Web常见编码及变换类型识别 (Python编程实现)
设计初衷:
在分析网络数据包或者研究安全问题时,经常会遇到变换后的字符序列。而能否准确识别密文的变换算法,对进一步的分析工作很关键。常用的变换算法包括但不限于:Base64、URL编码、HTML编码、MD5散列、SHA-1等。该程序当前支持这5种变换标准算法的自动识别:Base64、URL编码、HTML编码、MD5散列、SHA-1。
源码在第三部分。
一、程序运行展示:

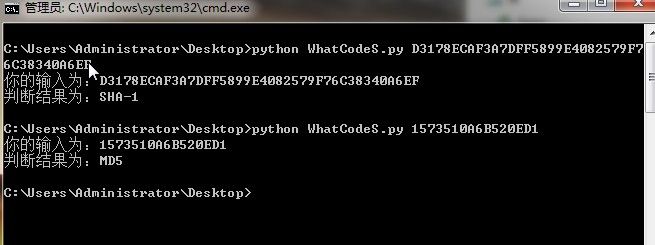
二、算法特点及识别原理讲解
算法特点整理(我尽力注意准确和精简):
这里统称变换后的字符序列为"密文",虽然在学术上不太恰当。”位“有时候指的是1bit(1比特,一个字节也就是1Byte,相当于8bit),有时候‘位’指的是一个字符。
1、MD5
算法简介:单项散列算法(中文名为消息摘要算法第五版)。将输入的数据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5的前身有MD2、MD3和MD4。
典型特点:标准的MD5算法对输入的数据,计算的结果是128位二进制,只有转为16进制字符串是32个字符(每4位二进制转换成1个16进制字符)。 字母的大小写没有意义上的区别。然后16个字符的MD5值,实际上是32个字符的MD5值取中间16个字符。
识别判断依据:完整的散列值长度为32个字符或者16个字符,由于每一个字符都是16进制,所以取值范围只能是'0'~'f',注意字母可能会有大小写。
2、SHA-1
算法简介:SHA (Secure Hash Algorithm,译作安全散列算法) 是美国国家安全局 (NSA) 设计,美国国家标准与技术研究院(NIST) 发布的一系列密码散列函数。正式名称为 SHA 的家族第一个成员发布于 1993年。然而人们给它取了一个非正式的名称 SHA-0 以避免与它的后继者混淆。两年之后, SHA-1,第一个 SHA 的后继者发布了。 另外还有四种变体,曾经发布以提升输出的范围和变更一些细微设计: SHA-224, SHA-256, SHA-384 和 SHA-512 (这些有时候也被称做 SHA-2)。SHA-1、SHA-256、SHA-384、SHA-512几种,分别产生160位、256位、384位和512位的散列值。
典型特点:输出的哈希值长度为 160 位(这里说明一下:160位是二进制。对于sha1来说是160位的,也就是20个字节,但打印的是40个字符,因为每4位二进制转换成1个16进制字符,所以最后打印的是40个字符)
识别判断依据:完整的散列值长度为40个字符。由于每一个字符都是16进制,所以取值范围只能是'0'~'f',注意字母可能会有大小写。
3、标准base64变换(很多编程语言已经有base64编解码的函数,可直接调用)
算法简介:按照RFC2045的定义,Base64被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。(The Base64 Content-Transfer-Encoding is designed to represent arbitrary sequences of octets in a form that need not be humanly readable.)
典型特点:变换后的字符数为4的倍数。标准base64的编码后字符集为“ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=”,且‘=’只会出现在结尾,但是一定情况下,变换后序列是不会出现‘=’的。
识别判断依据:完整的base64变换后的序列,要看字符数目是否为4的倍数,然后结尾可能是=,然后每个字符只能base64是字符集中的一员。
4、URL编码(注意:URL编码对于ASCII字符,有一个统一的映射表,但是比如中文这种字符,最常用有utf-8、gb2312两种编码,编解码是采用哪种,视情况而定,很多编程语言已经有URL编解码的函数,可直接调用)
算法简介:对URL进行编码,是为了避免URL解析发生歧义,简化解码方式,如:URL采用“&”作为不同参数的分隔符,假如某个特定的参数的名称或者值本身就包括分隔符“&”,如果不将参数中的“&”做编码转换,那势必会增加URL解析的复杂性,提高解析错误的概率。由于URL是采用ASCII字符集进行编码的,所以如果URL中含有非ASCII字符集中的字符,那就需要对其进行编码。再者,由于URL中好多字符是保留字,他们在URL中具有特殊的含义。如“&”表示参数分隔符,如果想要在URL中使用这些保留字,那就得对他们进行编码。
典型特点:根据2005年发布的RFC3986“%编码”规范:对URL中属于ASCII字符集的非保留字不做编码;对URL中的保留字需要取其ASCII内码,然后加上“%”前缀将该字符进行替换(编码);对于URL中的非ASCII字符需要取其Unicode内码,然后加上“%”前缀将该字符进行替换(编码)。由于这种编码是采用“%”加上字符内码的方式,所以,有些地方也称其为“百分号编码”。
虽然“百分号编码”对URL的编码方式做了详细的规定,但是实践中,浏览器对于URL的编码方式还是存在一些差异(主要表现在对非ASCII字符编码的差异)
识别判断依据:百分号编码,每个%后有2个字符,其实是把一个字节(8bit二进制,每4bit二进制装换为一个十六进制字符),所以,每个字符只能取 0 ~ F(字母大小写都可以,没有意义上的区别。)
5、HTML编码
算法简介:这里指的不是HTML网页编程,其实指的是一种HtmlEncode的概念。比如为了对抗XSS漏洞,对一些敏感字符进行编码,XSS之所以会发生, 是因为攻击者精心构造的输入数据被系统过滤不严,导致变成了执行代码。 所以我们需要对用户输入的数据进行HTML Encode处理。 将其中的"<", “>”,“&” 之类的特殊字符进行编码。具体对那些字符进行映射转换,不同编程语言自带的函数,针对的字符都有些区别。其实自己也可以写一个自定义的转换函数,比如只转换"<", “>”,“&”这3个,对应下表中的前三行。
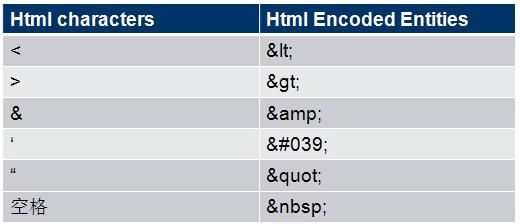
典型特点:由于对 HTML encode处理有多种实现方式,其实区别就在于“对那些敏感字符进行转换”。但是"<", “>”,“&”是各种实现方式中基本上都转换了的,所以,我们就只考虑识别'<' '>' '&'就ok啦。
识别判断依据:这次,就只考虑"<", “>”,“&”转换成'<' '>' '&'。其实html encode的转换后,有一个特点,就是 '&' 开始,';'结束,根据这个特点,写个正则识别得会更全。
三、Python源码
基于Python2.7.6 编写,windows 7 64位下运行正常。
#! /usr/bin/env python
#coding=utf-8
#识别字符序列变换算法,当前支持标准的MD5、SHA-1、Base64,及主流的URL编码、HTML编码
import re
import sys
#MD5判断函数
def checkMD5(inStr):
MD5KeyStrs = '0123456789abcdefABCDEF'
inStr = inStr.strip() #判断MD5的时候把输入两端的空格切掉
if (len(inStr) != 16) and (len(inStr) != 32):
return False
else:
for eachChar in inStr:
if eachChar not in MD5KeyStrs:
return False
return True
#SHA1判断函数
def checkSHA1(inStr):
SHA1KeyStrs = '0123456789abcdefABCDEF'
inStr = inStr.strip() #判断SHA-1的时候把输入两端的空格切掉
if len(inStr) != 40:
return False
else:
for eachChar in inStr:
if eachChar not in SHA1KeyStrs:
return False
return True
#Base64判断函数
def checkBase64(inStr):
Base64KeyStrs = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='
inStr = inStr.strip() #判断Base64的时候把输入两端的空格切掉
if len(inStr) % 4 != 0:
return False
else:
for eachChar in inStr:
if eachChar not in Base64KeyStrs:
return False
return True
#URL编码判断函数
def checkURLCode(inStr):
reURLCode = '%[0-9a-fA-F][0-9a-fA-F]' #正则表达式
reResultList = re.findall(reURLCode,inStr)
if len(reResultList) == 0:
return False
else:
return True
#HTML编码判断函数
def checkHTMLCode(inStr):
htmlEncodeTuple = ('<','>','&',''','"',' ',''','/')
for each in htmlEncodeTuple:
if each in inStr:
return True
return False
#总的调度函数,负责调用各个算法的判断函数
def checkInput(inStr):
if checkMD5(inStr):
resStr = 'MD5'
return resStr
if checkSHA1(inStr):
resStr = 'SHA-1'
return resStr
if checkBase64(inStr):
resStr = 'Base64'
return resStr
if checkURLCode(inStr): # 考虑到 URL编码 与 HTML编码可能会同时出现
resStr = 'URLCode'
if checkHTMLCode(inStr):
resStr = 'URLCode + HTMLCode'
return resStr
else:
return resStr
if checkHTMLCode(inStr):
resStr = 'HTMLCode'
return resStr
resStr = 'UnKnown'
return resStr
#Python主程序
if __name__ == '__main__':
if len(sys.argv) > 1: #接受命令行输入
inputStr = str(sys.argv[1])
resultStr = checkInput(inputStr)
print u'你的输入为:'.encode('gb2312') + inputStr
print u'判断结果为:'.encode('gb2312') + resultStr
else: #交互界面
print '---------------------------------------------------------------------'
print u'--------- 识别密文变换算法 WhatCodeS V1.0 ----------'.encode('gb2312')
print u'--- 当前支持识别MD5、SHA-1、Base64、URL编码、HTML编码 -----'.encode('gb2312')
print u'-- 支持交互操作与命令行操作(命令行不支持直接输入特殊字符) --'.encode('gb2312')
print '---------------------------------------------------------------------'
print
while(True):
inputStr = raw_input(u'请输入字符序列(输入‘q’退出程序):'.encode('gb2312'))
if inputStr == 'q':
break
elif inputStr == '':
continue
else:
resultStr = checkInput(inputStr)
print u'你的输入为:'.encode('gb2312') + inputStr
print u'判断结果为:'.encode('gb2312') + resultStr
print