Quartz应用与集群原理分析
一、问题背景
美团CRM系统中每天有大量的后台任务需要调度执行,如构建索引、统计报表、周期同步数据等等,要求任务调度系统具备高可用性、负载均衡特性,可以管理并监控任务的执行流程,以保证任务的正确执行。
二、历史方案
美团CRM系统的任务调度模块经历了以下历史方案。
1. Crontab+SQL
每天晚上运行定时任务,通过SQL脚本+crontab方式执行,例如,
#crm
0 2 * * * /xxx/mtcrm/shell/mtcrm_daily_stat.sql //每天凌晨2:00执行统计
30 7 * * * /xxx/mtcrm/shell/mtcrm_data_fix.sql //每天早上7:30执行数据修复该方案存在以下问题:
- 直接访问数据库,各系统业务接口没有重用。
- 完成复杂业务需求时,会引入过多中间表。
- 业务逻辑计算完全依赖SQL,增大数据库压力。
- 任务失败无法自动恢复。
2. Python+SQL
采用python脚本(多数据源)+SQL方式执行,例如,
def connectCRM():
return MySQLdb.Connection("host1", "uname", "xxx", "crm", 3306, charset="utf8")
def connectTemp():
return MySQLdb.Connection("host1", "uname", "xxx", "temp", 3306, charset="utf8")该方案存在问题:
- 直接访问数据,需要理解各系统的数据结构,无法满足动态任务问题,各系统业务接口没有重用。
- 无负载均衡。
- 任务失败无法恢复。
- 在JAVA语言开发中出现异构,且很难统一到自动部署系统中。
3. Spring+JDK Timer
该方案使用spring+JDK Timer方式,调用接口完成定时任务,在分布式部署环境下,防止多个节点同时运行任务,需要写死host,控制在一台服务器上执行task。
<bean id="accountStatusTaskScanner" class="xxx.crm.service.impl.AccountStatusTaskScanner" />
<task:scheduler id="taskScheduler" pool-size="5" />
<task:scheduled-tasks scheduler="taskScheduler">
<task:scheduled ref="accountStatusTaskScanner" method="execute" cron="0 0 1 * * ?" />
</task:scheduled-tasks>该方案较方案1,2有很大改进,但仍存在以下问题:
- 步骤复杂、分散,任务量增大的情况下,很难扩展
- 使用写死服务器Host的方式执行task,存在单点风险,负载均衡手动完成。
- 应用重启,任务无法自动恢复。
CRM系统定时任务走过了很多弯路:定时任务多种实现方式,使配置和代码分散在多处,难以维护和监控;任务执行过程没有保证,没有错误恢复;任务执行异常没有反馈(邮件);没有集群支持、负载均衡。CRM系统需要分布式的任务调度框架,统一解决问题,Java可以使用的任务调度框架有Quartz,Jcrontab,cron4j,我们选择了Quartz。
三、为什么选择Quartz
Quartz是Java领域最著名的开源任务调度工具。Quartz提供了极为广泛的特性如持久化任务,集群和分布式任务等,其特点如下:
- 完全由Java写成,方便集成(Spring)
- 伸缩性
- 负载均衡
- 高可用性
四、Quartz集群部署实践
CRM中Quartz与Spring结合使用,Spring通过提供org.springframework.scheduling.quartz下的封装类对Quartz支持。
Quartz集群部署:
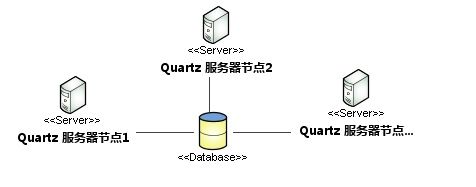
Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点。该集群需要分别对每个节点分别启动或停止,不像应用服务器的集群,独立的Quartz节点并不与另一个节点或是管理节点通信。Quartz应用是通过数据库表来感知到另一应用。只有使用持久的JobStore才能完成Quqrtz集群。
基于Spring的集群配置:
<!-- 调度工厂 -->
<bean id="quartzScheduler"
class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="quartzProperties">
<props>
<prop key="org.quartz.scheduler.instanceName">CRMscheduler</prop>
<prop key="org.quartz.scheduler.instanceId">AUTO</prop>
<!-- 线程池配置 -->
<prop key="org.quartz.threadPool.class">org.quartz.simpl.SimpleThreadPool</prop>
<prop key="org.quartz.threadPool.threadCount">20</prop>
<prop key="org.quartz.threadPool.threadPriority">5</prop>
<!-- JobStore 配置 -->
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTX</prop>
<!-- 集群配置 -->
<prop key="org.quartz.jobStore.isClustered">true</prop>
<prop key="org.quartz.jobStore.clusterCheckinInterval">15000</prop>
<prop key="org.quartz.jobStore.maxMisfiresToHandleAtATime">1</prop>
<prop key="org.quartz.jobStore.misfireThreshold">120000</prop>
<prop key="org.quartz.jobStore.tablePrefix">QRTZ_</prop>
</props>
</property>
<property name="schedulerName" value="CRMscheduler" />
<!--必须的,QuartzScheduler 延时启动,应用启动完后 QuartzScheduler 再启动 -->
<property name="startupDelay" value="30" />
<property name="applicationContextSchedulerContextKey" value="applicationContextKey" />
<!--可选,QuartzScheduler 启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了 -->
<property name="overwriteExistingJobs" value="true" />
<!-- 设置自动启动 -->
<property name="autoStartup" value="true" />
<!-- 注册触发器 -->
<property name="triggers">
<list>
<ref bean="userSyncScannerTrigger" />
......
</list>
</property>
<!-- 注册jobDetail -->
<property name="jobDetails">
<list>
</list>
</property>
<property name="schedulerListeners">
<list>
<ref bean="quartzExceptionSchedulerListener" />
</list>
</property>
</bean>
org.quartz.jobStore.class属性为JobStoreTX,将任务持久化到数据中。因为集群中节点依赖于数据库来传播Scheduler实例的状态,你只能在使用JDBC JobStore时应用Quartz集群。
org.quartz.jobStore.isClustered属性为true,通知Scheduler实例要它参与到一个集群当中。
org.quartz.jobStore.clusterCheckinInterval属性定义了Scheduler实例检入到数据库中的频率(单位:毫秒)。Scheduler检查是否其他的实例到了它们应当检入的时候未检入;这能指出一个失败的Scheduler实例,且当前 Scheduler会以此来接管任何执行失败并可恢复的Job。通过检入操作,Scheduler 也会更新自身的状态记录。clusterChedkinInterval越小,Scheduler节点检查失败的Scheduler实例就越频繁。默认值是 15000 (即15 秒)。
其余参数在后文将会详细介绍。Quartz监控
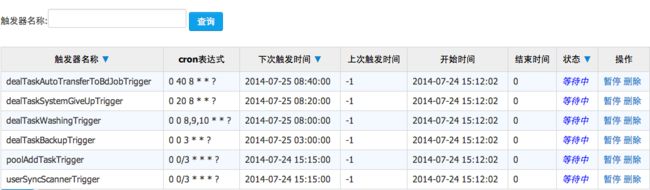
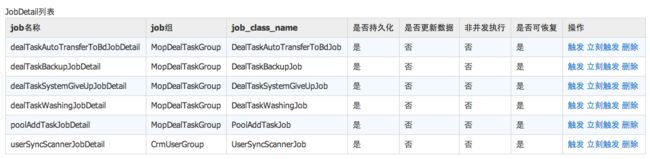
CRM后台目前可以做到对Quartz实例的监控、操作以及动态部署Trigger.
Triggers监控:
JobDetails监控:
五、Quartz集群原理分析
1. Quartz集群数据库表
Quartz的集群部署方案在架构上是分布式的,没有负责集中管理的节点,而是利用数据库锁的方式来实现集群环境下进行并发控制。BTW,分布式部署时需要保证各个节点的系统时间一致。
Quartz数据库核心表如下:
| Table Name | Description |
|---|---|
| QRTZ_CALENDARS | 存储Quartz的Calendar信息 |
| QRTZ_CRON_TRIGGERS | 存储CronTrigger,包括Cron表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的Trigger组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关Scheduler的状态信息,和别的Scheduler实例 |
| QRTZ_LOCKS | 存储程序的悲观锁的信息 |
| QRTZ_JOB_DETAILS | 存储每一个已配置的Job的详细信息 |
| QRTZ_JOB_LISTENERS | 存储有关已配置的JobListener的信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的Trigger,包括重复次数、间隔、以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger作为Blob类型存储 |
| QRTZ_TRIGGER_LISTENERS | 存储已配置的TriggerListener的信息 |
| QRTZ_TRIGGERS | 存储已配置的Trigger的信息 |
其中,QRTZ_LOCKS就是Quartz集群实现同步机制的行锁表,其表结构如下:
--QRTZ_LOCKS表结构
CREATE TABLE `QRTZ_LOCKS` (
`LOCK_NAME` varchar(40) NOT NULL,
PRIMARY KEY (`LOCK_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--QRTZ_LOCKS记录
+-----------------+
| LOCK_NAME |
+-----------------+
| CALENDAR_ACCESS |
| JOB_ACCESS |
| MISFIRE_ACCESS |
| STATE_ACCESS |
| TRIGGER_ACCESS |
+-----------------+可以看出QRTZ_LOCKS中有5条记录,代表5把锁,分别用于实现多个Quartz Node对Job、Trigger、Calendar访问的同步控制。
2. Quartz线程模型
在Quartz中有两类线程:Scheduler调度线程和任务执行线程。任务执行线程:Quartz不会在主线程(QuartzSchedulerThread)中处理用户的Job。Quartz把线程管理的职责委托给ThreadPool,一般的设置使用SimpleThreadPool。SimpleThreadPool创建了一定数量的WorkerThread实例来使得Job能够在线程中进行处理。WorkerThread是定义在SimpleThreadPool类中的内部类,它实质上就是一个线程。例如,CRM中配置如下:
<!-- 线程池配置 -->
<prop key="org.quartz.threadPool.class">org.quartz.simpl.SimpleThreadPool</prop>
<prop key="org.quartz.threadPool.threadCount">20</prop>
<prop key="org.quartz.threadPool.threadPriority">5</prop>QuartzSchedulerThread调度主线程:QuartzScheduler被创建时创建一个QuartzSchedulerThread实例。
3. 集群源码分析
Quartz究竟是如何保证集群情况下trgger处理的信息同步?
下面跟着源码一步一步分析,QuartzSchedulerThread包含有决定何时下一个Job将被触发的处理循环,主要逻辑在其run()方法中:
public void run() {
boolean lastAcquireFailed = false;
while (!halted.get()) {
......
int availThreadCount = qsRsrcs.getThreadPool().blockForAvailableThreads();
if(availThreadCount > 0) {
......
//调度器在trigger队列中寻找30秒内一定数目的trigger(需要保证集群节点的系统时间一致)
triggers = qsRsrcs.getJobStore().acquireNextTriggers(
now + idleWaitTime, Math.min(availThreadCount, qsRsrcs.getMaxBatchSize()), qsRsrcs.getBatchTimeWindow());
......
//触发trigger
List<TriggerFiredResult> res = qsRsrcs.getJobStore().triggersFired(triggers);
......
//释放trigger
for (int i = 0; i < triggers.size(); i++) {
qsRsrcs.getJobStore().releaseAcquiredTrigger(triggers.get(i));
}
}
}由此可知,QuartzScheduler调度线程不断获取trigger,触发trigger,释放trigger。下面分析trigger的获取过程,qsRsrcs.getJobStore()返回对象是JobStore,集群环境配置如下:
<!-- JobStore 配置 -->
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTX</prop>JobStoreTX继承自JobStoreSupport,而JobStoreSupport的acquireNextTriggers、triggersFired、releaseAcquiredTrigger方法负责具体trigger相关操作,都必须获得TRIGGER_ACCESS锁。核心逻辑在executeInNonManagedTXLock方法中:
protected <T> T executeInNonManagedTXLock(
String lockName,
TransactionCallback<T> txCallback, final TransactionValidator<T> txValidator) throws JobPersistenceException {
boolean transOwner = false;
Connection conn = null;
try {
if (lockName != null) {
if (getLockHandler().requiresConnection()) {
conn = getNonManagedTXConnection();
}
//获取锁
transOwner = getLockHandler().obtainLock(conn, lockName);
}
if (conn == null) {
conn = getNonManagedTXConnection();
}
final T result = txCallback.execute(conn);
try {
commitConnection(conn);
} catch (JobPersistenceException e) {
rollbackConnection(conn);
if (txValidator == null || !retryExecuteInNonManagedTXLock(lockName, new TransactionCallback<Boolean>() {
@Override
public Boolean execute(Connection conn) throws JobPersistenceException {
return txValidator.validate(conn, result);
}
})) {
throw e;
}
}
Long sigTime = clearAndGetSignalSchedulingChangeOnTxCompletion();
if(sigTime != null && sigTime >= 0) {
signalSchedulingChangeImmediately(sigTime);
}
return result;
} catch (JobPersistenceException e) {
rollbackConnection(conn);
throw e;
} catch (RuntimeException e) {
rollbackConnection(conn);
throw new JobPersistenceException("Unexpected runtime exception: "
+ e.getMessage(), e);
} finally {
try {
releaseLock(lockName, transOwner); //释放锁
} finally {
cleanupConnection(conn);
}
}
}由上代码可知Quartz集群基于数据库锁的同步操作流程如下图所示:
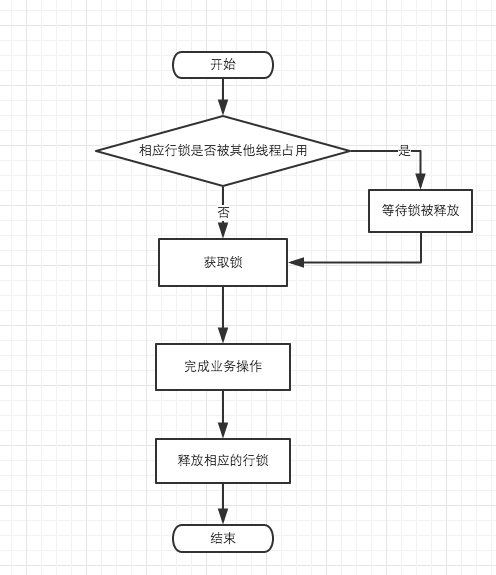
一个调度器实例在执行涉及到分布式问题的数据库操作前,首先要获取QUARTZ_LOCKS表中对应的行级锁,获取锁后即可执行其他表中的数据库操作,随着操作事务的提交,行级锁被释放,供其他调度实例获取。集群中的每一个调度器实例都遵循这样一种严格的操作规程。
getLockHandler()方法返回的对象类型是Semaphore,获取锁和释放锁的具体逻辑由该对象维护
public interface Semaphore {
boolean obtainLock(Connection conn, String lockName) throws LockException;
void releaseLock(String lockName) throws LockException;
boolean requiresConnection();
}该接口的实现类完成具体操作锁的逻辑,在JobStoreSupport的初始化方法中注入的Semaphore具体类型是StdRowLockSemaphore
setLockHandler(new StdRowLockSemaphore(getTablePrefix(), getInstanceName(), getSelectWithLockSQL()));StdRowLockSemaphore的源码如下所示:
public class StdRowLockSemaphore extends DBSemaphore {
//锁定SQL语句
public static final String SELECT_FOR_LOCK = "SELECT * FROM "
+ TABLE_PREFIX_SUBST + TABLE_LOCKS + " WHERE " + COL_LOCK_NAME
+ " = ? FOR UPDATE";
public static final String INSERT_LOCK = "INSERT INTO " + TABLE_PREFIX_SUBST
+ TABLE_LOCKS + "(" + COL_SCHEDULER_NAME + ", "
+ COL_LOCK_NAME + ") VALUES (" + SCHED_NAME_SUBST + ", ?)";
//指定锁定SQL
protected void executeSQL(Connection conn, String lockName, String expandedSQL) throws LockException {
PreparedStatement ps = null;
ResultSet rs = null;
try {
ps = conn.prepareStatement(expandedSQL);
ps.setString(1, lockName);
......
rs = ps.executeQuery();
if (!rs.next()) {
throw new SQLException(Util.rtp(
"No row exists in table " + TABLE_PREFIX_SUBST +
TABLE_LOCKS + " for lock named: " + lockName, getTablePrefix()));
}
} catch (SQLException sqle) {
} finally {
...... //release resources
}
}
}
//获取QRTZ_LOCKS行级锁
public boolean obtainLock(Connection conn, String lockName) throws LockException {
lockName = lockName.intern();
if (!isLockOwner(conn, lockName)) {
executeSQL(conn, lockName, expandedSQL);
getThreadLocks().add(lockName);
}
return true;
}
//释放QRTZ_LOCKS行级锁
public void releaseLock(Connection conn, String lockName) {
lockName = lockName.intern();
if (isLockOwner(conn, lockName)) {
getThreadLocks().remove(lockName);
}
......
}至此,总结一下Quartz集群同步机制:每当要进行与某种业务相关的数据库操作时,先去QRTZ_LOCKS表中查询操作相关的业务对象所需要的锁,在select语句之后加for update来实现。例如,TRIGGER_ACCESS表示对任务触发器相关的信息进行修改、删除操作时所需要获得的锁。这时,执行查询这个表数据的SQL形如:
select * from QRTZ_LOCKS t where t.lock_name='TRIGGER_ACCESS' for update当一个线程使用上述的SQL对表中的数据执行查询操作时,若查询结果中包含相关的行,数据库就对该行进行ROW LOCK;若此时,另外一个线程使用相同的SQL对表的数据进行查询,由于查询出的数据行已经被数据库锁住了,此时这个线程就只能等待,直到拥有该行锁的线程完成了相关的业务操作,执行了commit动作后,数据库才会释放了相关行的锁,这个线程才能继续执行。
通过这样的机制,在集群环境下,结合悲观锁的机制就可以防止一个线程对数据库数据的操作的结果被另外一个线程所覆盖,从而可以避免一些难以觉察的错误发生。当然,达到这种效果的前提是需要把Connection设置为手动提交,即autoCommit为false。
六、参考资料
- http://quartz-scheduler.org/documentation Quartz Documentation
- http://www.ibm.com/developerworks/cn/opensource/os-cn-quartz 基于Quartz开发企业级任务调度应用