python爬虫Pragmatic系列III
python爬虫Pragmatic系列III
By 白熊花田(http://blog.csdn.net/whiterbear)
说明:
在上一篇博客中,我们已经学会了从赶集网上的一家公司中提取出有关的信息,并存储到Excel中。
本次目标:
在本节中,我们将批量下载赶集首页上所有的公司界面(注意不是赶集网上所有的公司页面,我们可以把这个留给之后的任务),并批量的处理所有公司的有关信息,并保存到Excel中。
注意:
在上一篇博客中,我们使用的只是匹配赶集网上其中一家公司界面的中信息,而且不幸的是,很多的其他的公司的联系店主模块中的信息数量并不是固定的,即有的是10个li,而有的是9个li或者12个li,而且并不是所有公司都提供了QQ联系方式或者公司名称。所以,我对代码稍微做了处理,使其能够适应大部分的网页。
批量下载网页:
如下图:
我们将提取出该网页所包含的公司链接,并批量下载下来。这次,我们使用了一个下载类,利用下载类来封装我们所要的方法。我们先给定赶集网的首页链接,下载首页,接着我们分析出首页包含的公司链接并保存起来,最后我们将这些链接都下载到pagestroage文件夹中。
代码:
#-*-coding:utf-8-*-
import re
import os
from urllib import urlretrieve
from bs4 import BeautifulSoup
class Download(object):
'该类将包含下载给定的url和将其保存\
为相应的文件的方法'
def __init__(self):
self.index = 0
#初始化
def getPages(self,url,isMain=False):
'根据给定的url进行下载,如果是赶集网主界面,则另行处理'
for u in url:
try:
revtal = urlretrieve(u)[0]
except IOError:
revtal = None
if revtal <> None and isMain == True:
#是赶集网主界面
self.savePages(revtal, isMain=True)
elif revtal <> None and isMain <> True:
self.savePages(revtal)
else:
print('Open url error')
def savePages(self,webpage,isMain=False):
'将给定的网页保存起来'
f = open(webpage)
lines = f.readlines()
f.close()
if isMain == False:
#不是主界面则按序存储为filei.txt,i为序号
fobj = open("pagestroage\\file%s.txt"%str(self.index), 'w')
self.index += 1
fobj.writelines(lines)
else:
#是赶集网主界面,则存储为mian.txt
fobj = open("pagestroage\main.txt",'w')
fobj.writelines(lines)
fobj.close()
def getAllComUrls(self):
'我们对赶集网的主界面进行分析,提取出所有公司的链接,保存起来'
if os.path.exists('pagestroage\main.txt'): #判断文件是否存在
fobj = open('pagestroage\main.txt','r')
lines = fobj.readlines()
fobj.close()
soup = BeautifulSoup(''.join(lines))
body = soup.body
#wrapper = soup.find(id="wrapper")
leftBox = soup.find(attrs={'class':'leftBox'})
list_ = leftBox.find(attrs={'class':'list'})
ul = list_.find('ul')
li = ul.find_all('li')
href_regex = r'href="(.*?)"'
urls = []
for l in li:
urls.append('http://bj.ganji.com' + re.search(href_regex,str(l)).group(1))
#print urls
return urls
else:
print('The file is missing')
return None
if __name__ == '__main__':
#初试设定url为赶集网首页
url=['http://bj.ganji.com/danbaobaoxian/o1/']
#实例化下载类
download = Download()
#先下载赶集网首页
download.getPages(url,True)
#对下载的赶集网首页信息进行分析,提取出所有公司的url
urls = download.getAllComUrls()
#对上面提取的url进行下载
download.getPages(urls)
运行结果:
我们得到了十几个包含公司网页的文本文件。如下图:
分析网页:
由上面的操作,我们已经得到了赶集网上所有公司的html文本。接着我们使用Analysiser类来处理我们得到的数据。注意,Analysiser类中的方法基本上都在前面的博客中介绍了,这里只是用类封装了,并使其能够批量处理。
代码:
#-*-coding:utf-8-*-
import re
from bs4 import BeautifulSoup
import xlwt
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
class Analysiser(object):
'该类将分析下载的公司信息存储到Excel表格中'
def __init__(self):
'初始化一个Excel'
self.wb = xlwt.Workbook()
self.ws = self.wb.add_sheet('CompanyInfoSheet')
self.initExcel()
def initExcel(self):
'我们初试化一个表格,并给表格一个头部,所以我们给头部不一样的字体'
#初始化样式
style = xlwt.XFStyle()
#为样式创建字体
font = xlwt.Font()
font.name = 'Times New Roman'
font.bold = True
#为样式设置字体
style.font = font
# 使用样式
#写入公司名称
self.ws.write(0,0,u'公司名称', style)
#写入服务特色
self.ws.write(0,1,u'服务特色', style)
#写入服务范围
self.ws.write(0,2,u'服务范围', style)
#写入联系人
self.ws.write(0,3,u'联系人', style)
#写入商家地址
self.ws.write(0,4,u'商家地址', style)
#写入聊天QQ
self.ws.write(0,5,u'QQ', style)
#写入联系电话
self.ws.write(0,6,u'联系电话', style)
#写入网址
self.ws.write(0,7,u'公司网址', style)
self.wb.save('xinrui.xls')
def analysAllFiles(self):
'''
批量分析网页源码,并提取出公司相关信息
'''
#得到pagestroage(我们存放下载的公司网页的文件夹)下所有的文件
filenames = os.listdir('pagestroage')
#得到所有存储的公司数目(去除一个包含赶集网首页的main.txt)
counts = len(filenames) - 1
#循环处理
for i in range(counts):
#打开文件,读文件到lines中,关闭文件对象
f = open("pagestroage\\file%s.txt"%i, 'r')
lines = f.readlines()
f.close()
#这两个网页的联系店主模块与其他的不一样,如果也要匹配只能重新写代码匹配,遂放弃
if i == 12 or i == 7:
continue
#建立一个BeautifulSoup解析树,并利用这课解析树依次按照
#soup-->body-->(id为wrapper的div层)-->(class属性为clearfix的div层)
#-->(id为dzcontactus的div层)-->(class属性为con的div层)-->ul-->(ul下的每个li)
soup = BeautifulSoup(''.join(lines))
body = soup.body #body2 = soup.find('body')
wrapper = soup.find(id="wrapper")
clearfix = wrapper.find_all(attrs={'class':'d-left-box'})[0]
dzcontactus = clearfix.find(id="dzcontactus")
con = dzcontactus.find(attrs={'class':'con'})
ul = con.find('ul')
li = ul.find_all('li')
#记录一家公司的所有信息,用字典存储,可以依靠键值对存取,也可以换成列表存储
record = {}
#公司名称
companyName = li[1].find('h1').contents[0]
record['companyName'] = companyName
#服务特色
serviceFeature = li[2].find('p').contents[0]
record['serviceFeature'] = serviceFeature
#服务提供
serviceProvider = []
serviceProviderResultSet = li[3].find_all('a')
for service in serviceProviderResultSet:
serviceProvider.append(service.contents[0])
record['serviceProvider'] = serviceProvider
#服务范围
serviceScope = []
serviceScopeResultSet = li[4].find_all('a')
for scope in serviceScopeResultSet:
serviceScope.append(scope.contents[0])
record['serviceScope'] = serviceScope
#联系人
contacts = li[5].find('p').contents[0]
contacts = str(contacts).strip().encode("utf-8")
record['contacts'] = contacts
#商家地址
addressResultSet = li[6].find('p')
re_h=re.compile('</?\w+[^>]*>')#HTML标签
address = re_h.sub('', str(addressResultSet))
record['address'] = address.encode("utf-8")
restli = ''
for l in range(8,len(li) - 1):
restli += str(li[l])
#商家QQ
qqNumResultSet = restli
qq_regex = '(\d{5,10})'
qqNum = re.search(qq_regex,qqNumResultSet).group()
qqNum = qqNum
record['qqNum'] = qqNum
#联系电话
phone_regex= '1[3|5|7|8|][0-9]{9}'
phoneNum = re.search(phone_regex,restli).group()
record['phoneNum'] = phoneNum
#公司网址
companySite = li[len(li) - 1].find('a').contents[0]
record['companySite'] = companySite
self.writeToExcel(record,i + 1)
def writeToExcel(self,record,index):
'该函数将给定的record字典中所有值存储到Excel相应的index行中'
#写入公司名称
companyName = record['companyName']
self.ws.write(index,0,companyName)
#写入服务特色
serviceFeature = record['serviceFeature']
self.ws.write(index,1,serviceFeature)
#写入服务范围
serviceScope = ','.join(record['serviceScope'])
self.ws.write(index,2,serviceScope)
#写入联系人
contacts = record['contacts']
self.ws.write(index,3,contacts.decode("utf-8"))
#写入商家地址
address = record['address']
self.ws.write(index,4,address.decode("utf-8"))
#写入聊天QQ
qqNum = record['qqNum']
self.ws.write(index,5,qqNum)
#写入联系电话
phoneNum = record['phoneNum']
phoneNum = str(phoneNum).encode("utf-8")
self.ws.write(index,6,phoneNum.decode("utf-8"))
#写入网址
companySite = record['companySite']
self.ws.write(index,7,companySite)
self.wb.save('xinrui.xls')
if __name__ == '__main__':
ana = Analysiser()
ana.analysAllFiles()
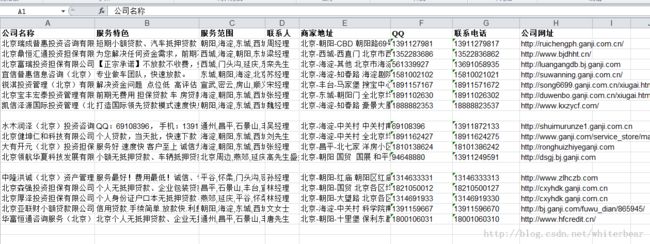
运行结果:
我们将得到包含赶集网首页上包含的所有公司的相关信息的Excel,如下图:
后感:
看到这个Excel是不觉得很cool,终于能做点实际的事情了。
不过,我们还可以做的更好,更智能。
未完待续。