十月百度,阿里巴巴,迅雷搜狗最新面试七十题(第201-270题)
引言
当即早已进入10月份,十一过后,招聘,笔试,面试,求职渐趋火热。而在这一系列过程背后浮出的各大IT公司的笔试/面试题则蕴含着诸多思想与设计,细细把玩,思考一番亦能有不少收获。
上个月,本博客着重整理九月腾讯,创新工场,淘宝等公司最新面试十三题,此次重点整理百度,阿里巴巴,迅雷和搜索等公司最新的面试题。同上篇一样,答案望诸君共同讨论之,个人亦在慢慢思考解答。多谢。
最新面试十一题
- 十月百度:一个数组保存了N个结构,每个结构保存了一个坐标,结构间的坐标都不相同,请问如何找到指定坐标的结构(除了遍历整个数组,是否有更好的办法)?(要么预先排序,二分查找。要么哈希。hash的话,坐标(x,y)你可以当做一个2位数,写一个哈希函数,把(x,y)直接转成“(x,y)”作为key,默认用string比较。或如Edward Lee所说,将坐标(x, y)作为 Hash 中的 key。例如(m, n),通过 (m,n) 和 (n, m) 两次查找看是否在 HashMap 中。也可以在保存时就规定 (x, y) , x < y ,在插入之前做个判断。)
- 百度最新面试题:现在有1千万个随机数,随机数的范围在1到1亿之间。现在要求写出一种算法,将1到1亿之间没有在随机数中的数求出来。(编程珠玑上有此类似的一题,如果有足够的内存的话可以用位图法,即开一个1亿位的bitset,内存为100m/8== 12.5m, 然后如果一个数有出现,对应的bitset上标记为1,最后统计bitset上为0的即可。)
- Alibaba笔试题:给定一段产品的英文描述,包含M个英文字母,每个英文单词以空格分隔,无其他标点符号;再给定N个英文单词关键字,请说明思路并编程实现方法
String extractSummary(String description,String[] key words)
目标是找出此产品描述中包含N个关键字(每个关键词至少出现一次)的长度最短的子串,作为产品简介输出。(不限编程语言)20分。(扫描过程始终保持一个[left,right]的range,初始化确保[left,right]的range里包含所有关键字则停止。然后每次迭代:
1,试图右移动left,停止条件为再移动将导致无法包含所有关键字。
2,比较当前range's length和best length,更新最优值。
3,右移right,停止条件为使任意一个关键字的计数+1。
4,重复迭代。
编程之美有最短摘要生成的问题,与此问题类似,读者可作参考。) - 搜狗:有N个正实数(注意是实数,大小升序排列) x1 , x2 ... xN,另有一个实数M。 需要选出若干个x,使这几个x的和与 M 最接近。 请描述实现算法,并指出算法复杂度(参考:第五章、寻找满足条件的两个或多个数)
- 直接穷举,从数组中任意选取两个数,判定它们的和是否为输入的那个数字。此举复杂度为O(N^2)。很显然,我们要寻找效率更高的解法。
- 题目相当于,对每个a[i],然后查找判断sum-a[i]是否也在原始序列中,每一次要查找的时间都要花费为O(N),这样下来,最终找到两个数还是需要O(N^2)的复杂度。那如何提高查找判断的速度列?对了,二分查找,将原来O(N)的查找时间提高到O(logN),这样对于N个a[i],都要花logN的时间去查找相对应的sum-a[i]是否在原始序列中,总的时间复杂度已降为O(N*logN),且空间复杂度为O(1)。(如果有序,直接二分O(N*logN),如果无序,先排序后二分,复杂度同样为O(N*logN+N*logN)=O(N*logN),空间总为O(1))。
- 有没有更好的办法列?咱们可以依据上述思路2的思想,a[i]在序列中,如果a[i]+a[k]=sum的话,那么sum-a[i](a[k])也必然在序列中,举个例子,如下:
原始序列:1、 2、 4、 7、11、15 用输入数字15减一下各个数,得到对应的序列为:
对应序列:14、13、11、8、4、 0
第一个数组以一指针i 从数组最左端开始向右扫描,第二个数组以一指针j 从数组最右端开始向左扫描,如果下面出现了和上面一样的数,即a[*i]=a[*j],就找出这俩个数来了。如上,i,j最终在第一个,和第二个序列中找到了相同的数4和11,,所以符合条件的两个数,即为4+11=15。怎么样,两端同时查找,时间复杂度瞬间缩短到了O(N),但却同时需要O(N)的空间存储第二个数组(@飞羽:要达到O(N)的复杂度,第一个数组以一指针i 从数组最左端开始向右扫描,第二个数组以一指针j 从数组最右端开始向左扫描,首先初始i指向元素1,j指向元素0,谁指的元素小,谁先移动,由于1(i)>0(j),所以i不动,j向左移动。然后j移动到元素4发现大于元素1,故而停止移动j,开始移动i,直到i指向4,这时,i指向的元素与j指向的元素相等,故而判断4是满足条件的第一个数;然后同时移动i,j再进行判断,直到它们到达边界)。 - 当然,你还可以构造hash表,正如编程之美上的所述,给定一个数字,根据hash映射查找另一个数字是否也在数组中,只需用O(1)的时间,这样的话,总体的算法通上述思路3 一样,也能降到O(N),但有个缺陷,就是构造hash额外增加了O(N)的空间,此点同上述思路 3。不过,空间换时间,仍不失为在时间要求较严格的情况下的一种好办法。
- 如果数组是无序的,先排序(n*logn),然后用两个指针i,j,各自指向数组的首尾两端,令i=0,j=n-1,然后i++,j--,逐次判断a[i]+a[j]?=sum,如果某一刻a[i]+a[j]>sum,则要想办法让sum的值减小,所以此刻i不动,j--,如果某一刻a[i]+a[j]<sum,则要想办法让sum的值增大,所以此刻i++,j不动。所以,数组无序的时候,时间复杂度最终为O(n*logn+n)=O(n*logn),若原数组是有序的,则不需要事先的排序,直接O(n)搞定,且空间复杂度还是O(1),此思路是相对于上述所有思路的一种改进。(如果有序,直接两个指针两端扫描,时间O(N),如果无序,先排序后两端扫描,时间O(N*logN+N)=O(N*logN),空间始终都为O(1))。(与上述思路2相比,排序后的时间开销由之前的二分的n*logn降到了扫描的O(N))。
- 迅雷:给你10台机器,每个机器2个cpu,2g内存,现在已知在10亿条记录的数据库里执行一次查询需要5秒,问用什么方法能让90%的查询能在100毫秒以内返回结果。(@geochway:将10亿条记录排序,然后分到10个机器中,分的时候是一个记录一个记录的轮流分,
确保每个机器记录大小分布差不多,每一次查询时,同时提交给10台机器,同时查询,
因为记录已排序,可以采用二分法查询。
如果无法排序,只能顺序查询,那就要看记录本身的概率分布,否则不可能实现。
一个机器2个CPU未必能起到作用,要看这两个CPU能否并行存取内存,取决于系统架构。) - 给定一个函数rand()能产生0到n-1之间的等概率随机数,问如何产生0到m-1之间等概率的随机数?
- 腾讯:五笔的编码范围是a ~ y的25个字母,从1位到4位的编码,如果我们把五笔的编码按字典序排序,形成一个数组如下:
a, aa, aaa, aaaa, aaab, aaac, … …, b, ba, baa, baaa, baab, baac … …, yyyw, yyyx, yyyy
其中a的Index为0,aa的Index为1,aaa的Index为2,以此类推。
1)编写一个函数,输入是任意一个编码,比如baca,输出这个编码对应的Index;
2)编写一个函数,输入是任意一个Index,比如12345,输出这个Index对应的编码。 - 2011.10.09百度笔试题(下述第8-12题):linux/unix远程登陆都用到了ssh服务,当网络出现错误时服务会中断,linux/unix端的程序会停止。为什么会这样?说下ssh的原理,解释中断的原理。
- 一个最小堆,也是完全二叉树,用按层遍历数组表示。
1. 求节点a[n]的子节点的访问方式
2. 插入一节点的程序void add_element(int *a,int size,int val);
3. 删除最小节点的程序。 - a)求一个全排列函数:如p([1,2,3]) ,输出: [123],[132],[213],[231],[321],[323]。
b)求一个组合函数: 如p([1,2,3]) ,输出:[1],[2],[3],[1,2],[2,3],[1,3],[1,2,3]。
这两问可以用伪代码(全排列请参考这里的第67题:微软、Google等公司非常好的面试题及解答[第61-70题] )。 
- 有这样一种编码:如,N=134,M=f(N)=143,N=020,M=fun(N)=101,其中N和M的位数一样,N,M可以均可以以0开头,N,M的各位数之和要相等,即1+3+4=1+4+3,且M是大于N中最小的一个,
现在求这样的序列S,N为一个定值,其中S(0)=N,S(1)=fun(N),S(2)=fun(S(1))。 - 有1000万条URL,每条URL 50字节,只包含主机前缀,要求实现URL提示系统:
(1)要求实时更新匹配用户输入的地址,每输出一个字符,输出最新匹配URL
(2)每次只匹配主机前缀,例如对 www.abaidu.com和www.baidu.com,用户输入www.b时只提示www.baidu.com(3)每次提供10条匹配的URL
(4)以用户需求为主。 - 海量记录,记录形式如下: TERMID URLNOCOUNT urlno1 urlno2 ..., urlnon
怎么考虑资源和时间这两个因素,实现快速查询任意两个记录的交集,并集等,设计相关的数据结构和算法。 - 百度最新笔试题(感谢xiongyangwan提供的题目):利用互斥量和条件变量设计一个消息队列,具有以下功能:
1 创建消息队列(消息中所含的元素)
2 消息队列中插入消息
3 取出一个消息(阻塞方式)
4 取出第一消息(非阻塞方式) - 百度移动终端研发笔试:系统设计题(40分)
对已排好序的数组A,一般来说可用二分查找可以很快找到。现有一特殊数组A[],它是循环递增的,如A[]={ 17 19 20 25 1 4 7 9},试在这样的数组中找一元素x,看看是否存在。
请写出你的算法,必要时可写伪代码,并分析其空间、时间复杂度。 - #include<stdio.h>
#include <string.h>
void main()
{
int a[2000];
char *p = (char *)a;
int i ;
for( i = 0; i < 2000; i++)
a[i] = -i -1;
printf("%d\n", strlen(p));
}
写出输出结果(onlyice:i = FFFFFF00H 的时候,才有'\0'出现,就是最后一个字节,C风格字符串读到'\0'就终止了。FFFFFF00H 是 -256,就是 i 的值为255时a[i] = FFFFFF00H).... - 腾讯10.09测试笔试题:有N+2个数,N个数出现了偶数次,2个数出现了奇数次(这两个数不相等),问用O(1)的空间复杂度,找出这两个数,不需要知道具体位置,只需要知道这两个值。(@Rojay:xor一次,得到2个奇数次的数之和x。第二步,以x(展开成二进制)中有1的某位(假设第i位为1)作为划分,第二次只xor第i位为1的那些数,得到y。然后x xor y以及y便是那两个数。 )
- @well:一个整数数组,有n个整数,如何找其中m个数的和等于另外n-m个数的和?(与上面第4题类似,参考:第五章、寻找满足条件的两个或多个数)。
- 阿里云笔试题:一个HTTP服务器处理一次请求需要500毫秒,请问这个服务器如何每秒处理100个请求。
- 今天10.10阿里云笔试@土豆:1、三次握手;
 2、死锁的条件。(互斥条件(Mutual exclusion):1、资源不能被共享,只能由一个进程使用。2、请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。3、非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。4、循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。处理死锁的策略:1.忽略该问题。例如鸵鸟算法,该算法可以应用在极少发生死锁的的情况下。为什么叫鸵鸟算法呢,因为传说中鸵鸟看到危险就把头埋在地底下,可能鸵鸟觉得看不到危险也就没危险了吧。跟掩耳盗铃有点像。2.检测死锁并且恢复。3.仔细地对资源进行动态分配,以避免死锁。4.通过破除死锁四个必要条件之一,来防止死锁产生。)
2、死锁的条件。(互斥条件(Mutual exclusion):1、资源不能被共享,只能由一个进程使用。2、请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。3、非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。4、循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。处理死锁的策略:1.忽略该问题。例如鸵鸟算法,该算法可以应用在极少发生死锁的的情况下。为什么叫鸵鸟算法呢,因为传说中鸵鸟看到危险就把头埋在地底下,可能鸵鸟觉得看不到危险也就没危险了吧。跟掩耳盗铃有点像。2.检测死锁并且恢复。3.仔细地对资源进行动态分配,以避免死锁。4.通过破除死锁四个必要条件之一,来防止死锁产生。) - 微软2011最新面试题(以下三题,第22、23、24题皆摘自微软亚洲研究院的邹欣老师博客):浏览过本人的程序员编程艺术系列的文章,一定对其中的这个问题颇有印象:第七章、求连续子数组的最大和。求数组最大子数组的和最初来源于编程之美,
 。我在编程艺术系列中提供了多种解答方式,然而这个问题若扩展到二维数组呢?
。我在编程艺术系列中提供了多种解答方式,然而这个问题若扩展到二维数组呢?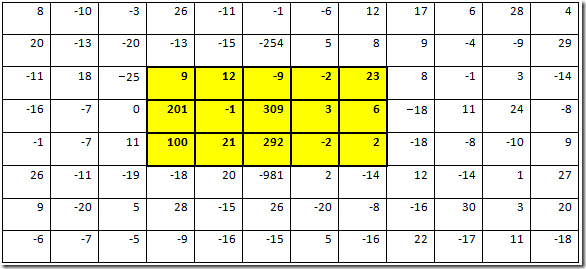 再者,若数组首尾相连, 像一个轮胎一样, 又怎么办呢?聪明的同学还是给出了漂亮的答案, 并且用 SilverLight/WPF 给画了出来, 如下图所示:
再者,若数组首尾相连, 像一个轮胎一样, 又怎么办呢?聪明的同学还是给出了漂亮的答案, 并且用 SilverLight/WPF 给画了出来, 如下图所示:
好,设想现在我们有一张纸带,两面都写满了像如上第一幅图那样的数字, 我们把纸带的一端扭转, 和另一端接起来, 构成一个莫比乌斯环 (Möbius Strip,如将一个长方形纸条ABCD的一端AB固定,另一端DC扭转半周后,把AB和CD粘合在一起 ,得到的曲面就是麦比乌斯圈,也称莫比乌斯带。),如下图所示:

如上,尽管这个纸带扭了一下, 但是上面还是有数组, 还是有最大子数组的和,对么? 在求最大子数组的和之前, 我们用什么样的数据结构来表示这些数字呢? 你可以用 Java, C, C#, 或其他语言的数据结构来描述这个莫比乌斯环上的数组。数据结构搞好了, 算法自然就有了。(@风大哥:莫比乌斯带,用环形数组或者链表可以表示。环型数组的话,1-N,到N特殊处理一下,连到1就是环型数组了,一个纸带上正反两面各有N个数,A1...An,B1...Bn,那么就可以构造一个新的数组:A1-An-B1-Bn.访问到Bn下一位就是A1,就是环形的数组了。从某个位置k开始,用i,j向一个方向遍历,直到i到达k位置,或者i=j,被追上,用数组需要一点技巧,就是J再次过k需要打个标志,以便计算终止条件和输出。当然,如果用链表就更简单了。把链表首尾相接即可,即An执行B1,Bn指向A1即可。)
- 《编程之美》的第一题是让Windows 任务管理器的CPU 使用率曲线画出一个正弦波。我一直在想, 能不能把CPU 使用率边上的网络使用率也如法炮制一下呢? 比如, 也来一个正弦曲线?
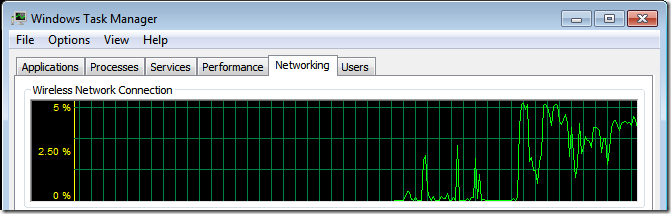
-
如果你没看过, 也至少听说<人月神话> (The Mythical Man-month) 这本在软件工程领域很有影响的书. 当你在微软学术搜索中输入 “manmonth” 这个词的时候, 你会意外地碰到下面这个错误:
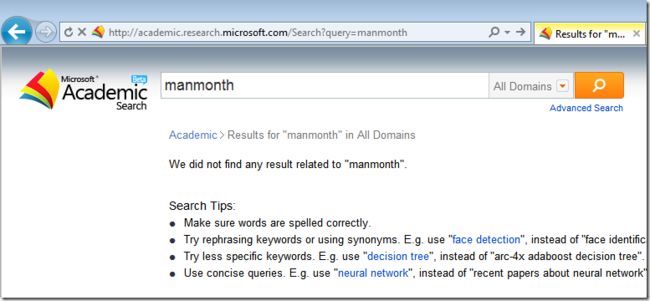
经过几次试验之后, 你发现必须要输入 “man-month” 才能得到希望的结果。 这不就是只差一个 ‘-’ 符号么? 为什么这个搜索引擎不能做得聪明一些, 给一些提示 (Query Suggestion)? 或者自动把用户想搜的结果展现出来 (Query Alteration)? 我们在输入比较长的英文单词的时候, 也难免会敲错一两个字母, 网站应该帮助用户, 而不是冷冰冰地拒绝用户啊。
微软的学术搜索 (Microsoft Academic Search) 索引了超过 3千万的文献, 2 千万的人名, 怎么能以比较小的代价, 对经常出现的输入错误提供提示? 或直接显示相关结果, 避免用户反复尝试输入的烦恼?
你可能会说, 这很难吧, 但是另一家搜索引擎似乎轻易地解决了这个问题 (谷歌,读者可以一试)。 所以, 还是有办法的。
这个题目要求你:
1) 试验不同的输入, 反推出目前微软的学术搜索是如何实现搜索建议 (Query Suggestion)的。
2) 提出自己的改进建议, 并论证这个解决方案在千万级数据规模上能达到 “足够好” 的时间 (speed) 和空间 (memory usage)效率。
3) 估计这事需要几个 人·月 (man-month) 才能做完? (备注:顺便给邹欣老师传个话,如果应届毕业生可以能做好上述全部三个题目,便可直接找他。http://www.cnblogs.com/xinz/archive/2011/10/10/2205232.html)。 - 今天10.10阿里云部分笔试题目:
1、一个树被序列化为数组,如何反序列化。
2、如何将100百万有序数据最快插入到STL的map里。
3、有两个线程a、b分别往一条队列push和pop数据,在没有锁和信号量的情况下如何避免冲突访问。
4、写一个函数,功能是从字符串s中查找出子串t,并将t从s中删除。 - 将长度为m和n的两个升序数组复制到长度为m+n的数组里,升序排列。
-
tencent2012笔试题附加题
问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。
已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与ServerIPIndex[QQNUM%(n-1)]基本上都不一样了,所以大多数用户的请求都会转到其他服务器,这样会发生大量访问错误。问: 如何改进或者换一种方法,使得:
(1)一台服务器死掉后,不会造成大面积的访问错误,
(2)原有的访问基本还是停留在同一台服务器上;
(3)尽量考虑负载均衡。(思路:往分布式一致哈希算法方面考虑。关于此算法,可参见此文:http://blog.csdn.net/21aspnet/article/details/5780831)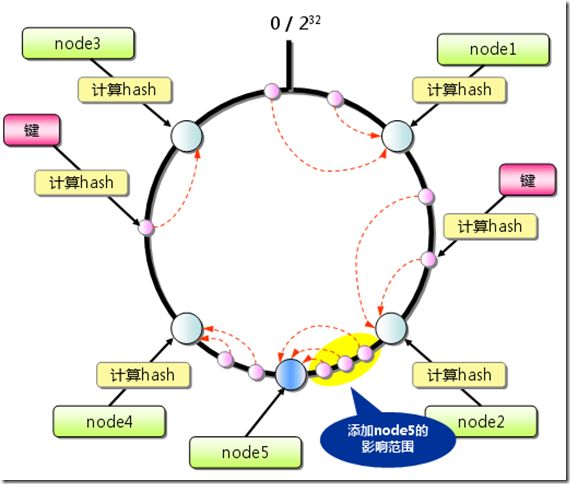
-
腾讯面试题:A.txt和B.txt两个文件,A.txt有1亿个QQ号 , B.txt 100W个QQ号, 用代码实现交、并、差。
-
说出下面的运行结果
#include <iostream>
using namespace std;class A
{
public:
virtual void Fun(int number = 10)
{
std::cout << "A::Fun with number " << number<<endl;
}
};class B: public A
{
public:
virtual void Fun(int number = 20)
{
std::cout << "B::Fun with number " << number<<endl;
}
};int main()
{
B b;
A &a = b;
a.Fun();
return 0;
} //虚函数动态绑定=>B,非A,缺省实参是编译时候确定的=>10,非20 。 -
今晚阿里云笔试:有101根电线 每根的一头在楼底 另一端在楼顶 有一个灯泡 一个电池 无数根很短的电线 怎么样在楼上一次在楼下去一次将电线的对应关系弄清楚。
-
金山笔试题:
1、C ++为什么经常将析构函数声明为虚函数?
2、inline和#define的如何定义MAX,区别是什么。
3、const的用法,如何解除const限制。
4、智能指针的作用和设计原理。
5、STL中vetor如何自己设计,关键设计点,函数声明,自定义删除重复元素的函数。
6、如何用一条SQL语句,删除表中某字段重复的记录。 -
淘宝:
在现代web服务系统的设计中,为了减轻源站的压力,通常采用分布式缓存技术,其原理如下图所示,前端的分配器将针对不同内容的用户请求分配给不同的缓存服务器向用户提供服务。
分配器
/ | \
缓存 缓存 . ..缓存
服务器1 服务器2 ...服务器n1)请问如何设置分配策略,可以保证充分利用每个缓存服务器的存储空间(每个内容只在一个缓存服务器有副本)
2)当部分缓存服务器故障,或是因为系统扩容,导致缓存服务器的数量动态减少或增加时,你的分配策略是否可以保证较小的缓存文件重分配的开销,如果不能,如何改进?
3)当各个缓存服务器的存储空间存在差异时(如有4个缓存服务器,存储空间比为4:9:15:7),如何改进你的策略,按照如上的比例将内容调度到缓存服务器?(思路:往memcached或者一致性hash算法方面考虑,但具体情况,具体分析。) -
腾讯:50个台阶,一次可一阶或两阶,共有几种走法(老掉牙的题了,详见微软面试100题2010版。
long long Fibonacci_Solution1(unsigned int n)
{
int result[2] = {0, 1};
if(n < 2)
return result[n];return Fibonacci_Solution1(n - 1) + Fibonacci_Solution1(n - 2);
})。 -
有两个float型的数,一个为fmax,另一个为fmin,还有一个整数n,如果 (fmax - fmin)/n ,不能整除,怎么改变fmax,fmin,使改变后可以整除n 。
-
2011.10.11最新百度电面:
1、动态链接库与静态链接库的区别( 静态链接库是.lib格式的文件,一般在工程的设置界面加入工程中,程序编译时会把lib文件的代码加入你的程序中因此会增加代码大小,你的程序一运行lib代码强制被装入你程序的运行空间,不能手动移除lib代码。
动态链接库是程序运行时动态装入内存的模块,格式*.dll,在程序运行时可以随意加载和移除,节省内存空间。
在大型的软件项目中一般要实现很多功能,如果把所有单独的功能写成一个个lib文件的话,程序运行的时候要占用很大的内存空间,导致运行缓慢;但是如果将功能写成dll文件,就可以在用到该功能的时候调用功能对应的dll文件,不用这个功能时将dll文件移除内存,这样可以节省内存空间。)
2、指针与引用的区别(相同点:1. 都是地址的概念;
指针指向一块内存,它的内容是所指内存的地址;引用是某块内存的别名。区别:
1. 指针是一个实体,而引用仅是个别名;
2. 引用使用时无需解引用(*),指针需要解引用;
3. 引用只能在定义时被初始化一次,之后不可变;指针可变;
4. 引用没有 const,指针有 const;
5. 引用不能为空,指针可以为空;
6. “sizeof 引用”得到的是所指向的变量(对象)的大小,而“sizeof 指针”得到的是指针本身(所指向的变量或对象的地址)的大小;
7. 指针和引用的自增(++)运算意义不一样;
8.从内存分配上看:程序为指针变量分配内存区域,而引用不需要分配内存区域。)
3、进程与线程的区别(①从概念上:
进程:一个程序对一个数据集的动态执行过程,是分配资源的基本单位。
线程:一个进程内的基本调度单位。
线程的划分尺度小于进程,一个进程包含一个或者更多的线程。
②从执行过程中来看:
进程:拥有独立的内存单元,而多个线程共享内存,从而提高了应用程序的运行效率。
线程:每一个独立的线程,都有一个程序运行的入口、顺序执行序列、和程序的出口。但是线程不能够独立的执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
③从逻辑角度来看:(重要区别)
多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但是,操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理及资源分配。)
4、函数调用入栈出栈的过程
4、c++对象模型与虚表
5、海量数据处理,以及如何解决Hash冲突等问题
6、系统设计,概率算法 -
今天腾讯面试:
一个大小为N的数组,里面是N个整数,怎样去除重复,
要求时间复杂度为O(n),空间复杂度为O(1)(此题答案请见@作者hawksoft:http://blog.csdn.net/hawksoft/article/details/6867493)。 -
一个长度为10000的字符串,写一个算法,找出最长的重复子串,如abczzacbca,结果是bc(思路:后缀树/数组的典型应用,@well:就是求后缀数组的height[]的最大值
)。 - 今晚10.11大华笔试题:建立一个data structure表示没有括号的表达式,而且找出所有等价(equivalent)的表达式
比如:
3×5 == 5×3
2+3 == 3+2 - 今晚10.11百度二面:判断一个数的所有因数的个数是偶数还是奇数(只需要你判断因数的个数是偶数个还是奇数个,那么可以这么做@滨湖&&土豆:那只在计算质因数的过程中统计一下当前质因数出现的次数,如果出现奇数次则结果为偶,然后可以立即返回;如果每个质因数的次数都是偶数,那么结果为奇。如果该数是平方数 结果就为奇 否则就为偶了)。
- 比如A认识B,B认识C,但是A不认识C, 那么称C是A的二度好友。找出某个人的所有十度好友. 数据量为10万(BFS,同时记录已遍历过的顶点,遍历时遇到的已遍历过的顶点不插入队列。此是今晚10.11人人笔试题目,但它在上个月便早已出现在本人博客中,即此文第23题第2小题:九月腾讯,创新工场,淘宝等公司最新面试十三题)。
- map在什么情况下会发生死锁;stl中的map是怎么实现的?(有要参加淘宝面试的朋友注意,淘宝喜欢问STL方面的问题)
- 昨日笔试:有四个人,他们每次一起出去玩的时候,用同时剪刀包袱锤的方式决定谁请客。设计一种方法,使得他们只需出一次,就可以决定请客的人,并且每个人请客的几率相同,均为25%。
- Given two sets of n numbers a1, a2…, an and b1, b2…bn, find, in polynomial time, a permutation Π such that ∑i |ai - b Π(i)| is minimized? Prove your algorithm works.
有两个数组,在多项式时间里找到使 两数组元素 的差 的绝对值 的和 最小 的一种置换。
并证明算法的有效性。注意,关键是证明。(此题个人去年整理过类似的一题,详见微软面试100题2010版第32题:http://blog.csdn.net/v_JULY_v/archive/2011/01/10/6126444.aspx) -
对已排好序的数组A,一般来说可用二分查找 可以很快找到。
现有一特殊数组A[],它是循环递增的,如A[]={ 17 19 20 25 1 4 7 9},
试在这样的数组中找一元素x,看看是否存在。
请写出你的算法,必要时可写伪代码,并分析其空间 时间复杂度。 - 网易:题意很简单,写一个程序,打印出以下的序列。
(a),(b),(c),(d),(e)........(z)
(a,b),(a,c),(a,d),(a,e)......(a,z),(b,c),(b,d).....(b,z),(c,d).....(y,z)
(a,b,c),(a,b,d)....(a,b,z),(a,c,d)....(x,y,z)
....
(a,b,c,d,.....x,y,z)(思路:全排列问题) -
int global = 0;
// thread 1
for(int i = 0; i < 10; ++i)
global -= 1;// thread 2
for(int i = 0; i < 10; ++i)
global += 1;之后global的可能的值是多少(多种可能)?
- 今天10.13新浪笔试:
1、用隐喻说明class和object的区别,要求有新意。
2、DDL,DML,DCL的含义,和距离
3、TCP建立连接的三次握手
4、设计人民币面值,要求种类最好,表示1——1000的所有数,平均纸币张数最少
5、UML -
一个数组。里面的数据两两相同,只有两个数据不同,要求找出这两个数据。要求时间复杂度0(N)空间复杂度O(1)。
-
两个数相乘,小数点后位数没有限制,请写一个高精度算法。
- 面试基础题:
1、静态方法里面为什么不能声明静态变量?
2、如果让你设计一个类,什么时候把变量声明为静态类型?
3、抽象类和接口的具体区别是什么? -
谷歌昨晚10.13算法笔试三题:
1.一个环形公路,上面有N个站点,A1, ..., AN,其中Ai和Ai+1之间的距离为Di,AN和A1之间的距离为D0。
高效的求第i和第j个站点之间的距离,空间复杂度不超过O(N)
它给出了部分代码如下:
#define N 25
double D[N]
....
void Preprocess()
{
//Write your code1;
}
double Distance(int i, int j)
{
//Write your code2;
}2. 一个字符串,压缩其中的连续空格为1个后,对其中的每个字串逆序打印出来。比如"abc efg hij"打印为"cba gfe jih"。
3. 将一个较大的钱,不超过1000000(10^6)的人民币,兑换成数量不限的100、50、10、5、2、1的组合,请问共有多少种组合呢?(其它选择题考的是有关:操作系统、树、概率题、最大生成树有关的题,另外听老梦说,谷歌不给人霸笔的机会。)。
-
谷歌在线笔试题:
输入两个整数A和B,输出所有A和B之间满足指定条件的数的个数。指定条件:假设C=8675在A跟B之间,若(8+6+7+5)/ 4 > 7,则计一个,否则不计。
要求时间复杂度:log(A)+log(B)。 -
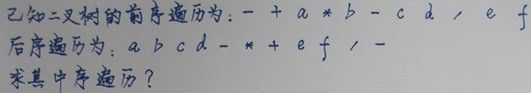
- 十五道百度、腾讯面试基础测试题@fengchaokobe:
1、写一个C的函数,输入整数N,输出整数M,M满足:M是2的n次方,且是不大于N中最大的2的n次方。例如,输入4,5,6,7,都是输出4 。
2、C++中虚拟函数的实现机制。
3、写出选择排序的代码及快速排序的算法。
4、你认为什么排序算法最好?
5、tcp/ip的那几层协议,IP是否是可靠的?为什么?
6、进程和线程的区别和联系,什么情况下用多线程,什么时候用多进程?
7、指针数组和数组指针的区别。
8、查找单链表的中间结点。
9、最近在实验室课题研究或工作中遇到的技术难点,怎么解决的?
10、sizeof和strlen的区别。
11、malloc-free和new-delete的区别
12、大数据量中找中位数。
13、堆和栈的区别。
14、描述函数调用的整个过程。
15、在一个两维平面上有三个不在一条直线上的点。请问能够作出几条与这些点距离相同的线?
- 搜狐的一道笔试题:
char *s="mysohu";
s[0]=0; //..
printf("%s",s);
输出是什么啊?
搜狐的一道大题:
数组非常长,如何找到第一个只出现一次的数字,说明算法复杂度。(与个人之前整理的微软面试100题中,第17题:在一个字符串中找到第一个只出现一次的字符。类似,读者可参考。)
- 百度笔试3. 假设有一台迷你计算机,1KB的内存,1MHZ的cpu,已知该计算机执行的程序可出现确定性终止(非死循环),问如何求得这台计算机上程序运行的最长时间,可以做出任何大胆的假设。
- 微软10.15笔试:对于一个数组{1,2,3}它的子数组有{1,2},{1,3}{2,3},{1,2,3},元素之间可以不是连续的,对于数组{5,9,1,7,2,6,3,8,10,4},升序子序列有多少个?或者换一种表达为:数组int a[]={5,9,1,7,2,6,3,8,10,4} 。求其所有递增子数组(元素相对位置不变)的个数, 例如:{5,9},{5,7,8,10},{1,2,6,8}。
- 今日腾讯南京笔试题: M*M的方格矩阵,其中有一部分为障碍,八个方向均可以走,现假设矩阵上有Q+1节点,从(X0,Y0)出发到其他Q个节点的最短路径。
其中,1<=M<=1000,1<=Q<=100。 - 另外一个笔试题:
一个字符串S1:全是由不同的字母组成的字符串如:abcdefghijklmn
另一个字符串S2:类似于S1,但长度要比S1短。
问题是,设计一种算法,求S2中的字母是否均在S1中。(字符串包含问题,详见程序员编程艺术系列第二章:http://blog.csdn.net/v_JULY_v/article/details/6347454)。 -
检索一英语全文,顺序输出检测的单词和单词出现次数。
- 今天10.15下午网易游戏笔试题:给一个有序数组array[n],和一个数字m,判断m是否是这些数组里面的数的和。(类似于微软面试100题2010年版第4题,即相当于给定一棵树,然后给定一个数,要求把那些 相加的和等于这个数的 所有节点打印出来)。
- 一个淘宝的面试题
文件A:
uid username
文件B:
username password
文件A是按照uid有序排列的,要求有序输出合并后的A,B文件,格式为uid username password(A B 两个文件都很大,内存装不下。)
- 百度可能会问问memcached(可下载此份文档看看:http://tech.idv2.com/2008/08/17/memcached-pdf/。源码下载地址:http://www.oschina.net/p/memcached),apache之类的。
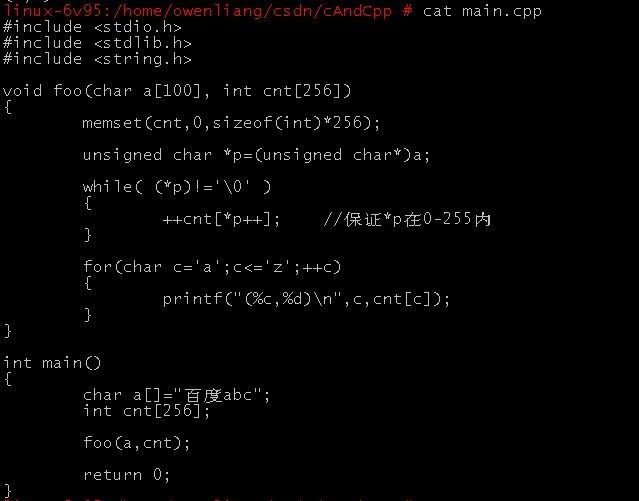
- 今上午10.16百度笔试:1.C++ STL里面的vector的实现机制,
(1)当调用push_back成员函数时,怎么实现?(粗略的说@owen,内存足则直接 placement new构造对象,否则扩充内存,转移对象,新对象placement new上去。具体的参见此文:http://blog.csdn.net/v_july_v/article/details/6681522)
(2)当调用clear成员函数时,做什么操作,如果要释放内存该怎么做。(调用析构函数,内存不释放。 clear没有释放内存,只是将数组中的元素置为空了,释放内存需要delete。)
2. 函数foo找错,该函数的作用是将一个字符串中的a-z的字母的频数找出来
void foo(char a[100],int cnt[256])
{
memset(cnt ,0, sizeof(cnt));
while (*a!='\0')
{
++cnt[*a];
++a;
}
for ( char c='a';c<='z';++c)
{
printf("%c:%d\n",c,cnt[c]);
}
}
int main()
{
char a[100]="百度abc";
int cnt[256];
foo(a,cnt);
return 0;
}
- 腾讯长沙笔试:旅行商问题。
- 今天完美10.16笔试题:2D平面上有一个三角形ABC,如何从这个三角形内部随机取一个点,且使得在三角形内部任何点被选取的概率相同。
- 不用任何中间变量,实现strlen函数
- 笔试:联合赋值问题:#include <stdio.h>
union A{
int i;
char x[2];
}a;
int main()
{
a.x[0]=10;
a.x[1]=1;
printf("%d\n",a.i);
return 0;
}
sizeof(a) = sizeof(int) = 4 byte
4 * 8 = 32 bit
a = > 00000000 00000000 00000000 00000000
a.x[0]=10 => 00000000 00000000 00000000 00001010
a.x[1]=1 => 00000000 00000000 00000001 00001010
a.i = 1*256 + 1*8 + 1*2 = 256+10 = 266 - 昨天做了中兴的面试题:
struct A{
int a;
char b;
char c;
};
问sizeof(A)是多大? - 你好:
今天5月6日百度笔试,遇到一个题目,没想到比较好的思路 在网上看了不太明朗,,希望你帮我解答下
题目如下:
百度研发笔试题。设子数组A[0:k]和A[k+1:N-1]已排好序(0≤K≤N-1)。试设计一个合并这2个子数组为排好序的数组A[0:N-1]的算法。要求算法在最坏情况下所用的计算时间为O(N),只用到O(1)的辅助空间。
若论这道题的来源,则是在高德纳的计算机程序设计艺术第三卷第五章排序中,如下(第一张图是原题,第二张图是书上附的答案):

-
百度实习生笔试题:一个单词如果交换其所含字母顺序,得到的单词称为兄弟单词,例如mary和army是兄弟单词,即所含字母是一样的,只是字母顺序不同,用户输入一个单词,要求在一个字典中找出该单词的所有兄弟单词,并输出。给出相应的数据结构及算法。要求时间和空间复杂度尽可能低目前思想:struct {char data;int n};根据数学定理:任何一个大于1的自然数N,都可以唯一分解成有限个质数的乘积 N=(P_1^a1)*(P_2^a2)......(P_n^an) , 这里P_1<P_2<...<P_n是质数,且唯一。例如a=2 b=3 c=5 d=7 e=11...f(abcd)=2*3*5*7=210然后字典里找乘积210的位数相同的一定是这5个字母组合的单词就是兄弟单词
- 更新至2012.05.06下午.....
更多面试题,参见横空出世,席卷Csdn--评微软等数据结构+算法面试100题 (在此文中,集结了本博客已经整理的236道面试题)。
后记
此些面试题看多了,自然会发现题目类型可能会千变万化,但解决问题的思路却只有那么几种。再者,写代码的时候,很多的细节需要务必注意,如返回值,函数参数的检查,特殊情况的处理等等,这是一个代码规范性的问题。有个消息:
-
微软面试全部100题的答案如今已由一朋友阿财做出,微软面试100题2010年版全部答案集锦:http://blog.csdn.net/v_july_v/article/details/6870251,供诸君参考。
ok,日后一有最新的面试题,再整理,有任何问题,欢迎在本文评论下指出或来信指导([email protected]),谢谢。July、2012.05.08。
记:逻辑复杂,题目晦涩,解法不完整,不是每个人都能够潜得下心来,能看懂和坚持