OpenMP多线程应用程序编程技术
2.1 循环并行化
1、循环并行化编译指导语句的格式
循环并行化是使用OpenMP来并行化程序的最重要的部分,它是并行区域编程的一个特例。在C/C++语言中,循环并行化语句的编译指导语句格式如下:
#pragma omp parallel for [clause[clause…]]
for( index = first ; test_expression ; increment_expr){
body of the loop;
}
2、循环并行化语句的限制
并不是所有的循环语句都能够在其前面加上#pragma omp parallel来实现并行话,需要进行并行化的语句有一定的限制。首先是并行化的语句必须是for循环语句并具有规范的格式,能够推测出循环的次数。因此,循环并行化的语句必须具有如下的形式
for (index = start ; index < end ; increment_expr)
还有一个重要的限制即循环语句块应该是单出口与单入口的,对于其它的并行化编译指导语句来说也具有类似的限制。在循环内部可以使用exit函数来退出整个程序,某一个线程执行这个函数之后,会同步其它所有的线程来退出程序,退出时的状态是不确定的。
3、简单循环并行化
在编译器和运行时库的帮助下,根据环境变量的配置,OpenMP程序中循环任务被分配到相应的线程当中,各个线程相互独立,各自完成相应的任务后,整个并行程序就完成了工作。
4、循环并行化编译指导语句的子句
循环并行化子句可以包含一个或者多个子句来控制循环并行化的实际执行。有多个类型的子句可以用来控制循环并行化编译。最主要的子句是数据作用域子句。这里的作用域用来控制某一个变量是否是在各个线程之间共享或者是某一个线程是私有的。数据的作用域子句用shared来表示一个变量是各个线程之间共享的,而用private来表示一个变量是每一个线程私有的。在OpenMP中,如果没有指定变量的作用域,则默认的变量作用域是共享的,这与OpenMP对应的共享内存空间编程模型是相互符合的。
5、循环嵌套
在一个循环体内经常会包含另外一个循环体,循环产生了嵌套。在OpenMP中,我们可以将嵌套循环的任意一个循环体进行并行化。循环并行化编译指导语句可以加在任意一个循环之前,则对应的最近的循环语句被并行化,其它部分保持不变。因此,实际上并行化是作用于嵌套循环中的某一个循环,其它部分由执行到的线程负责执行。
6、控制数据的共享属性
OpenMP程序在同一个共享内存空间上执行,由于可以任意使用这个共享内存空间上的变量进行线程间的数据传递,使得线程通信非常容易。一个线程可以写入一个变量而另外一个线程则可以读取这个变量来完成线程间的通信。
|
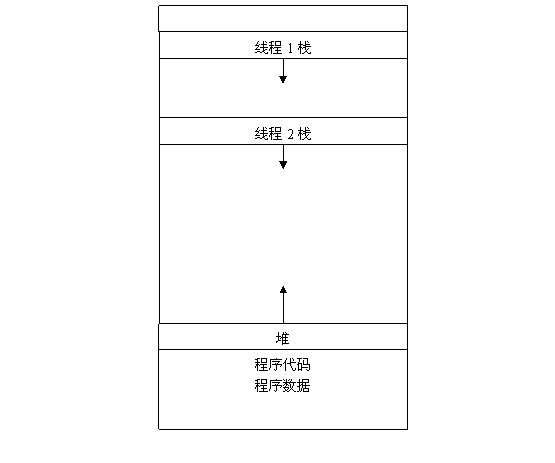
上述图6. 7给出了多线程应用程序的内存分布结构。可以看出,每一个线程的栈空间都是私有的,因此分配在栈上的数据都是线程私有的。全局变量以及程序代码都是全局共享的;而动态分配的堆空间也是共享的。数据作用域子句用来确定数据的共享属性,有下面四个子句。
shared用来显示定义一个变量作用域是共享的。private用来显示定义一个变量作用域是私有的。firstprivate和lastprivate分别对私有的变量进行初始化的操作和最后终结的操作。firstprivate将串行的变量值拷贝的同名的私有变量中,在每一个线程开始执行的时候初始化一次。而lastprivate则将并行执行中的最后一次循环的私有变量值拷贝的同名的串行变量中。default语句用来改变变量的默认私有属性。
7、规约操作的并行化
一类经常需要并行化的计算是规约操作。在规约操作中,会反复将一个二元运算符应用在一个变量和另外一个值上,并把结果保存在原变量中。一个常见的规约操作就是数组求和,使用一个变量保存部分和,并把数组中的每一个值加到这个变量中,就可以得出最后所有数组的总和。OpenMP对于这一类规约操作提供了特殊的支持,在使用规约操作时,只需在变量前指明规约操作的类型以及规约的变量。下面是一个规约操作的实例,分别计算两个数组中数值的总和。
程序 6. 6
# pragma omp parallel for private(arx,ary,n) reduction(+:a,b)
for(i=0;i<n;i++){
a=a+arx[i];
b=b+ary[i];
}
并不是所有的操作都能够使用规约操作。规约操作只对语法内建的数值数据类型有效,对其他类型则无效。如果对其它类型或者用户自定义的类型,则必须使用同步语句来对共享变量进行保护。
8、私有变量的初始化和终结操作
对于线程私有的变量,在每一个线程开始创建执行的时候其值是未确定的。OpenMP编译指导语句也对于这种需求给予支持,即使用firstprivate和lastprivate对这两种需求进行支持,使得循环并行开始执行的时候私有变量通过主线程中的变量初始化,同时循环并行结束的时候,将最后一次循环的相应变量赋值给主线程的变量。
9、数据相关性与并行化操作
并不是所有的循环都能够使用#pragma omp parallel for来进行并行化。为了对一个循环进行并行化操作,我们必须要保证数据两次循环之间不存在数据相关性。数据相关性又被称为数据竞争(Data Race)。
为了将一个循环并行化,而不影响程序的正确性,需要仔细检查程序使得程序在并行化之后,两个线程之间不能够出现数据竞争。在能够保证得出正确结果的情况下,可以允许存在数据竞争,并将循环并行化。在出现数据竞争的时候,我们可以通过增加适当的同步操作,或者通过程序改写来消除竞争。
在进行并行化的过程中,我们必须要仔细分析循环之间的数据相关性,在某些时候,可以通过程序改写,消除产生并行化的原因,才能获得并行应用程序。
2.2 并行区域编程
并行区域简单的说就是通过循环并行化编译指导语句使得一段代码能够在多个线程内部同时执行。
1、并行区域编译指导语句的格式与使用限制
在C/C++语言中,并行区域编写的格式如下所示:
#pragma omp parallel [clause[clause]…]
block
程序块必须是一个只有单一入口和单一出口的程序块,在程序块内部直接调用exit函数来退出整个程序的执行也是允许的。
2、parallel编译指导语句的执行过程
程序 6. 9
#pragma omp parallel
for(int i=0;i<5;i++)
printf("hello world i=%d\n",i);
程序的执行结果:
hello world i=0
hello world i=0
hello world i=1
hello world i=1
hello world i=2
hello world i=2
hello world i=3
hello world i=3
hello world i=4
hello world i=4
程序 6. 10
#pragma omp parallel for
for(int i=0;i<5;i++)
printf("hello world i=%d\n",i);
程序的执行结果:
hello world i=0
hello world i=3
hello world i=1
hello world i=4
hello world i=2
可以看到,两个程序唯一的区别在于程序中黑体标出的for。(在执行的过程中,环境变量OMP_NUM_THREADS=2。)从这两个执行结果中我们可以明显地看到并行区域与循环并行化的区别,即并行区域采用了复制执行的方式,将代码在所有的线程内部都执行一次;而循环并行化则采用了工作分配的执行方式,将循环所需要的所有工作量按照一定的方式分配到各个执行线程中,所有线程执行工作的总和是原先串行执行所完成的工作量。
总结上述的并行区域parallel语句的作用是当程序遇到parallel编译指导语句的时候,就会生成相应数目(根据环境变量)的线程组成一个线程组,并将代码重复地在各个线程内部执行。parallel的末尾有一个隐含的同步屏障(barrier),所有线程完成所需的重复任务有,在这个同步屏障出会和(join)。此时,此线程组的主线程(master)继续执行,而相应的子线程(slave)则停止执行。
3、线程私有数据与threadprivate,copyin子句
对于每一个线程来说,可能需要生成自己私有的线程数据,此时,就需要使用threadprivate子句用来标明某一个变量是线程私有数据,在程序运行的过程中,不能够被其它线程访问到。
程序 6. 11
int counter=0;
#pragma omp threadprivate(counter) //using threadprivate
void inc_counter()
{
counter++;
}
int _tmain(int argc, TCHAR * argv[])
{
#pragma omp parallel
for(int i=0;i<10000;i++)
inc_counter();
printf("counter=%d\n",counter);
}
执行过程最后结果都为:
counter=10000
而如果将含有注释的那一行删除,就将全局变量counter变为共享,执行可能的结果:
counter=15194
可以明显看到出现了数据相关性。
对于所有的线程私有全局变量来说,除了主线程,其它线程的私有变量在运行过程中是没有初始化的,为了使用主线程的变量初始化的值,我们使用copyin子句对线程私有的全局变量进行初始化。
程序 6. 12
int global=0;
#pragma omp threadprivate(global)
int _tmain(int argc, TCHAR * argv[])
{
global=1000;
#pragma omp parallel copyin(global)
{
printf("global=%d\n",global);
global=omp_get_thread_num();
}
printf("global=%d\n",global);
printf("parallel again\n");
#pragma omp parallel
printf("global=%d\n",global);
}
程序的执行结果为:
global=1000
global=1000
global=0
parallel again
global=0
global=1
可以看出,通过copyin的操作,确实将线程的私有变量初始化为主线程中相应的全局变量的值。在并行区域执行完毕退出后,主线程与子线程中的相应的全局变量继续有效,并且在在一次进入并行区域时,使用上一次退出时所赋的值。
4、并行区域之间的工作共享
在通常的并行程序编写中,一般会使用工作队列的方式将工作放置到一个队列中,每一个线程每次从队列中获取一件工作。而在OpenMP程序中,可以利用这个线程号来获得不同的工作任务执行。实际上,在OpenMP支持的语法中,可以直接使用编译指导语句for将任务分配到各个线程,就像前一节所说的循环并行化一样;另外,也可以用sections编译指导语句以及section子句自然地将不同的工作任务编写成不同的代码片段并行执行。
5、工作队列
工作队列的基本工作过程即为维持一个工作的队列,线程在并行执行的时候,不断从这个队列中取出相应的工作完成,直到队列为空为止。
程序 6. 13
int next_task=0;
int get_next_task()
{
int task;
#pragma omp critical //用来做同步操作
if(next_task<MAX_TASK){
task=next_task;
next_task++;
}else
task=-1;
return task;
}
void task_queue()
{
int my_task;
#pragma omp parallel private(my_task)
{
my_task=get_next_task();
while(my_task!=-1){
get_task_done(my_task);
my_task=get_next_task();
}
}
}
上述程序的并行部分不断从一个任务队列中取出相应的任务完成,直到完成任务队列中的所有任务。
6、根据线程号分配任务
由于每一个线程在执行的过程中的线程标识号是不同的,可以根据这个线程标识号来分配不同的任务,下面的例子程序就演示了如何根据线程标识号来完成不同的任务。
程序 6. 14
#pragma omp parallel private(myid)
{
nthreads=omp_get_num_threads();
myid=omp_get_thread_num();
get_my_work_done(myid,nthreads);
}
在上述的程序中,首先获得当前所有线程的数目,并且根据线程的总数以及相应的线程标识号来确定相应的工作,完成任务的并行分配。
7、使用循环语句分配任务
循环并行化是可以单独在并行化区域中出现的,每一个循环中的任务就被分配到各个工作线程中。
程序 6. 15
#pragma omp parallel
{
printf("outside loop thread=%d\n",omp_get_thread_num());
#pragma omp for
for(int i=0;i<4;i++)
printf("inside loop i=%d thread=%d\n",i,omp_get_thread_num());
}
程序的运行结果:
outside loop thread=0
outside loop thread=1
inside loop i=2 thread=1
inside loop i=0 thread=0
inside loop i=3 thread=1
inside loop i=1 thread=0
可以看出,在循环的外部,程序代码被各个线程复制执行,而在循环的内部,循环的所有任务被各个线程分别完成。从总体上来说,循环执行的次数与串行执行的次数一致。
实际上,在OpenMP编程规范中已经对能够在不同的线程中执行不同的任务有所支持。使用工作分区(sections)的方法就能够达到这一点。
8、工作分区编码(sections)
下面是一个工作分区编码的实例
程序 6. 16
#pragma omp parallel sections
{
#pragma omp section
printf("section 1 thread=%d\n",omp_get_thread_num());
#pragma omp section
printf("section 2 thread=%d\n",omp_get_thread_num());
#pragma omp section
printf("sectino 3 thread=%d\n",omp_get_thread_num());
}
程序运行结果为:
section 1 thread=0
section 2 thread=1
sectino 3 thread=0
可以看到,在使用工作分区编码的时候,各个线程自动从各个分区中获得任务执行。并且在执行完一个分区的时候,如果分区组里面还有未完成的工作,则继续取得任务完成。
2.3 线程同步
OpenMP支持两种不同类型的线程同步机制,一种是互斥锁的机制,可以用来保护一块共享的存储空间,使得每一次访问这块共享内存空间的线程最多一个,保证了数据的完整性;另外一种同步机制是事件通知机制,这种机制保证了多个线程之间的执行顺序。
1、互斥锁机制
在OpenMP中,提供了三种不同的互斥锁机制用来对一块内存进行保护,它们分别是临界区(critical),原子操作(atomic)以及由库函数来提供同步操作。
2、临界区
临界区通过编译指导语句对产生数据竞争的内存变量进行保护。在程序需要访问可能产生竞争的内存数据的时候,都需要插入相应的临界区代码。临界区编译指导语句的格式如下所示:
#pragma omp critical [(name)]
block
如此,在执行上述的程序块block之前,必须首先要获得临界区的控制权。在线程组执行的时候,运行时库会保证每次最多只有一个线程执行临界区。name是一个临界区的属性,给临界区一个命名。可以将不同命名的临界区保护不同的内存区域,如此就可以在访问不同内存区域的时候使用不同命名的临界区。运行时库是不会在不同命名的临界区之间进行互斥锁同步操作的。
4、原子操作
原子操作是OpenMP编程方式给同步编程带来的特殊的编程功能,通过编译指导语句的方式直接获取了现在多处理器计算机体系结构的功能。在OpenMP的程序中,这样一种先进的功能被通过#pragma omp atomic编译指导语句提供。值得注意的是,上面讲述的临界区操作能够作用在任意的代码块上,而原子操作只能作用在语言内建的基本数据结构。在C/C++语言中,原子操作的语法格式如下所示
#pragma omp atomic
x <binop>=expr
或者
#pragma omp atomic
x++//or x--, --x, ++x
5、运行时库函数的互斥锁支持
除了上述的critical与atomic编译指导语句,OpenMP还通过一系列的库函数支持更加细致的互斥锁操作,方便使用者满足特定的同步要求。
6、事件同步机制
事件同步机制与上述的锁机制不同,锁机制是为了维护一块代码或者一块内存的一致性,使得所有在其上的操作串行化;而事件同步机制则用来控制代码的执行顺序,使得某一部分代码必须在其它的代码执行完毕之后才能执行。
7、隐含的同步屏障(barrier)
在每一个并行区域都会有一个隐含的同步屏障(barrier),执行此并行区域的线程组在执行完毕本区域代码之前,都需要同步并行区域的所有线程。为了避免在循环过程中不必要的同步屏障,可以增加nowait子句到相应的编译指导语句中。
8、明确的同步屏障语句
在并行执行的时候,在有些情况下,隐含的同步屏障并不能提供有效的同步措施,程序员可以在需要的地方插入明确的同步屏障语句#pragma omp barrier。此时,在并行区域的执行过程中,所有的执行线程都会在同步屏障语句上进行同步。
#pragma omp parallel
{
initialization();
#pragma omp barrier
process();
}
9、循环并行化中的顺序语句(ordered)
在某些情况下,我们对于循环并行化中的某些处理需要规定执行的顺序,典型的情况是在一次循环的过程中,一大部分的工作是可以并行执行的,而其余的工作需要等到前面的工作全部完成之后才能够执行。在循环并行化的过程中,可以使用ordered子句使得顺序执行的语句直到前面的循环都执行完毕之后再执行。