C++ 异常机制
C++ 异常机制
一、函数的栈结构
在C++中的函数调用中,是用栈来存放其中数据对象。

表1.1
我们结合这张表,来简单介绍函数的栈结构。
其中每一个函数在入栈的时候,编译器会自动添加额外的数据结构,这里的EXCEPTION_REGISTRATION就是被额外添加进来的。对于这个结构体我们稍后解释,首先来介绍函数的基本结构。
从这张图中可以清楚的看到,在函数的栈结构中,会存放的是函数的参数和局部变量,这些对象在函数结束的时候都会被析构掉,在之后会介绍这一个清理的过程。
我们还注意到每一个函数都有一个ESP,这个ESP可以被认为一个分界,下一个函数可以这之后开始存放它的数据对象。(这里是栈,我们的顺序是从下至上)
接下我们来介绍EXCEPTION_REGISTRATION这个结构体
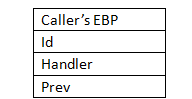
表1.2
第一个成员中有一个EBP。这个EBP是用来标识当前的栈活动帧,简单来说就是指明当前我们在执行哪一个函数。
所以Caller’s EBP可以帮我们去找到调用函数。
第二个成员id表明函数的执行状态和进度。这一个id在栈回退和异常捕获中都扮演至关重要的角色,我会在之后联系C++的栈回退机制进行详细的介绍。
第三个成员Handler,它的工作便是将当前函数的信息funinfo传给__CxxFrameHandler,然后由它全权处理异常。处理的过程会在之后做介绍。
第四个成员Prev,可以通过Prev找到上一层的异常处理,比如这里Fun2的EXCEPTION_REGISTRATION中的prev便是指向fun1的EXCEPTION_REGISTRATION。
这里还有一个FS:[0]。EXCEPTION_REGISTRATION中的prev将栈中的EXCEPTION_REGISTRATION连成了一个链表,这里我就暂时就叫它异常处理链。而FS:[0]就保存了这个链表的第一个节点。当一个异常抛出的时候,便可以通过它来找到第一个异常处理。
二、异常的抛出
Throw Exception();
上面这个抛出异常的语句。编译器会对它做一定的处理,变成如下:
E e = E(); //create exception on the stack _CxxThrowException(&e, E_EXCPT_INFO_ADDR);
其中主要是将异常对象e传给_CxxThrowException,并保存待抛出异常对象的起始地址、用于销毁它的析构函数,以及它的 type_info 信息。
然后通过FS:[0]调用到了异常处理EXCEPTION_REGISTRATION中的hanlder进行了处理。
三、栈回退机制
首先来介绍一个非常重要的机制,栈回退机制
先来看一下一个具体的例子。
void fun(BOOL b)
{
try
{
ClassA obj1,obj2;
if(b)
{
ClassB obj3;
}
ClassB obj4;
……
}
catch(CException* e)
{
}
}
这里编译器在编译这段代码的时候,会做一定的处理,下面便是处理过后的代码
void fun(BOOL b)
{
id = 0;
try
{
id = 1;//try代码段开始
ClassA obj1,obj2;
obj1.ClassA(); id = 2;
obj2.ClassA(); id = 3;
if(b)
{
ClassB obj3;
obj3.ClassB(); id = 4;
obj3.~ClassB(); id = 5;
}
ClassB obj4;
obj4.ClassB(); id = 6;
……
obj4.~ClassB();
id = 7; //try代码段结束
}
catch(CException* e)
{
}
}
在每一个函数中都会有一个回退表,里面存放了如何帮助栈回退的信息
我们把上面的函数的回退表大致列出来
表3.1
对于这张表稍作解释
第一列id便是函数中执行到了第几步;
第二列iNextId是为了执行完表格中当前行析构后,找到下一行的执行行;
第三列pFunDestory存放了析构函数指针,通过第四列的pObj机上EBP便可以交由析构函数处理。
当然如果在执行到id = 6后抛出了异常,那么当前的id便是6 我们就去回退表中找id = 6的行,开始执行。一直执行到iNextId = -1 停止。
如果一个构造函数抛出了异常了,那么按照C++的异常机制是不会执行到它的析构函数的。就以上面这个例子,比如obj2在构造的时候抛出了异常了,那么按照前面讨论的,异常处理机制清理对象,那么这个时候id还只是2,按照上面的unwind_table中的顺序,析构完obj1后便会结束了,obj2就永远不会析构掉。
四、异常的捕获
我们会向第一节讲到函数的栈结构中,有提到一个funinfo这个结构中保存了当前函数的信息。
表4.1
其中unwind_table便是上一节讲到的回退表。tryblock_table便是这里异常捕获的关键。
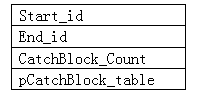
表4.2
这个结构便是tryblock_table。
这里Start_id 便是try代码段开始,在上一节的例子中Start_id便是1;而End_id便是7。
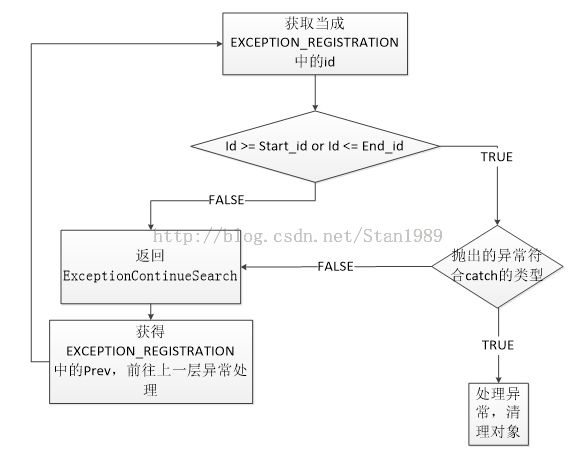
图4.1
结合图4.1,我们来了解这个流程。当抛出异常的时候,系统会将异常传给_CxxThrowException(回忆第二节中的异常抛出介绍)。
接着系统通过FS:[0]找到异常链的头,从而获得EXCEPTION_REGISTRATION中的id(联系第三节中栈回退机制,这个id标识当前函数执行到了第几步)。
然后在当前函数的funinfo中的tryblock_table中判断id是否落在了Start_id和End_id之间(包括id = Start_id 和 id = End_id这两种情况):
(1)如果id落在了try的范围内:
这个时候我们就要去判断,当前我们抛出的异常和catch中的参数是否一个类型的。
这里我们会用到C++的一个RTTI(run time type identification)机制,这样就可以进行判断了:
如果抛出异常符合catch的要求,就进入catch,进行异常处理,包括函数对象的清理;如果抛出异常不符合catch的要求,就转向步骤(3)
(2)如果id不在try范围内,便转向步骤(3)
(3)返回ExceptionContinueSearch,我们就会通过EXCEPTION_REGISTRATION中的prev找到上一层的异常处理,交由它处理,转向步骤(1)。
上面的过程将会一直继续,直到抛出异常被catch住,或者系统已经走到了异常链的尾端。
上述的操作在__CxxFrameHandler中执行,回忆一下,第一节中介绍的EXCEPTION_REGISTRATION中handler,它做得处理便是将函数的信息funinfo交给了__CxxFrameHandler。
最后这里有两篇文章关于C++的异常机制:
How a C++ compiler implements exception handling
C++异常机制的实现方式和开销分析