深入理解Oracle索引(1):INDEX SKIP SCAN 和 INDEX RANGE SCAN
㈠ Index SKIP SCAN
当 表有一个复合索引,而在查询中有除了索引中第一列的其他列作为条件,并且优化器模式为CBO,这时候查询计划就有可能使用到SS
Skip scan会探测出索引前导列的唯一值个数,每个唯一值都会作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询
例如:表employees (sex, employee_id, address) ,有一个组合索引(sex, employee_id).
在索引跳跃的情况下,我们可以逻辑上把他们看成两个索引:
一个是(男,employee_id),一个是(女,employee_id).
select * from employees where employee_id=1;
发出这个查询后,oracle先进入sex为男的入口,查找employee_id=1的条目。再进入sex为女的入口,查找employee_id=1的条目。最后合并两个结果集
ORACLE官方说,在前导列唯一值较少的情况下,才会用到index skip can。这个其实好理解,就是入口要少,这也是skip scan的条件
ORACLE也承认skip scan没有直接索引查询快,但可以这样说,相比于整个表扫描(table scan),索引跳跃式扫描的速度要快得多
在Oracle9i版本之前,当SQL查询中包含sex和employee_id时,或者查询指定sex的时候才可以使用这一索引,下面的查询就不能使用索引:
select employee_id from employees where employee_id=7788;
Oracle9i的索引跳跃式扫描执行规则允许使用连接索引,即使SQL查询中不指定性别
这一特性使得无需在employee_id行中提供第二个索引
索引跳跃式扫描适用于硬盘空间和存储空间相当紧缺的情况
因为一个索引可以满足两个查询条件的使用,比单独建两个索引自然节约了空间
INDEX RANGE SCAN是范围扫描,举个例子,有1到100,分5个范围,要查询45就要到第3的范围里查,这样会很快
Index Unique Scan和Index Range Scan在B Tree上的搜索路径是一样的
只是Index Unique Scan在找到应该含有要找的Index Key的block后便停止了搜索,因为该键是唯一的
而Index Range Scan还要循着指针继续找下去直到条件不满足时
并且,Index Range Scan只是索引上的查询,与是否扫描表没有关系
如果所选择的列都在index上就不用去scan table
如果扫描到表, 必然还有一个table access by rowid,正如上例所展示的
通过index range scan访问的表可以通过按照索引顺序重新建立表来提高效率
原因有二:
① 如果你只读一部分数据,假设20% ,如果表数据顺序混乱,实际上可能把整个表都读进来了
如果表顺序和索引一致,则只需要读进 20%的表的block就够了。这是简单情况
② 复杂情况下,顺序混乱的时候 block 可能在整个查询的不同时间点多次反复访问
当再次要访问这个块的时候说不定已经被换出去了,或者被修改过了,那代价更大
而如果顺序一样,对同一个block的访问集中在一段连续的很短的时间内,变数少,不会对同一个block产生多次IO
当 表有一个复合索引,而在查询中有除了索引中第一列的其他列作为条件,并且优化器模式为CBO,这时候查询计划就有可能使用到SS
Skip scan会探测出索引前导列的唯一值个数,每个唯一值都会作为常规扫描的入口,在此基础上做一次查找,最后合并这些查询
例如:表employees (sex, employee_id, address) ,有一个组合索引(sex, employee_id).
在索引跳跃的情况下,我们可以逻辑上把他们看成两个索引:
一个是(男,employee_id),一个是(女,employee_id).
select * from employees where employee_id=1;
发出这个查询后,oracle先进入sex为男的入口,查找employee_id=1的条目。再进入sex为女的入口,查找employee_id=1的条目。最后合并两个结果集
ORACLE官方说,在前导列唯一值较少的情况下,才会用到index skip can。这个其实好理解,就是入口要少,这也是skip scan的条件
ORACLE也承认skip scan没有直接索引查询快,但可以这样说,相比于整个表扫描(table scan),索引跳跃式扫描的速度要快得多
在Oracle9i版本之前,当SQL查询中包含sex和employee_id时,或者查询指定sex的时候才可以使用这一索引,下面的查询就不能使用索引:
select employee_id from employees where employee_id=7788;
Oracle9i的索引跳跃式扫描执行规则允许使用连接索引,即使SQL查询中不指定性别
这一特性使得无需在employee_id行中提供第二个索引
索引跳跃式扫描适用于硬盘空间和存储空间相当紧缺的情况
因为一个索引可以满足两个查询条件的使用,比单独建两个索引自然节约了空间
例如:
hr@ORCL> desc t Name Null? Type ----------------------------------------------------- -------- ------------------------------------ EMPNO NOT NULL NUMBER SEX NOT NULL VARCHAR2(4) ENAME VARCHAR2(4) hr@ORCL> create index sex_empno on t (sex,empno); Index created. hr@ORCL> analyze index sex_empno compute statistics; Index analyzed. hr@ORCL> select /*+ index_ss(t) */ empno from t where empno=8; Execution Plan ---------------------------------------------------------- Plan hash value: 3008009344 ------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | 10 | 3 (0)| 00:00:01 | |* 1 | INDEX SKIP SCAN | SEX_EMPNO | 1 | 10 | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------
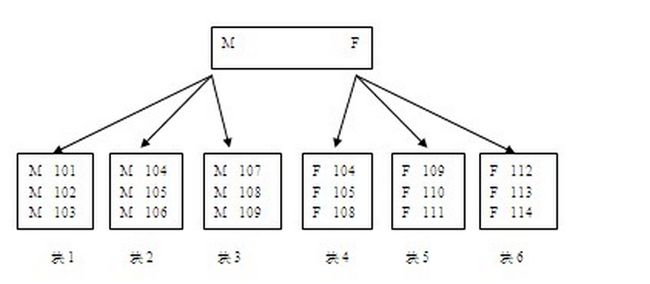
先看个图:
假如我现在要查找employee_id是109的记录,从图可以看出来,109的记录存在与块3和块5上
但是skip scan是通过什么样的方式定位到这两个块呢?
ORACLE可以在SKIP SCAN中,选择相应的入口后,通过根节点和分支节点的信息,非常精准的定位到记录的叶子块,即块3和块5.
如果要查找employee_id为109的条目,ORACLE进入到入口M后,直接就可以定位到块3.而不需要扫描块1和块2.
进入到入口F后,直接就可以定位到块5,而不需要扫描块4和块6
那么,我们上面这条查询,经过skip scan后,内部可能是:
select empno from t where sex='M' and empno=8
union
select empno from t where sex='F' and empno=8;
我们可以想象,如果索引前导列的唯一值很多,那么势必会大大削弱skip scan的效能,因为可能存在很多union
有时候为了避免index skip scan,建立新的索引是有必要的
㈡ INDEX Range Scan
INDEX Range SCAN是一种很常见的表访问方式
在INDEX Range SCAN中,Oracle访问毗邻的索引条目,然后根据索引里面的rowid去检索表的记录
例如:查询范围为80号部门里的所有员工
hr@ORCL> select JOB_ID,FIRST_NAME from employees where DEPARTMENT_ID=80; Execution Plan ---------------------------------------------------------- Plan hash value: 2056577954 ------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 34 | 646 | 4 (0)| 00:00:01 | | 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 34 | 646 | 4 (0)| 00:00:01 | |* 2 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 34 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------------------
INDEX RANGE SCAN是范围扫描,举个例子,有1到100,分5个范围,要查询45就要到第3的范围里查,这样会很快
Index Unique Scan和Index Range Scan在B Tree上的搜索路径是一样的
只是Index Unique Scan在找到应该含有要找的Index Key的block后便停止了搜索,因为该键是唯一的
而Index Range Scan还要循着指针继续找下去直到条件不满足时
并且,Index Range Scan只是索引上的查询,与是否扫描表没有关系
如果所选择的列都在index上就不用去scan table
如果扫描到表, 必然还有一个table access by rowid,正如上例所展示的
通过index range scan访问的表可以通过按照索引顺序重新建立表来提高效率
原因有二:
① 如果你只读一部分数据,假设20% ,如果表数据顺序混乱,实际上可能把整个表都读进来了
如果表顺序和索引一致,则只需要读进 20%的表的block就够了。这是简单情况
② 复杂情况下,顺序混乱的时候 block 可能在整个查询的不同时间点多次反复访问
当再次要访问这个块的时候说不定已经被换出去了,或者被修改过了,那代价更大
而如果顺序一样,对同一个block的访问集中在一段连续的很短的时间内,变数少,不会对同一个block产生多次IO