深入理解计算机系统第五章学习-性能优化 2
5.5循环展开
一种比较常见的优化程序算法,就是将一次循环展开多次,来减少循环的次数。
例如combine5:
void combine5(vec_ptr v, data_t *dest)
{
long int i;
long int length = vec_length(v);
long int limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for(i = 0;i < limit;i+=2){
acc = (acc OP data[i]) OP data[i+1];
}
for(;i < length; i++){
acc = acc OP data[i];
}
*dest = acc;
}
性能如下:
本机测试:
test4_O0_add_int 0.001313
test5_O0_add_int 0.001048
test53_O0_add_int 0.000972
test54_O0_add_int 0.000920

这是书中给出的性能对比图。可以看到int类型的性能有明显的提升,而float类型没有提升,这是因为float类型在计算机里面不支持结合律造成的,下面会分析。
分析浮点运算没有性能提升的原因:
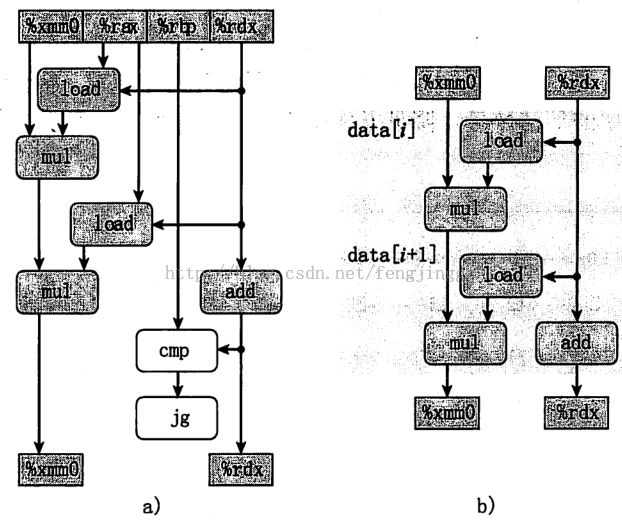
浮点运算不支持结合性,从流程图中看到尽管减少了一半的循环次数,但是每一次都需要两次load两次mul,实质上并没有简化运算,限制因素就在于只有一个%xmm寄存器,使得两次load和mul相关导致的。
5.6多个累计变量
combine5没有提高浮点运算的原因是只有了%xmm寄存器的限制,下面增加累积变量修正该问题:
void combine6(vec_ptr v, data_t *dest)
{
long int i;
long int length = vec_length(v);
long int limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc0 = IDENT;
data_t acc1 = IDENT;
for(i = 0;i < limit;i+=2){
acc0 = acc0 OP data[i];
acc1 = acc1 OP data[i+1];
}
for(;i < length; i++){
acc0 = acc0 OP data[i];
}
*dest = acc0 OP acc1;
}
性能:

本机测试结果:
test5_O0_float 0.001660
test6_O0_float 0.001289
分析:


如图所示,之前的只有一个%xmm变成了两个,因为现在机器都有流水线功能,乱序执行,因此这样提升了其性能。
循环展开和增加累积变量的方法是常见优化程序的方法。我们程序员可以经常用这两种方法进行优化。
5.7重新结合变换
对于combine5修改,将
acc = (acc OP data[i]) OP data[i+1]
修改为:
acc=acc OP (data[i] OP data[i+1])
combine7:
void combine7(vec_ptr v, data_t *dest)
{
long int i;
long int length = vec_length(v);
long int limit = length - 1;
data_t *data = get_vec_start(v);
data_t acc = IDENT;
for(i = 0;i < limit;i+=2){
acc = acc OP (data[i] OP data[i+1]);
}
for(;i < length; i++){
acc = acc OP data[i];
}
*dest = acc;
}
将会提升combine5的性能:
本机性能:
test5_o1_float_mul 0.0000663
test7_o1_float_mul 0.0000498
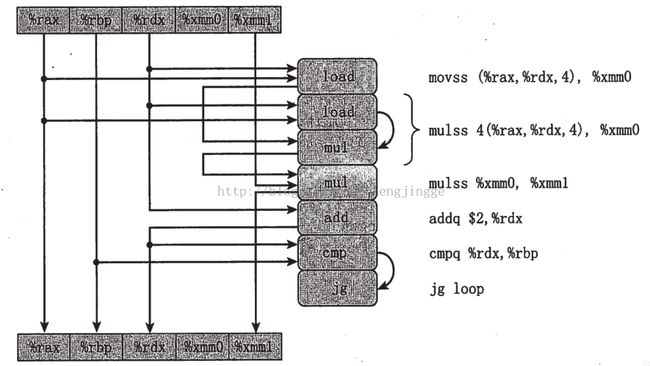

浮点运算在计算机中不支持结合性,因此对于GCC编译器来说不知道该如何对其结合性优化(对于打开O1选项,GCC会对int型数据进行结合性优化),这样combine7中,程序员自己给他确定结合性,从而使得程序进行了取消了两个load和mul的相关性,提升了性能。
这就告诉我们以后的在编程的过程如果碰到这种多个结合在一起的式子,规定结合性(特别是对浮点运算)。
使用了SIMD指令集,最终性能提升结果:

但是在我的32位机器,没有编译出XMM寄存器的指令,xmm只能在64位操作系统上运行。
总结性能提升的结果:
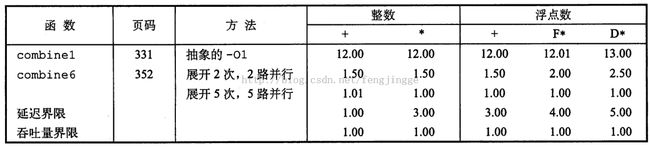
利用SIMD指令,得到最终结果:

可以看出性能提升还是很明显的,提升了10倍多。