1. 基本配置(与Hadoop共通)
1.1 安装JDK
安装JDK6或以上版本,配置JAVA_HOME 、CLASSPATH环境变量。具体过程略。
1.2. 安装python
先确定系统自带的Python版本,如果是2.6.6或者以上的不需要安装
1.3. 配置hosts
关闭防火墙,添加集群中主机和IP的映射关系
$cat /etc/hosts
127.0.0.1 localhost 192.168.0.99 backup 192.168.0.100 master 192.168.0.101 datanode1 192.168.0.102 datanode2 192.168.0.103 datanode3 192.168.0.104 datanode4
2. Zookeeper安装
2.1. 下载后解压安装Zookeeper包
本集群用的是zookeeper-3.4.6.tar.gz 发行版本(见附件)。
2.2. 修改conf/zoo.cfg配置文件:
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/home/hadoop/storm_tmp/zookeeper/data dataLogDir=/home/hadoop/storm_tmp/zookeeper/log clientPort=2181 server.1=master:2888:3888 server.2=backup:2888:3888 server.3=datanode1:2888:3888 server.4=datanode2:2888:3888
其中,dataDir指定Zookeeper的数据文件目录;其中server.id=host:port:port,id是为每个Zookeeper节点的编号,保存在dataDir目录下的myid文件中,zookeeper1~zookeeper3表示各个Zookeeper节点的hostname,第一个port是用于连接leader的端口,第二个port是用于leader选举的端口。
在 ${dataDir} 目录下创建myid文件,文件中只包含一行,且内容为该节点对应的server.id中的id编号。
2.3. 启动Zookeeper:
bin/zkServer.sh start
2.4. 通过Zookeeper客户端测试服务是否可用:
bin/zkCli.sh -server IP:2181
3. Storm安装
Storm提供了两种形式的压缩包:zip和tar.gz, 本集群中使用apache-storm-0.9.5. (见附件)
3.1. 解压Storm
Storm发行版本解压后目录下有一个conf/storm.yaml文件,用于配置Storm。以下配置选项是必须在conf/storm.yaml中进行配置的,需要特别注意:每个参数前面以及 “-”后面要带空格。
1) storm.zookeeper.servers -- Storm集群使用的Zookeeper集群地址,其格式如下:
storm.zookeeper.servers:
- "192.168.0.100"
- "192.168.0.99"
- "192.168.0.101"
- "192.168.0.102"
如果Zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项。
2) storm.local.dir -- Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限:
storm.local.dir: "/home/hadoop/storm_tmp/"
3) nimbus.host -- Storm集群Nimbus机器地址,各个Supervisor工作节点需要知道哪个机器是Nimbus,以便下载Topologies的jars、confs等文件:
nimbus.host: "192.168.0.100"
4) supervisor.slots.ports -- 对于每个Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选项即用于定义哪些端口是可被worker使用的。默认情况下,每个节点上可运行4个workers,分别在6700、6701、6702和6703端口,如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
3.2 启动Storm各个后台进程
主控节点Nimbus进程:
1. 运行Zookeeper:./zkServer.sh start
2. 在Storm主控节点上运行”bin/storm nimbus >/dev/null 2>&1 &”启动Nimbus后台程序,并放到后台执行;
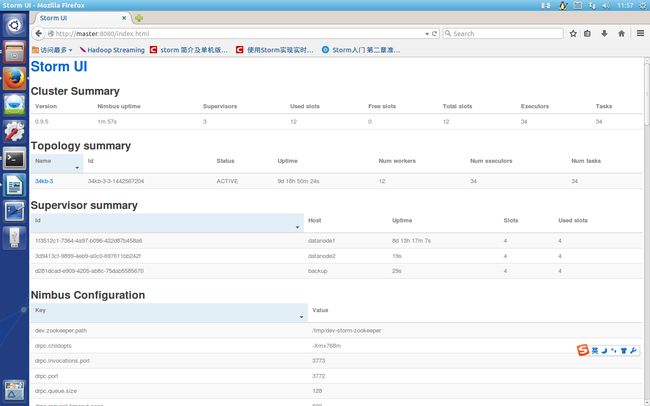
3. 在Storm主控节点上运行”bin/storm ui >/dev/null 2>&1 &”启动UI后台程序,并放到后台执行,启动后可以通过http://{nimbushost}:8080观察集群的worker资源使用情况、Topologies的运行状态等信息。Storm UI必须和Storm Nimbus部署在同一台机器上,否则UI无法正常工作,因为UI进程会检查本机是否存在Nimbus链接。
4. logview:在Storm主节点上运行"bin/storm logviewer > /dev/null 2>&1 &"启动logviewer后台程序,并放到后台执行。
工作节点进程:
1. 运行Zookeeper:./zkServer.sh start
2. 在Storm各个工作节点上运行”bin/storm supervisor>/dev/null 2>&1 &”启动Supervisor后台程序,并放到后台执行;
4. 注意事项:
为了方便使用,可以将bin/storm加入到系统环境变量中。
$cat /etc/profile
#for JAVA
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_05
export JRE_HOME=${JAVA_HOME}/jre
#for Storm
export ZOOKEEPER_HOME=/home/hadoop/Storm/zookeeper-3.4.6
export STORM_HOME=/home/hadoop/Storm/apache-storm-0.9.5
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:${ZOOKEEPER_HOME}/lib:${STORM_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:${JRE_HOME}/bin:${ZOOKEEPER_HOME}/bin:${STORM_HOME}/bin:$PATH
至此,Storm集群已经部署、配置完毕,可以向集群提交拓扑运行了。接下来我们检查下环境的运行情况:--使用jps检查守护进程运行状况
$ jps
20420 nimbus (主节点)
20623 logviewer (主节点)
20486 supervisor (工作节点)
20319 core (主节点)
21755 Jps