Spark的Python编程
原文地址:http://spark.apache.org/docs/latest/programming-guide.html
Spark提供了Python脚本编程接口,这里简单介绍其使用。
相关链接:East 2015 (Nov 26, 2014) 、Archive 、Download Spark
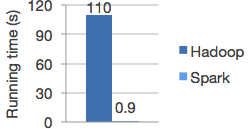
Spark比Hadoop运行程序快达100倍,在磁盘运行也快达10倍。得益于其内存计算架构和DAG任务调度机制,尽管底层同样使用的是Hadoop的HDFS分布式存储系统。
在最顶层,Spark包含一个起始程序来运行用户编写的main 方法,并且执行多样的并行操作在一个集群上。其中最主要的抽象就是Spark提供一个 RDD (弹性集群数据集),是一些可以通过节点访问执行并行任务的集群的集合。RDD 通过一个Hadoop文件系统中的文件被创建(或者其它支持Hadoop文件系统的系统)。用户经常会让Spark去保留一个RDD在内存里。允许它在并 行操作时被高效重用。最后,Rdd将自动从节点错误中恢复。
第二个被抽象是,在并行操作时,变量将被共享。默认的,当Spark 在不同节点上并行运行任务集合中的一个方法,它为任务中每个方法的变量都保留一个备份。有时候,一些变量需要被跨任务共享,或者两个任务间共享,或者给起 始程序共享。Spark提供两种形式的变量:广播变量,可以在所有节点上缓存变量在内存里。另一个是储蓄变量,只能被增加,例如数量,或者和。
本文展示这些功能,使用每个Spark支持的语言,本文是python。如果你打开 Spark的交互shell,bin/spark-shell, 或者python的shell, bin/pyspark. 很容易学的、
Spark 所使用的数据集RDDs 是一个可以被并行操作的容错数据集。有两种方式去创建它,1,并行一个你本地存在的集合。或者引用一个额外的储存系统。例如: 一个共享的文件系统,HDFS, HBase, 或者任何提供Hadoop输入格式的资源。
并行集合通过Spark 上下文 SparkContext’s parallelize 方法被创建,基于你磁盘上一个存在的可以迭代的集合。集合中的元素通过通过复制形成一个分布式数据集,这个数据集可以被并行使用。例如。下面是一个怎样创建一个并发数据集用数字1-5:
data = [1, 2, 3, 4, 5] distData = sc.parallelize(data)
一旦被创建。这个分布式数据集可以被并发使用。例如,我们可以 distData.reduce(lambda a, b: a + b) 去相加他们。我们稍后并发操作。
并发数据集的一个重要的参数是数据集被分割的子集数量。Spark 将为每个子集运行一个任务。代表性的,你想要没给CPU运行2-4个子集。正常情况下: Spark 将试图设计你分区的数量分局你的集群。但是,你依然可以通过传递第二个参数来手动设置它。 parallelize (e.g. sc.parallelize(data, 10)).
注意:你代码中一些地方会用到 slices (子集的别名),为了上下兼容性而存在的。
其它数据集合:
Pyspark 可以从任何被hadoop 支持的存储资源中 创建分布式数据集。包括本地文件系统,HDFS, Cassandra, HBase, Amazon S3 等。Sparks 支持文本文件,hadoop 输入格式文件。
文本文件 RDDs 可以通过 SparkContext’s textFile 方法创建这个方法使用一个URI 为这个文件,不管是本地路径,还是hdfs://, s3n://, URI。将它读作行的集合。下面是一个例子:
>>> distFile = sc.textFile("data.txt")
一旦被创建。文件可以通过集合操作使用。例如,我们可以相加行的数目通过使用 map 和 reduce 方法如下:
distFile.map(lambda s: len(s)).reduce(lambda a, b: a + b).
在用Spark读取文件时候的一些注意项:
如果使用一个本地文件系统,这个文件的权限必须被开放。可以被复制或者被共享。
所 有的Spark 文件输入方法,包括 textFile, 也支持运行目录,压缩文件,和通配符。例如,你可以使用 textFile("/my/directory") ,textFile("/my/directory/*.txt") 和 textFile("/my/directory/*.gz");
textFile 方法同样使用第二个参数去控制文件被分割的子集。默认,Spark为这个文件的每个Block (在 HDFS中是64M )创建一个子集,但是你可以通过传递一个参数来设定更高的值。注意,这个值不能比默认 blocks分割的 更小。
除了 textFile , Spark 的Python API 提供了其它的数据格式:
SparkContext.wholeTextFiles让你读一个包含很多小文件的目录。然后返回以键值对的方式返回它们(文件名,内容)。这个方法相对 textFile ,后者返回文件的每一行。RDD.saveAsPickleFileandSparkContext.pickleFile支持以简单python对象格式存储一个RDD 。SequenceFile and Hadoop Input/Output Formats
注意,这个功能目前在实验阶段。用于高级用户。它或许被替代在将来。新的方式将采用基于 Saprk SQL 读写。那时候,Spark SQL 将是最优先的方式。
写支持:
PySpark SequenceFile 支持加载一个java 键值组成的RDD ,根据java 类型转换成可写的。当保存一个键值对组成的RDD 到 SequenceFile中, PySpark 进行这个转换。它把Python对象转成 Java对象,然后把它们转变成可写的。下面这些类型自动转换:
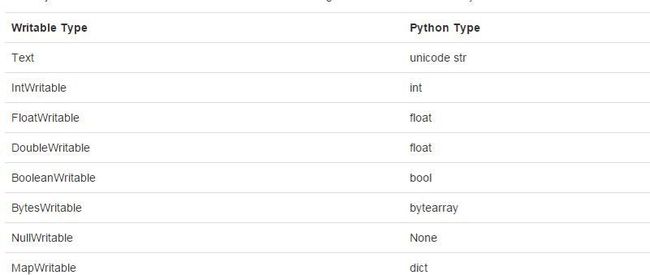
数组不被处理,用户需要去指定自定义的 ArrayWritable 子类型 当读写的时候。在写的时候,用户还需要指定自定义的转换把 数组转换成 自动以的 ArrayWritalbe 子类型。在读的时候,默认的转换将自定义的ArrayWritable 子类型转成Java 对象。然后转成Python元组。
保存和加载 SequenceFiles
和文本文件类似。SequenceFiles 通过指定路径被保存和加载。key 和 value 可以被分开。但是对于标准写来讲,不需要如此。
>>> rdd = sc.parallelize(range(1, 4)).map(lambda x: (x, "a" * x ))
>>> rdd.saveAsSequenceFile("path/to/file")
>>> sorted(sc.sequenceFile("path/to/file").collect())
[(1, u'a'), (2, u'aa'), (3, u'aaa')]
Rdd 操作:
Rdd 支持两种形式的操作,1转换,根据现有的数据集创建一个新的。2动作,在数据集上运行一些计算后返回值。例如,map 是一个转换,通过一个方法将数据集的每个元素返回到一个rdd结果中,另一边,reduce 是一个动作,通过方法将RDDd的元素合并成一个最终结果(reduceByKey 返回一个分布式数据集)。
Spark 中所有的转换都是懒执行的。所以它们并不马上计算它们的结果。代替的,它们记着这些用于基础数据集的转换,当一个动作要求一个结果被返回来,那么才执行这 些计算。这个设计可以使Spark 运行更高效。例如。我们可以实现一个通过map创建的数据集被reduce 使用然后返回一个reduce结果,而不是一个大的map过的集合。
默认,每一个被转换的RDD或许被重新计算当你每次对它使用action时。但是,你可以缓存 一个RDD在内存里,通过使用 persist或者cache,方法。此时,Spark将保存这个元素在集群上,为了你下次更快使用它。也支持缓存rdds 在磁盘上。或者复制在多节点上。
lines = sc.textFile("data.txt")
lineLengths = lines.map(lambda s: len(s))
totalLength = lineLengths.reduce(lambda a, b: a + b)
第一行根据一个外部文件定义了一个基础rdd。数据集不被加载到内存,除非被动作执行。 lines 仅仅是一个文件的指针,第二行定义一个 lineLength 作为一个map 的转换结果。同样的,lineLength 不是立即被计算。因为懒执行。最后,我么可以reduce, 它是一个动作。 此时,Spark 分割计算成很多任务。在各个机器上运行,每个机器运行它自己部分的map和一个reduce 的结果。仅仅返回这个结果到起始程序中。
如果我们之后需要多次使用lineLength,我们可以缓存它:
lineLengths.persist()
在reduce 之前,lineLengths 将再第一次被计算出来后缓存到内存。
传递方法给Spark:
Spark 的API 特别支持传递方法给起始程序,然后在集群上运行。有三种推荐方式:
Lambda表达式, 对于简单的方法可以写成表达式,Lambda不支持多行方法 或者不返回值的方法。
对于长一点的代码。在方法内部定义。
作为一个模块。
例如,传递一个长一点的方法而不是使用lomba。看下面代码:
"""MyScript.py"""
if __name__ == "__main__":
def myFunc(s):
words = s.split(" ")
return len(words)
sc = SparkContext(...)
sc.textFile("file.txt").map(myFunc)
注意,当一个对象实例方法 允许传入引用时(和单例对象相反)。需要传递这个class和方法一起:例如:
class MyClass(object): def func(self, s): return s def doStuff(self, rdd): return rdd.map(self.func)
创建了一个新的 MyClass, 然后调用 doStuff。内部的map 引用这个MyClass 实例的 func ,所以整个对象需要被传递到 集群。
类似的,外部对象的可访问领域,将引用真个对象。
class MyClass(object): def __init__(self): self.field = "Hello" def doStuff(self, rdd): return rdd.map(lambda s: self.field + x)
为了防止出错,最简单的方式是复制 field 到一个本地变量代替访问它:
def doStuff(self, rdd): field = self.field return rdd.map(lambda s: field + x)