- deepseek 对于 Web 前端过去,现在,未来的看法!称未来可能不叫前端工程师...
CoderBin_
与deepseek的对话前端
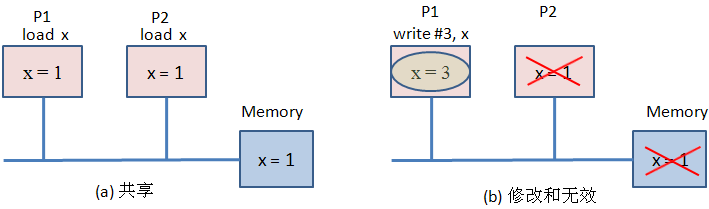
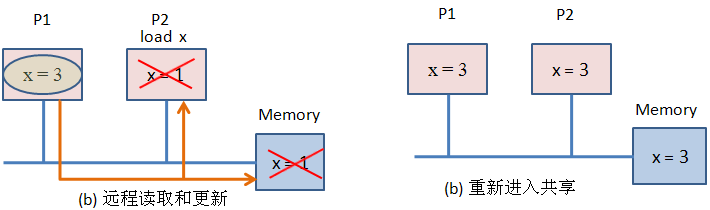
一、你对于过去的web前端有什么看法?对早期的Web前端开发(大致在2000年代至2010年代初),可以总结出以下几个关键看法:1.技术原始,但充满探索精神基础技术简单:主要依赖HTML、CSS和原生JavaScript,缺乏现代框架和工具链的支持。兼容性噩梦:不同浏览器(尤其是IE6/7)的渲染差异极大,开发者需要大量Hack代码(如条件注释、CSS滤镜)来适配。创新萌芽:AJAX(2005年)
- 微信小程序:修改提示信息placeholder颜色
25号底片~
微信小程序微信小程序小程序
方法一:使用placeholder-style直接在input或textarea组件中使用placeholder-style属性来设置placeholder的样式。或者:方法二:使用placeholder-class你也可以通过placeholder-class属性来指定一个类名,然后在对应的.wxss文件中定义这个类的样式。wxss.custom-placeholder{color:#999;f
- Apache storm
赵世炎
stormhadoop
Apachestorm是一个分布式的实时大数据处理系统。用于在容错和水平可拓展方法中处理大量数据。它是一个流数据框架,具有很高的摄取率,无状态。通过zk管理分布式环境和集群状态,并行地对实时数据执行各种操作。storm易于设置和操作,并且它保证每个消息将通过拓扑至少处理一次。基本上Hadoop和Storm框架用于分析大数据。两者互补,在某些方面有所不同。ApacheStorm执行除持久性之外的所有
- A Survey of Large Language Models大模型综述论文章节总结
WhyteHighmore
论文语言模型人工智能自然语言处理论文笔记
ASurveyofLLM人大译ASurveyofLargeLanguageModels这篇论文全面回顾了大型语言模型(LLM)的最新进展,重点关注其发展背景、关键发现和主流技术。文章主要围绕LLM的四个主要方面展开:1引言自从1950年图灵测试被提出以来,人类一直在探索机器掌握语言智能的方法。语言本质上是一种受语法规则支配的复杂、精细的人类表达系统,这使得开发能够理解和掌握语言的强大人工智能(AI
- 【etcd】
茉菇
etcd数据库
一、ETCD简介etcd是一个由CoreOS团队开发的开源项目,旨在提供一个高可用的、分布式的、一致的键值存储,用于配置共享和服务发现。尽管它看起来像一个键值存储,但etcd的设计目标远远超出了传统数据库的功能范围。etcd的核心特性包括:高可用性和容错性:etcd使用Raft共识算法来确保数据的一致性和服务的高可用性。这意味着即使集群中的某些节点出现故障,etcd也能继续提供服务,并保证数据的一
- Apache Storm实时流处理的核心技术
Hello.Reader
大数据apachestorm大数据
1.引言ApacheStorm是一个开源的、分布式的实时计算系统,专为处理流式数据而设计。它能够处理大量数据流并在极低的延迟下提供实时的结果。相比于传统的批处理系统,Storm具有处理无限数据流的能力,支持非常高的可扩展性和容错机制。Storm可以适用于多种编程语言,具有高度的灵活性。1.1什么是ApacheStorm?ApacheStorm是一个流处理引擎,它可以持续处理不断到来的数据流(str
- openai 标准化协议 Structured Outputs 具体示例教程
weixin_40941102
语言模型
StructuredOutputs具体示例教程场景:个人财务管理助手假设我们要构建一个AI助手,帮助用户记录和管理个人财务支出。用户可以输入自然语言描述(如“昨天我花了50元买了午餐”),助手将提取关键信息并以结构化JSON格式返回,包括日期、金额、类别和备注。示例1:使用StructuredOutputs提取财务记录步骤1:定义JSONSchema我们需要一个清晰的Schema来描述财务记录:{
- linux下安装卸载永中office步骤,永中集成Office For Linux安装图文指南及简介
weixin_39625975
永中集成OfficeForLinux安装图文指南及简介永中集成Office在一套标准的用户界面下集成了文字处理、电子表格和简报制作三大应用,提供自选图形、艺术字、剪贴画、图表和科教编辑器等附加功能;基于创新的数据对象储藏库专利技术,有效解决了Office各应用之间的数据集成问题,构成了一套独具特色的集成办公软件。永中集成Office用户界面和使用方式与常见Office相似,易学易用;能够双向精确兼
- 微软2012服务器qgis,12.2. 使用qgis-server 和 qgis 发布地图
12669821881
微软2012服务器qgis
12.2.2.建立wms图层¶打开qgis客户端点击图层>添加图层>添加矢量图层(图12.4)图12.4添加矢量图层¶“项目”菜单下的“项目属性”,转到“OWS服务器”选项卡(图12.5)快捷键:shiftctrlp(图12.6)图12.5建立ows服务(1)¶图12.6建立ows服务(2)¶继续向服务器添加QGIS项目,现在我们在项目中添加WMS层以将其连接到服务器,因此请转到“图层>添加图层>
- 永中office linux卸载,安装永中Office for linux
徐瑞涛
永中officelinux卸载
安装要求用户具有root的权限,如当前用户不具有root权限,可用如下方式得到:1.以具有root权限的用户重新登录。2.在终端窗口里使用suroot切换到root。3.在终端窗口里使用sudo./setup临时获得root权限,执行安装程序(这里先要进入安装程序的目录;setup是永中Office的安装可执行程序)。然后,就可以执行setup运行安装向导,依据向导提示完成安装。---------
- 计算机网络——绪论
systemyff
计算机网络网络
6个章节,外加实验和复习课时。题目来自于题库,重在理解+翻译。概述物理层链路层网络层传输层应用层复习课实验课一、计算机网络的基本概念•21世纪的一些重要特征就是数字化、网络化和信息化,是一个以网络为核心的信息时代。•网络现已成为信息社会的命脉和发展知识经济的重要基础。发展最快的并起到核心作用的是计算机网络Ø第一代以主机为中心Ø第二代以通信子网为中心Ø第三代ISO/OSI-RM、InternetØ第
- 使用Pinecone实现自查询检索器的实现步骤
vaidfl
python
##技术背景介绍Pinecone是一款功能强大的向量数据库,适用于处理复杂的检索需求。在本文中,我们将演示如何结合Pinecone向量存储使用SelfQueryRetriever实现自查询功能。为了更方便的了解原理,我们将以电影总结数据集为例进行展示。##核心原理解析自查询检索器(SelfQueryRetriever)的核心思想是通过提供文档的元数据和内容描述,结合语言模型生成查询条件来完成数据检
- AI:对比ChatGPT这类聊天机器人,人形机器人对人类有哪些不一样的影响?
InnoLink_1024
AGI人工智能机器学习chatgpt人工智能机器人
人形机器人与像ChatGPT这样的聊天机器人相比,虽然都属于人工智能技术的应用,但由于其具备的物理形态和与环境的互动能力,它们对人类的影响会有很大的不同。下面从多个角度进行对比,阐述它们各自对人类的不同影响:1.物理交互与虚拟交互人形机器人:具有物理形态,能够在物理世界中与人类进行直接交互。例如,搬运物品、进行日常家务、提供身体上的帮助(如扶持老人、帮助走路等),以及进行非语言的沟通(如手势、面部
- 芯片:CPU和GPU有什么区别?
InnoLink_1024
AGI人工智能人工智能aiagigpu算力
CPU(中央处理器)和GPU(图形处理单元)是计算机系统中两种非常重要的处理器,它们各自有不同的设计理念、架构特点以及应用领域。下面是它们之间的一些主要差异:1.设计目的与应用领域CPU:设计目的是为了处理广泛的计算任务,包括操作系统管理、应用程序运行和基本的输入输出处理等。它处理的是复杂的、通用的计算任务,通常包括控制逻辑、内存管理等。GPU:设计目的是为了处理图形和并行计算任务。最初是为图形渲
- 第十三章 Java多线程——阻塞队列
龙少丶
javajava开发语言
13.1阻塞队列的由来我们假设一种场景,生产者一直生产资源,消费者一直消费资源,资源存储在一个缓存池中,生产者将生产的资源存进缓存池中,消费者从缓存池中拿到资源进行消费,这就是大名鼎鼎的生产者-消费者模式。该模式能够简化开发过程,一方面消除了生产者与消费者类之间的代码依赖性,另方面将生产数据的过程与使用数据的过程解耦简单化负载。我们⾃⼰coding实现这个模式的时候,因为需要让多个线程操作共享变量
- 基于PyTorch和ResNet18的花卉识别实战(附完整代码)
意.远
pytorch人工智能python深度学习
一、项目背景与效果花卉分类是计算机视觉的经典任务。本文使用PyTorch框架,基于ResNet18模型实现了102种花卉的分类任务。完整代码可直接复制运行,最终验证集准确率达8.2%,文中同步分析性能瓶颈与优化方案。二、环境配置与数据准备1.环境要求#主要依赖库importtorchfromtorchimportnn,optimfromtorchvisionimporttransforms,dat
- create-react-app创建的项目中设置webpack配置
沃野_juededa
react.jswebpack前端
create-react-app创建的项目默认使用的是react-scripts(存在于node_modules文件夹中)来处理开发服务器和构建,它内置了一些webpack相关配置。一般不会暴露出来给开发者,但是在有些情况下我们需要修改下webpack默认配置,如修改outputPath、sourcemap方案等,但由于eject是不可逆的,所以craco插件应运而生,为我们提供了更好的解决方案。
- C++ 中的explicit关键字
张太行_
c++开发语言
在C++中,explicit是一个用于修饰构造函数的关键字,它主要用于防止隐式类型转换,下面从多个方面详细介绍它。基本语法explicit关键字只能用于修饰类的构造函数,其语法形式如下:classClassName{public://带有explicit修饰的构造函数explicitClassName(parameter_list);};隐式类型转换问题在没有explicit关键字时,单参数的构造
- ip link 命令总结
张太行_
tcp/ip网络网络协议
link表示linklayer的意思,即链路层。该命令用于管理和查看网络接口。iplinksetiplinksetDEVICE{up|down|arp{on|off}|nameNEWNAME|addressLLADDR}选项说明:devDEVICE:指定要操作的设备名upanddown:启动或停用该设备arponorarpoff:启用或禁用该设备的arp协议nameNAME:修改指定设备的名称,建
- iOS 模块化架构设计:主流方案与实现详解
Ethan. L
架构ios架构
随着iOS工程规模的扩大,模块化设计成为提升代码可维护性、团队协作效率和开发灵活性的关键。本文将探讨为什么需要模块化,介绍四种主流的模块化架构方案(协议抽象、依赖注入、路由机制和事件总线),并通过代码示例和对比表格帮助开发者选择适合的方案。一、为什么需要模块化?1.代码可维护性随着工程规模的增长,代码量迅速增加,模块化可以将代码拆分为独立的功能模块,降低代码复杂度,提升可维护性。2.团队协作效率模
- 推荐开源项目:Tower - 网络服务构建利器
劳治亮
推荐开源项目:Tower-网络服务构建利器towerasyncfn(Request)->Result项目地址:https://gitcode.com/gh_mirrors/to/towerTower是一个为构建强大、模块化和可重用的网络客户端和服务端组件库。这个库以其高效且易于使用的特性,为开发者提供了一种便捷的方式去构建可靠的网络应用。项目介绍Tower面向的是那些希望简化网络通信复杂性的开发者
- 使用 DingoDB 创建自查询检索器的实战演示
fgayif
python
DingoDB深入解析与实战演示DingoDB是一种分布式多模向量数据库,它结合了数据湖和向量数据库的特点,能够存储任何类型和大小的数据(如Key-Value、PDF、音频、视频等)。它具有实时低延迟处理能力,可以快速获取洞察并响应,还能高效进行即时分析和处理多模数据。在本教程中,我们将演示如何使用DingoDB向量存储来创建一个自查询检索器。技术背景介绍DingoDB的设计结合了数据湖的灵活性和
- 2023计算机组成原理考研知识点:哈佛结构
计算机考研
考研资料计算机网络哈佛结构数据结构
2023年计算机考研初试科目一般分四门,基本都考政治、英语一、数学一和计算机基础(计算机综合),报考院校不同专业课考试内容一般不同,建议考生下正式备考2023年研考时先确认报考院校计算机研招科目内容,避免无效备考。计算机组成原理:哈佛结构将指令和数据放在两个独立的存储器,允许在一个机器周期内同时获得指令和操作数,提高了执行速度。2023年计算机组成原理复习题示例(来源于网络,如有侵权,请联系删除)
- 使用 DashVector 进行高效的矢量检索和自查询检索器演示
bavDHAUO
python
在当代AI应用中,向量数据的管理和检索是至关重要的部分。DashVector是一个完全托管的向量数据库服务,提供了对高维稠密和稀疏向量的支持,允许实时插入和过滤搜索。这个服务基于DAMOAcademy自研的高效向量引擎Proxima核心构建,具备云原生和横向扩展能力,能够快速适应不同应用需求。在本篇文章中,我们将演示如何使用DashVector和SelfQueryRetriever来高效地进行矢量
- 【含文档+PPT+源码】基于微信小程序农家乐美食餐厅预约推广系统
编程毕设
微信小程序美食小程序
项目介绍本课程演示的是一款基于微信小程序农家乐美食餐厅预约推广系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Java学习者。1.包含:项目源码、项目文档、数据库脚本、软件工具等所有资料2.带你从零开始部署运行本套系统3.该项目附带的源码资料可作为毕设使用该系统功能架构图如下:技术栈说明技术栈:后端:SpringBoot+Vue+ElementUI(后端是前后端分离的)前端:Un
- 【H2O2 | 软件开发】前端深拷贝的实现
过期的H2O2
【H2O2】全栈面试题javascript开发语言ecmascript前端
目录前言开篇语准备工作正文概述JSON方法递归其他结束语前言开篇语本系列为短篇,每次讲述少量知识点,无需一次性灌输太多的新知识点。该主题文章主要是围绕前端、全栈开发相关面试常见问题撰写的,希望对诸位有所帮助。如果您需要为面试八股文做准备,笔者建议重点关注加粗强调部分,它们是概念中的关键词。准备工作软件:【参考版本】VisualStudioCode系统版本:Win10/11正文概述概括地来说,前端实
- 嵌入式知识笔记1——C++面试复习(3)
Yuanyingbian
嵌入式学习资料笔记c++算法
四、关键字库函数4.1sizeof和strlen的区别strlen是头文件中的函数,sizeof是C++中的运算符。strlen测量的是字符串的实际长度(其源代码如下),以\0结束。而sizeof测量的是字符数组的分配大小。strlen本身是库函数,因此在程序运行过程中,计算长度;而sizeof在编译时,计算长度;sizeof的参数可以是类型,也可以是变量;strlen的参数必须是char*类型的
- Python 模拟鼠标轨迹算法
a485240
鼠标轨迹计算机外设
一.鼠标轨迹模拟简介传统的鼠标轨迹模拟依赖于简单的数学模型,如直线或曲线路径。然而,这种方法难以捕捉到人类操作的复杂性和多样性。AI大模型的出现,使得能够通过深度学习技术,学习并模拟更自然的鼠标移动行为。二.鼠标轨迹算法实现AI大模型通过学习大量的人类鼠标操作数据,能够识别和模拟出自然且具有个体差异的鼠标轨迹。以下是实现这一技术的关键步骤:数据收集:收集不同玩家在各种游戏环境中的鼠标操作数据,包括
- vue中ref解析
肉肉不吃 肉
vue.jsjavascript前端
在Vue项目中,ref是一个非常重要的概念,用于创建对DOM元素或组件实例的引用。它在多种场景下都非常有用,特别是在需要直接操作DOM或与子组件进行交互时。ref的作用1.获取DOM元素使用ref可以获取到模板中的DOM元素,并对其进行操作。创建了一个对组件的引用,可以在脚本中通过loginForm.value访问该元素。示例:constloginForm=ref(null)//在setup函数中
- 什么是Apache Avro?
maozexijr
apache
什么是ApacheAvro?ApacheAvro是一个开源的数据序列化框架,主要用于高效的数据交换和存储。它由ApacheHadoop项目开发,广泛应用于大数据生态系统中(如Hadoop、Kafka等)。Avro提供了一种紧凑、快速的二进制数据格式,同时支持丰富的数据结构和模式演化。核心特性跨语言支持Avro支持多种编程语言(如Java、Python、C++、Go等),使得不同语言之间的数据交换变
- 集合框架
天子之骄
java数据结构集合框架
集合框架
集合框架可以理解为一个容器,该容器主要指映射(map)、集合(set)、数组(array)和列表(list)等抽象数据结构。
从本质上来说,Java集合框架的主要组成是用来操作对象的接口。不同接口描述不同的数据类型。
简单介绍:
Collection接口是最基本的接口,它定义了List和Set,List又定义了LinkLi
- Table Driven(表驱动)方法实例
bijian1013
javaenumTable Driven表驱动
实例一:
/**
* 驾驶人年龄段
* 保险行业,会对驾驶人的年龄做年龄段的区分判断
* 驾驶人年龄段:01-[18,25);02-[25,30);03-[30-35);04-[35,40);05-[40,45);06-[45,50);07-[50-55);08-[55,+∞)
*/
public class AgePeriodTest {
//if...el
- Jquery 总结
cuishikuan
javajqueryAjaxWebjquery方法
1.$.trim方法用于移除字符串头部和尾部多余的空格。如:$.trim(' Hello ') // Hello2.$.contains方法返回一个布尔值,表示某个DOM元素(第二个参数)是否为另一个DOM元素(第一个参数)的下级元素。如:$.contains(document.documentElement, document.body); 3.$
- 面向对象概念的提出
麦田的设计者
java面向对象面向过程
面向对象中,一切都是由对象展开的,组织代码,封装数据。
在台湾面向对象被翻译为了面向物件编程,这充分说明了,这种编程强调实体。
下面就结合编程语言的发展史,聊一聊面向过程和面向对象。
c语言由贝尔实
- linux网口绑定
被触发
linux
刚在一台IBM Xserver服务器上装了RedHat Linux Enterprise AS 4,为了提高网络的可靠性配置双网卡绑定。
一、环境描述
我的RedHat Linux Enterprise AS 4安装双口的Intel千兆网卡,通过ifconfig -a命令看到eth0和eth1两张网卡。
二、双网卡绑定步骤:
2.1 修改/etc/sysconfig/network
- XML基础语法
肆无忌惮_
xml
一、什么是XML?
XML全称是Extensible Markup Language,可扩展标记语言。很类似HTML。XML的目的是传输数据而非显示数据。XML的标签没有被预定义,你需要自行定义标签。XML被设计为具有自我描述性。是W3C的推荐标准。
二、为什么学习XML?
用来解决程序间数据传输的格式问题
做配置文件
充当小型数据库
三、XML与HTM
- 为网页添加自己喜欢的字体
知了ing
字体 秒表 css
@font-face {
font-family: miaobiao;//定义字体名字
font-style: normal;
font-weight: 400;
src: url('font/DS-DIGI-e.eot');//字体文件
}
使用:
<label style="font-size:18px;font-famil
- redis范围查询应用-查找IP所在城市
矮蛋蛋
redis
原文地址:
http://www.tuicool.com/articles/BrURbqV
需求
根据IP找到对应的城市
原来的解决方案
oracle表(ip_country):
查询IP对应的城市:
1.把a.b.c.d这样格式的IP转为一个数字,例如为把210.21.224.34转为3524648994
2. select city from ip_
- 输入两个整数, 计算百分比
alleni123
java
public static String getPercent(int x, int total){
double result=(x*1.0)/(total*1.0);
System.out.println(result);
DecimalFormat df1=new DecimalFormat("0.0000%");
- 百合——————>怎么学习计算机语言
百合不是茶
java 移动开发
对于一个从没有接触过计算机语言的人来说,一上来就学面向对象,就算是心里上面接受的了,灵魂我觉得也应该是跟不上的,学不好是很正常的现象,计算机语言老师讲的再多,你在课堂上面跟着老师听的再多,我觉得你应该还是学不会的,最主要的原因是你根本没有想过该怎么来学习计算机编程语言,记得大一的时候金山网络公司在湖大招聘我们学校一个才来大学几天的被金山网络录取,一个刚到大学的就能够去和
- linux下tomcat开机自启动
bijian1013
tomcat
方法一:
修改Tomcat/bin/startup.sh 为:
export JAVA_HOME=/home/java1.6.0_27
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:.
export PATH=$JAVA_HOME/bin:$PATH
export CATALINA_H
- spring aop实例
bijian1013
javaspringAOP
1.AdviceMethods.java
package com.bijian.study.spring.aop.schema;
public class AdviceMethods {
public void preGreeting() {
System.out.println("--how are you!--");
}
}
2.beans.x
- [Gson八]GsonBuilder序列化和反序列化选项enableComplexMapKeySerialization
bit1129
serialization
enableComplexMapKeySerialization配置项的含义
Gson在序列化Map时,默认情况下,是调用Key的toString方法得到它的JSON字符串的Key,对于简单类型和字符串类型,这没有问题,但是对于复杂数据对象,如果对象没有覆写toString方法,那么默认的toString方法将得到这个对象的Hash地址。
GsonBuilder用于
- 【Spark九十一】Spark Streaming整合Kafka一些值得关注的问题
bit1129
Stream
包括Spark Streaming在内的实时计算数据可靠性指的是三种级别:
1. At most once,数据最多只能接受一次,有可能接收不到
2. At least once, 数据至少接受一次,有可能重复接收
3. Exactly once 数据保证被处理并且只被处理一次,
具体的多读几遍http://spark.apache.org/docs/lates
- shell脚本批量检测端口是否被占用脚本
ronin47
#!/bin/bash
cat ports |while read line
do#nc -z -w 10 $line
nc -z -w 2 $line 58422>/dev/null2>&1if[ $?-eq 0]then
echo $line:ok
else
echo $line:fail
fi
done
这里的ports 既可以是文件
- java-2.设计包含min函数的栈
bylijinnan
java
具体思路参见:http://zhedahht.blog.163.com/blog/static/25411174200712895228171/
import java.util.ArrayList;
import java.util.List;
public class MinStack {
//maybe we can use origin array rathe
- Netty源码学习-ChannelHandler
bylijinnan
javanetty
一般来说,“有状态”的ChannelHandler不应该是“共享”的,“无状态”的ChannelHandler则可“共享”
例如ObjectEncoder是“共享”的, 但 ObjectDecoder 不是
因为每一次调用decode方法时,可能数据未接收完全(incomplete),
它与上一次decode时接收到的数据“累计”起来才有可能是完整的数据,是“有状态”的
p
- java生成随机数
cngolon
java
方法一:
/**
* 生成随机数
* @author
[email protected]
* @return
*/
public synchronized static String getChargeSequenceNum(String pre){
StringBuffer sequenceNum = new StringBuffer();
Date dateTime = new D
- POI读写海量数据
ctrain
海量数据
import java.io.FileOutputStream;
import java.io.OutputStream;
import org.apache.poi.xssf.streaming.SXSSFRow;
import org.apache.poi.xssf.streaming.SXSSFSheet;
import org.apache.poi.xssf.streaming
- mysql 日期格式化date_format详细使用
daizj
mysqldate_format日期格式转换日期格式化
日期转换函数的详细使用说明
DATE_FORMAT(date,format) Formats the date value according to the format string. The following specifiers may be used in the format string. The&n
- 一个程序员分享8年的开发经验
dcj3sjt126com
程序员
在中国有很多人都认为IT行为是吃青春饭的,如果过了30岁就很难有机会再发展下去!其实现实并不是这样子的,在下从事.NET及JAVA方面的开发的也有8年的时间了,在这里在下想凭借自己的亲身经历,与大家一起探讨一下。
明确入行的目的
很多人干IT这一行都冲着“收入高”这一点的,因为只要学会一点HTML, DIV+CSS,要做一个页面开发人员并不是一件难事,而且做一个页面开发人员更容
- android欢迎界面淡入淡出效果
dcj3sjt126com
android
很多Android应用一开始都会有一个欢迎界面,淡入淡出效果也是用得非常多的,下面来实现一下。
主要代码如下:
package com.myaibang.activity;
import android.app.Activity;import android.content.Intent;import android.os.Bundle;import android.os.CountDown
- linux 复习笔记之常见压缩命令
eksliang
tar解压linux系统常见压缩命令linux压缩命令tar压缩
转载请出自出处:http://eksliang.iteye.com/blog/2109693
linux中常见压缩文件的拓展名
*.gz gzip程序压缩的文件
*.bz2 bzip程序压缩的文件
*.tar tar程序打包的数据,没有经过压缩
*.tar.gz tar程序打包后,并经过gzip程序压缩
*.tar.bz2 tar程序打包后,并经过bzip程序压缩
*.zi
- Android 应用程序发送shell命令
gqdy365
android
项目中需要直接在APP中通过发送shell指令来控制lcd灯,其实按理说应该是方案公司在调好lcd灯驱动之后直接通过service送接口上来给APP,APP调用就可以控制了,这是正规流程,但我们项目的方案商用的mtk方案,方案公司又没人会改,只调好了驱动,让应用程序自己实现灯的控制,这不蛋疼嘛!!!!
发就发吧!
一、关于shell指令:
我们知道,shell指令是Linux里面带的
- java 无损读取文本文件
hw1287789687
读取文件无损读取读取文本文件charset
java 如何无损读取文本文件呢?
以下是有损的
@Deprecated
public static String getFullContent(File file, String charset) {
BufferedReader reader = null;
if (!file.exists()) {
System.out.println("getFull
- Firebase 相关文章索引
justjavac
firebase
Awesome Firebase
最近谷歌收购Firebase的新闻又将Firebase拉入了人们的视野,于是我做了这个 github 项目。
Firebase 是一个数据同步的云服务,不同于 Dropbox 的「文件」,Firebase 同步的是「数据」,服务对象是网站开发者,帮助他们开发具有「实时」(Real-Time)特性的应用。
开发者只需引用一个 API 库文件就可以使用标准 RE
- C++学习重点
lx.asymmetric
C++笔记
1.c++面向对象的三个特性:封装性,继承性以及多态性。
2.标识符的命名规则:由字母和下划线开头,同时由字母、数字或下划线组成;不能与系统关键字重名。
3.c++语言常量包括整型常量、浮点型常量、布尔常量、字符型常量和字符串性常量。
4.运算符按其功能开以分为六类:算术运算符、位运算符、关系运算符、逻辑运算符、赋值运算符和条件运算符。
&n
- java bean和xml相互转换
q821424508
javabeanxmlxml和bean转换java bean和xml转换
这几天在做微信公众号
做的过程中想找个java bean转xml的工具,找了几个用着不知道是配置不好还是怎么回事,都会有一些问题,
然后脑子一热谢了一个javabean和xml的转换的工具里,自己用着还行,虽然有一些约束吧 ,
还是贴出来记录一下
顺便你提一下下,这个转换工具支持属性为集合、数组和非基本属性的对象。
packag
- C 语言初级 位运算
1140566087
位运算c
第十章 位运算 1、位运算对象只能是整形或字符型数据,在VC6.0中int型数据占4个字节 2、位运算符: 运算符 作用 ~ 按位求反 << 左移 >> 右移 & 按位与 ^ 按位异或 | 按位或 他们的优先级从高到低; 3、位运算符的运算功能: a、按位取反: ~01001101 = 101
- 14点睛Spring4.1-脚本编程
wiselyman
spring4
14.1 Scripting脚本编程
脚本语言和java这类静态的语言的主要区别是:脚本语言无需编译,源码直接可运行;
如果我们经常需要修改的某些代码,每一次我们至少要进行编译,打包,重新部署的操作,步骤相当麻烦;
如果我们的应用不允许重启,这在现实的情况中也是很常见的;
在spring中使用脚本编程给上述的应用场景提供了解决方案,即动态加载bean;
spring支持脚本