Apache Spark1.1.0部署与开发环境搭建 - Mark Lin
原文链接:http://www.tuicool.com/articles/2e2q2y
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构。与MapReduce不同,Spark并不局限于编写map和reduce两个方法,其提供了更为强大的内存计算(in-memory computing)模型,使得用户可以通过编程将数据读取到集群的内存当中,并且可以方便用户快速地重复查询,非常适合用于实现机器学习算法。本文将介绍Apache Spark1.1.0的部署与开发环境搭建。
0. 准备
出于学习目的,本文将Spark部署在虚拟机中,虚拟机选择 VMware WorkStation 。在虚拟机中,需要安装以下软件:
- Ubuntu 14.04.1 LTS 64位桌面版
- hadoop-2.4.0.tar.gz
- jdk-7u67-linux-x64.tar.gz
- scala-2.10.4.tgz
- spark-1.1.0-bin-hadoop2.4.tgz
Spark的开发环境,本文选择Windows7平台,IDE选择IntelliJ IDEA。在Windows中,需要安装以下软件:
- IntelliJ IDEA 13.1.4 Community Edition
- apache-maven-3.2.3-bin.zip (安装过程比较简单,请读者自行安装)
1. 安装JDK
解压jdk安装包到/usr/lib目录:
1 sudo cp jdk-7u67-linux-x64.gz /usr/lib 2 cd /usr/lib 3 sudo tar -xvzf jdk-7u67-linux-x64.gz 4 sudo gedit /etc/profile
在/etc/profile文件的末尾添加环境变量:
1 export JAVA_HOME=/usr/lib/jdk1.7.0_67 2 export JRE_HOME=/usr/lib/jdk1.7.0_67/jre 3 export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH 4 export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
保存并更新/etc/profile:
1 source /etc/profile
测试jdk是否安装成功:
1 java -version
(注释:
(1)在此过程中 Win条件下配置cygwin:使用TXT编辑器 导致一些列的 -r 空格问题,真是扯!
(2)在此过程中 使用反人类的脑残VIM:神奇的模式编辑器,真是扯!
(3)出现扯淡的 BASH:/ 这是一个目录问题,不过不影响操作步骤!
)
2. 安装及配置SSH
sudo apt-get update sudo apt-get install openssh-server
生成并添加密钥:
ssh-keygen -t rsa -P "" 显示:Generating public/private rsa key pair. Enter file in which to save the key (/home/wshchn/.ssh/id_rsa): 按空格:一不小心按了Ctrl+c 显示:Created directory '/home/wshchn/.ssh'. Your identification has been saved in /home/wshchn/.ssh/id_rsa. Your public key has been saved in /home/wshchn/.ssh/id_rsa.pub. The key fingerprint is: 6a:18:65:35:e2:44:be:28:fd:ee:67:f5:61:b9:f4:1a wshchn@wshchn-Aspire-4741 The key's randomart image is: +--[ RSA 2048]----+ | .+ o | | + o . | | = | | . + . | | . + . S . | | . + . . = | | . + . +E+ | | o o o.. | | .oo .. | +-----------------+ cd /home/hduser/.ssh cd /home/wshchn/.ssh
ssh登录:
ssh localhost
显示: The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is df:27:6e:61:8a:3a:5d:5b:3b:58:26:89:1f:d1:5a:32. Are you sure you want to continue connecting (yes/no)? yes 显示: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. Welcome to Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-32-generic x86_64) * Documentation: https://help.ubuntu.com/ The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. Last login: Mon Jan 19 10:26:53 -bash: /: 是一个目录
(注释:此步骤米有疏漏)
3. 安装hadoop2.4.0
采用伪分布模式安装hadoop2.4.0。解压hadoop2.4.0到/usr/local目录:
sudo cp hadoop-2.4.0.tar.gz /usr/local/
sudo tar -xzvf hadoop-2.4.0.tar.gz
在/etc/profile文件的末尾添加环境变量:
export HADOOP_HOME=/usr/local/hadoop-2.4.0 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
保存并更新/etc/profile:
source /etc/profile
在位于/usr/local/hadoop-2.4.0/etc/hadoop的hadoop-env.sh和yarn-env.sh文件中修改jdk路径:
cd /usr/local/hadoop-2.4.0/etc/hadoop sudo gedit hadoop-env.sh sudo gedit yarn-evn.sh
hadoop-env.sh:
(查看java路径:linux:
whereis java
which java (java执行路径)
echo $JAVA_HOME
echo $PATH
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
)yarn-env.sh:

export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
修改/etc/core-site.xml:
vim /etc/hadoop/core-site.xml
在<configuration></configuration>之间添加:
1 <property> 2 <name>fs.default.name</name> 3 <value>hdfs://localhost:9000</value> 4 </property> 5 6 <property> 7 <name>hadoop.tmp.dir</name> 8 <value>/app/hadoop/tmp</value> 9 </property>
修改hdfs-site.xml:
vim /etc/hadoop/hdfs-site.xml
在<configuration></configuration>之间添加:
<property> <name>dfs.namenode.name.dir</name> <value>/app/hadoop/dfs/nn</value> </property> <property> <name>dfs.namenode.data.dir</name> <value>/app/hadoop/dfs/dn</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>
修改yarn-site.xml:
vim /etc/hadoop/yarn-site.xml
在<configuration></configuration>之间添加:
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
复制并重命名mapred-site.xml.template为mapred-site.xml:
sudo cp mapred-site.xml.template mapred-site.xml cp /opt/hadoop-2.2.0/etc/hadoop/mapred-site.xml.template /opt/hadoop-2.2.0/etc/hadoop/mapred-site.xml sudo gedit mapred-site.xml
vim /opt/hadoop-2.2.0/etc/hadoop/mapred-site.xml
在<configuration></configuration>之间添加:
<property> <name>mapreduce.jobtracker.address </name> <value>hdfs://localhost:9001</value> </property>
在启动hadoop之前,为防止可能出现无法写入log的问题,记得为/app目录设置权限:
sudo mkdir /app mkdir /opt/hadoop-2.2.0/app/ sudo chmod -R hduser:hduser /app chmod -R 770 wishchin:wishchin /opt/hadoop-2.2.0/app/
格式化hadoop:
hadoop namenode -format
显示:
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
15/01/19 16:52:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = wshchn-Aspire-4741/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.2.0
STARTUP_MSG: classpath = /opt/h
.................
..................
....................
15/01/19 16:52:58 INFO namenode.FSImage: Image file /app/hadoop/dfs/nn/current/fsimage.ckpt_0000000000000000000 of size 196 bytes saved in 0 seconds.
15/01/19 16:52:58 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
15/01/19 16:52:58 INFO util.ExitUtil: Exiting with status 0
15/01/19 16:52:58 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at wshchn-Aspire-4741/127.0.1.1
************************************************************/
启动hdfs和yarn。在开发Spark时,仅需要启动hdfs:
sbin/start-dfs.sh /opt/hadoop-2.2.0/sbin/start-dfs.sh 显示: 15/01/19 16:56:31 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] root@localhost's : sbin/start-yarn.sh
在浏览器中打开地址可以查看hdfs状态信息:
4. 安装scala
1 sudo cp /home/hduser/Download/scala-2.9.3.tgz /usr/local 2 sudo tar -xvzf scala-2.9.3.tgz
在/etc/profile文件的末尾添加环境变量:
export SCALA_HOME=/usr/local/scala-2.9.3 export PATH=$SCALA_HOME/bin:$PATH
保存并更新/etc/profile:
source /etc/profile
测试scala是否安装成功:
1 scala -version
5. 安装Spark
sudo cp spark-1.1.0-bin-hadoop2.4.tgz /usr/local sudo tar -xvzf spark-1.1.0-bin-hadoop2.4.tgz
在/etc/profile文件的末尾添加环境变量:
export SPARK_HOME=/usr/local/spark-1.1.0-bin-hadoop2.4 export PATH=$SPARK_HOME/bin:$PATH
保存并更新/etc/profile:
source /etc/profile
复制并重命名spark-env.sh.template为spark-env.sh:
sudo cp spark-env.sh.template spark-env.sh sudo gedit spark-env.sh
在spark-env.sh中添加:
export SCALA_HOME=/usr/local/scala-2.9.3 export JAVA_HOME=/usr/lib/jdk1.7.0_67 export SPARK_MASTER_IP=localhost export SPARK_WORKER_MEMORY=1000m
启动Spark:
cd /usr/local/spark-1.1.0-bin-hadoop2.4 sbin/start-all.sh
测试Spark是否安装成功:
cd /usr/local/spark-1.1.0-bin-hadoop2.4 bin/run-example SparkPi
6. 搭建Spark开发环境
本文开发Spark的IDE推荐IntelliJ IDEA,当然也可以选择Eclipse。在使用IntelliJ IDEA之前,需要安装scala的插件。点击Configure:

点击Plugins:
点击Browse repositories...:
在搜索框内输入scala,选择Scala插件进行安装。由于已经安装了这个插件,下图没有显示安装选项:
安装完成后,IntelliJ IDEA会要求重启。重启后,点击Create New Project:

Project SDK选择jdk安装目录,建议开发环境中的jdk版本与Spark集群上的jdk版本保持一致。点击左侧的Maven,勾选Create from archetype,选择org.scala-tools.archetypes:scala-archetype-simple:

点击Next后,可根据需求自行填写GroupId,ArtifactId和Version:

点击Next后,如果本机没有安装maven会报错,请保证之前已经安装maven:

点击Next后,输入文件名,完成New Project的最后一步:
点击Finish后,maven会自动生成pom.xml和下载依赖包。我们需要修改pom.xml中scala的版本:
1 <properties> 2 <scala.version>2.10.4</scala.version> 3 </properties>
在<dependencies></dependencies>之间添加配置:
1 <!-- Spark --> 2 <dependency> 3 <groupId>org.apache.spark</groupId> 4 <artifactId>spark-core_2.10</artifactId> 5 <version>1.1.0</version> 6 </dependency> 7 8 <!-- HDFS --> 9 <dependency> 10 <groupId>org.apache.hadoop</groupId> 11 <artifactId>hadoop-client</artifactId> 12 <version>2.4.0</version> 13 </dependency>
Spark的开发环境至此搭建完成。One more thing,wordcount的示例代码:
1 package mark.lin //别忘了修改package 2 3 import org.apache.spark.{SparkConf, SparkContext} 4 import org.apache.spark.SparkContext._ 5 6 import scala.collection.mutable.ListBuffer 7 8 /** 9 * Hello world! 10 * 11 */ 12 object App{ 13 def main(args: Array[String]) { 14 if (args.length != 1) { 15 println("Usage: java -jar code.jar dependencies.jar") 16 System.exit(0) 17 } 18 val jars = ListBuffer[String]() 19 args(0).split(",").map(jars += _) 20 21 val conf = new SparkConf() 22 conf.setMaster("spark://localhost:7077").setAppName("wordcount").set("spark.executor.memory", "128m").setJars(jars) 23 24 val sc = new SparkContext(conf) 25 26 val file = sc.textFile("hdfs://localhost:9000/hduser/wordcount/input/input.csv") 27 val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_) 28 println(count) 29 count.saveAsTextFile("hdfs://localhost:9000/hduser/wordcount/output/") 30 sc.stop() 31 } 32 }
7. 编译&运行
使用maven编译源代码。点击左下角,点击右侧package,点击绿色三角形,开始编译。
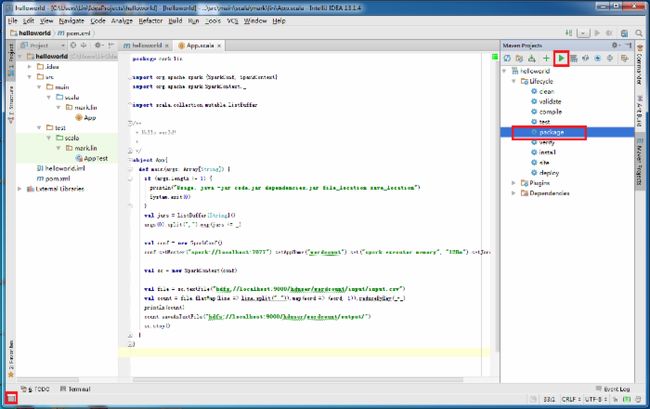
在target目录下,可以看到maven生成的jar包。其中,hellworld-1.0-SNAPSHOT-executable.jar是我们需要放到Spark集群上运行的。

在运行jar包之前,保证hadoop和Spark处于运行状态:
将jar包拷贝到Ubuntu的本地文件系统上,输入以下命令运行jar包:
1 java -jar helloworld-1.0-SNAPSHOT-executable.jar helloworld-1.0-SNAPSHOT-executable.jar
在浏览器中输入地址http://localhost:8080/可以查看任务运行情况:

8. Q&A
Q: 在Spark集群上运行jar包,抛出异常“No FileSystem for scheme: hdfs”:

A:这是由于hadoop-common-2.4.0.jar中的core-default.xml缺少hfds的相关配置属性引起的异常。在maven仓库目录下找到hadoop-common-2.4.0.jar,以rar的打开方式打开:

将core-default.xml拖出,并添加配置:
1 <property> 2 <name>fs.hdfs.impl</name> 3 <value>org.apache.hadoop.hdfs.DistributedFileSystem</value> 4 <description>The FileSystem for hdfs: uris.</description> 5 </property>
再将修改后的core-default.xml替换hadoop-common-2.4.0.jar中的core-default.xml,重新编译生成jar包。
Q: 在Spark集群上运行jar包,抛出异常“Failed on local exception”:

A:检查你的代码,一般是由于hdfs路径错误引起。
Q: 在Spark集群上运行jar包,重复提示“Connecting to master spark”:

A:检查你的代码,一般是由于setMaster路径错误引起。
Q: 在Spark集群上运行jar包,重复提示“Initial job has not accepted any resource; check your cluster UI to ensure that workers are registered and have sufficient memory”:
![]()
A:检查你的代码,一般是由于内存设置不合理引起。此外,还需要检查Spark安装目录下的conf/spark-env.sh对worker内存的设置。
9. 参考资料
[1] Spark Documentation from Apache. [ Link ]
10. 鸣谢
感谢limyao( http://limyao.com/ )为本文提供的帮助。