192.168.1.2上收到来自192.168.1.1的报文,最后转发出去的报文选项如下图所示:
![]()
再看接收的情况,主机是报文的最终地址,调用ip_local_deliver()像处理正常IP报文一样处理该报文,接下来的流程与”IP协议”章节中描述的一样。最终主机192.168.1.100收到的报文选项如下图所示:
![]()
总结:
生成源站路由选项时,最后两项地址是相同的,都是192.168.1.100
源站路由实现是依靠两次路由查找改变了报文的流程
源站路由的更改需要重新计算校验和