Stereo Matching文献笔记之(三):《Segment-Tree based Cost Aggregation for Stereo Matching》读后感~
前段时间整理博客发现,自己关于立体匹配部分的介绍太少了,这可是自己花了一个季度研究的东西啊!读了自认为大量的文章,基本上有源码的都自己跑了一遍,还改进了多个算法。不写写会留下遗憾的,所以打算在立体匹配这一块多谢谢博客,一来用于分享,二来用于请教,三来用于备忘。本文介绍的文章就是CVPR2013的《Segment-Tree based Cost Aggregation for Stereo Matching》一文,介绍它原因有以下几点:
1.它是NLCA的变种。
2.它是CVPR的文章。
本文还是从Segment-Tree的算法思想,算法核心,算法效果三方面进行分析,这篇文章的源代码链接是:https://github.com/kc4271/STCostAggregation
(转载请注明:http://blog.csdn.net/wsj998689aa/article/details/48033819, 作者:迷雾forest)
1. 算法思想
Stereo Match是前段时间一直研究的问题,我将主要的精力都集中在了半全局算法上,或者带有全局性质的局部算法,如上一篇博客介绍的NLCA(non-local cost aggregation),本文介绍一下NLCA的衍生品,这样说没有冒犯作者的意思哈!但是ST(segment tree)确实是基于NLCA的改进版本,本文的算法思想是:基于图像分割,采用核NLCA同样的方法对每个分割求取子树,然后根据贪心算法,将各个分割对应的子树进行合并,算法核心是其复杂的合并流程。
但是这个分割不是简单的图像分割,其还是利用了最小生成树(MST)的思想,对图像进行处理,在分割完毕的同时,每个分割的MST树结构也就出来了。然后将每个子树视为一个个节点,在节点的基础上继续做一个MST,因此作者号称ST是分层MST,还是比较贴切的!
算法是基于NLCA的,那么ST和NLCA比较起来好在哪里?作者给出的解释是,NLCA只在一张图上面做一个MST,并且edge的权重只是简单的灰度差的衍生值,这点不够科学,比如说,当遇到纹理丰富的区域时,这种区域会导致MST的构造出现错误,其实想想看的确是这样,如果MST构造的不好,自然会导致视差值估计不准确。而ST考虑了一个分层的MST,有点“由粗到精”的意思在里面。有图说明:

a指的是原图,b指的是局部放大图,c指的是ST的权重图,d指的是NLCA的权重图,这个权重图指的是,
周围点对红色点的贡献度,越亮代表权重越大。可以明显看到,在对细节的处理上,ST明显强于NLCA,例如ST中p1点,其位于低纹理区域,对高纹理区域的贡献很低很低,这更符合理想状态。但是MST却有瑕疵,p1点对其它点的贡献不具有区域性,绿色三角指向的地方就是瑕疵所在。
产生上述现象的原因是:ST在生成整幅图MST的同时,事实上也对各个区域生成了MST,便使得单点对其它点的权值,在所位于区域内比较大, 而在不同的区域上往往很小。至于ST是如何做到的,请看下一小节中的解释。
2. 算法核心
本文的核心部分就是其中的流程图,最让人费解的也是这个算法流程,所以本小节重点说一下我对这块的理解。它将流程分为三个部分,初始化->聚合->连接

其实,该算法流行直接采用了文献《Efficient graph based image segmentation》中提到的全局分割方法,文献在这里并没有进行过多的解释,只是一再强调可以去文献中查阅这篇文章。下面说一下各个步骤的含义。
1. 初始化很简单,边先暂且不考虑,将每个像素点形成一个集合T,集合内只有一个像素点。
2. 聚合比较复杂,需要将边根据权值由小到大排序,然后对所有的边进行遍历,与边相伴随的两个点要么合并,要么不合并,判断的准则就是边权值是否满足下述条件:
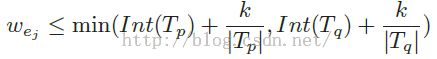
如果合并,那么就要将边不断的添加到集合E‘中,最终,E’中存放的都是小树中的边,由于后续还需将每个小树视作一个个节点,重新将小树连接成为一棵大树,所以需要将E‘从E中删除。
3.剩下的就是连接,正如上面所说,连接就是将每个小树视作节点,进一步形成一颗大树。采用的方法和上面的步骤很相似,对E中的边进行遍历,这个时候没有条件的限制,如果两个小树不同就得合并,直至E’中边的个数只比点的个数少1,
因为树的边数就比节点数少1个,所以这里意味着全图对应的还是只有一颗MST,注意,这个E‘没有重新被清空。
流程就是上面说的这样,下面提几个问题:
1)流程图中合并的集合一直都是Vp,Vq,那么Vp,q是怎么处理的?
2)为什么聚合之后,就相当于对图像进行了分割?
3)终止条件有什么意义在里面?
4)边权值满足的阈值有什么意义?
以下部分是我的回答:
1). 要回答这个问题,我们不妨思考一下MST的创建过程,你就会发现,原来这个流程图和MST的区别只有一处,那就是
“选择edge的时候,多了一个判断条件”,其余的真的是一模一样,作者故意将流程图分为三部分,使其看的复杂,其实完全可以说
“我们的算法流程就是普通的基于克鲁斯卡尔创建MST + edge判断条件”,这很滑稽,也是各国论文中无处不在的猫腻。回到正题,Vp,q变成了一个连通,仅此而已,在代码上只要写parent(Vp) = parent(Vq)即可。说白了,作者忘了多提一句Vp = Vp,q
2). MST创建的时候,只要发现一个edge两个端点所属的连通不一样,就要将两个连通合并为一个连通,这里面的连通就可以理解为这里的子树,而ST会考虑edge两个端点所在连通的区别大小,区别不大就合并,区别大就不合并,你懂了吧?这样就会将图像自然的分成一个个区域,因为你有的区域不合并嘛!
但是,说句心里话,我觉得作者虽然一直强调ST有这么优秀的性质,但是并没有给出严格意义上的证明啥的,只是根据直觉,这有点不靠谱,至少我在做视差图的时候,发现视差图并没有体现出
区域分割的优势。所以我觉得在此处有过度包装的嫌疑。
3). 终止条件中的Int(Tp)其实是一种
区域内间距的定义,而k/|Tp|就是一种调节因子。这直接借鉴了图像分割中一类方法(基于图表示的图像分割),它定义了
区域间间距和
区域内间距两种距离度量,如果区域间间距大于区域内间距,那么两个区域就不能合并,反之就可以合并,公式中的边权值w,由于是从小到大排列的,刚好就是区域间间距的意思。
(关于基于图表示的图像分割方面的内容,网上博客也有很多,,大家可以去科普一下这方面的知识。我就找到了《Efficient Graph-Based Image Segmentation论文思路》一文,介绍的就不错。)
4). 如果是不同的图像区域,MST的做法对区域没有任何辨识能力,有的区域之间差距很明显,有的区域之间差距不明显,但是MST一视同仁,而ST却不是,它提出了一个判断条件,满足这个条件的不同区域,我可以合并,不满足就不合并!阈值就是干这个的。
3. 算法效果
论文中给出了算法的视差图对比,当然对比的对象就是NLCA,以及双边滤波方向的方法Guided Filter,从标准数据集上看,其实ST和NLCA真的差距不是很大,并且标准数据集上的比较并没有很强的实际意义,往往在middlebery上好的评测算法,在实际应用场景上,效果就是个渣渣。。。但是ST是一种代价聚合方法,很多全局算法之所以求得精确,就在于它们在视差求精阶段做足了文章,其实它们的代价聚合步骤得到的视差往往不咋地,那么完全可以基于ST进行视差求精,这才是ST最大的意义啊!
4. 副产品
ST有个副产品,就是图像分割,虽然作者没有明确地强调这块内容,只是将其视作视差图的求精部分, 但是分割的效果其实真心不错,如图所示:
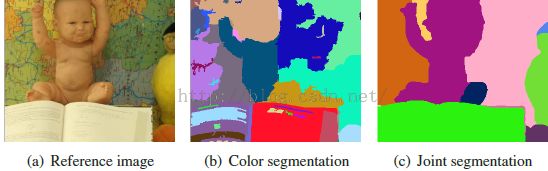
大家看看效果还可以吧?至于作者怎么做到的,过程真的很简单,作者只是基于深度图和原图重新构造了像素点之间的距离(或权重),然后重新走了一遍分割树流程,再将图像根据连通区域标定标签,就得到了第三幅图像的分割效果,中间那副图像是只考虑原图的分割树分割效果图,很挫。引入的新公式如下所示:
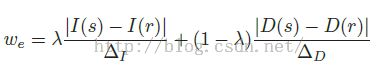
作者在文献中对这块的说明一笔带过,根据提供的源码,色彩之间的距离其实是RBG三个通道差值的最大值,并且只在稳定点上进行计算(关于稳定点,请参考其他几篇博客),折中参数设定的是0.5,这和文献中的0.4不大一致,不知道是出于何种原因。我在自己的数据集上也测试了这部分的分割效果,真的还不错,看来也算是一种实用的图像分割算法了(一定是基于双目相机),虽然作者只是想用其进行视差求精。
5. 结论
之所以研究ST,主要还是因为它是NLCA的扩展,是一种非传统的全局算法,与NLCA唯一的区别就在于ST在创建MST的时候,引入了一个判断条件,使其可以考虑到图像的区域信息。这点很新颖,说明作者阅读了大量的文章,并且组合能力惊人,组合了MST和基于图表示的图像分割方法。它的运行时间虽然比NLCA要大一些,但是相比较全局算法,速度已经很可以了。
但是ST也有一些缺陷,首先,算法对图像区域信息的考虑并不是很严谨,对整幅图像用一个相同的判断条件进行分割,分割效果不会好到哪里去,并且基于实际数据实测,会发现视差图总是出现“白洞”,说明该处的视差值取最大,这也是区域信息引入的不好导致的。虽然在细节上略胜于NLCA,但是算法耗时也有所增加。上述原因也是本文引用率不佳的原因。