HDFS和KFS 比较
HDFS和KFS 比较
By云深作者:Terry/Lanlan/Adam 2009年1月
转载请注明出处
1、HDFS 和 KFS 简介
两者都是GFS的开源实现,而HDFS 是Hadoop 的子项目,用Java实现,为Hadoop上层应用提供高吞吐量的可扩展的大文件存储服务。
Kosmos filesystem(KFS) is a high performance distributed filesystem for web-scale applications such as, storing log data, Map/Reduce data etc. It builds upon ideas from Google‘s well known Google Filesystem project. 用C++实现
本文选取的源码版本如下:
hadoop-0.17.2.1
Kfs 0.2.2
2、HDFS和KFS体系架构
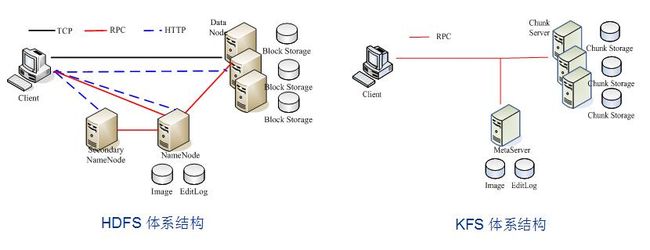
图1 体系架构
HDFS和KFS都属于分布式文件系统,它们的元数据管理采用集中式方式实现,数据实体先分片然后分布式存储。本文先介绍这类系统的模块组成以及各模块的关键技术,并以此为线索分析和比较HDFS的异同点。
HDFS和KFS大致有以下几个模块组成:
MetaServer:
Namespace 管理
Layout管理
MetaImage管理
Lease管理
ChunkServer:
Chunk管理
Chunk存储
Client Transaction Layer,该部分是系统给上层应用提供的接口,本文不予比较。
3、HDFS和KFS各模块的关键技术
HDFS和KFS关键实现技术如下:
MetaServer:
Namespace的组织和维护
MetaData的序列化和加载
系统恢复
Chunk Layout的ChunkServer选择
Lease的管理和维护
ChunkServer:
Chunk存储组织
本地Chunk 信息的重建
Chunk失效处理
Client Transaction:文件操作
4、HDFS和KFS MetaServer实现的比较(1)
Namespace的组织和维护
HDFS Namespace的组织采用Component模式,文件夹、文件和Chunk组成如下层次结构。
Root /------|
|-----/terry---|---/sub0
|----file3---|---block0
|---block1
|-----/adam--|---/sub0
|-------file0
| --block2
|-------tmpfile1
|---block3
|---block4
KFS采用B+树存放文件系统的结点信息,各结点存有父结点的索引,从而实现文件夹、文件和Chunk的层次关系。
5、HDFS和KFS MetaServer实现的比较(2)
LayoutManagement实现,包括Chunk Server选择算法、负载均衡实现。
Chunk Server选择算法包括以下:
Chunk 创建时,Chunk Server的选择;
Chunk 实际拷贝数与需求不一致时,Chunk的重拷贝和删除问题。
写入的ChunkServer具备的基本条件如下:
节点处于活跃期;
节点有Chunk读(拷贝源节点)或写(拷贝目标节点)并发的余量;
节点网络流量小于系统平均流量的两倍;
作为存储点,节点有存储余量;
Chunk在该节点所属Rack上的拷贝数没到上限;
基本原则:HDFS优先保证前3份拷贝有两份在一个Rack上,另一份在不同的Rack上;而KFS要求拷贝均匀分散在不同的Rack上。
Chunk创建时,第一个存储点的选择问题:
当创建Chunk的Client上部署有Chunk Server时,HDFS和KFS均优先选择该节点为首存储点;
否则,HDFS随机选择,KFS优先选择存储和网络负载较轻的节点。
根据上述基本原则选择其余节点。
拷贝数小于需求时,HDFS根据基本原则选择备用节点;KFS优先选择失效节点相同Rack上的节点;
拷贝数大于需求时,HDFS根据基本原则删除多余的Location;KFS优先考虑拷贝的均匀分布,然后再根据节点的负载选择失效拷贝。
6、HDFS和KFS MetaServer实现的比较(3)
MetaServer根据Namespace中的chunk列表,将列表乱序,依此扫描chunk location信息,将存储或网络负载超过阈值的节点上的拷贝标志为失效,并转存到负载较低的节点上。
负载控制方面:HDFS任务分配较KFS精细;HDFS实现上有网络流量控制,KFS没有。
实现方式上:HDFS使用多线程实现多任务并发执行,而KFS使用Reactor模式实现多任务并发。
7、HDFS和KFS MetaServer实现的比较(4)
Meta Image Management,包括FSImage和操作日志两部分。
HDFS FSImage结构如图2(新版本中删除了DataNode Image部分)。
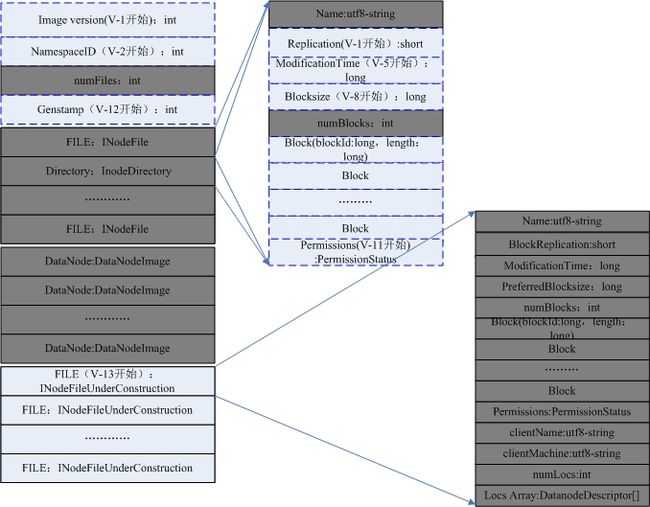
图2 HDFS FSImage
KFS存储元数据B+树的叶子节点信息到磁盘上,并记录该镜像加载过程中需要合并的操作日志文件名。
HDFS通过多目录的同时备份,并记录checkpoint时间。系统重启时,通过检查各目录下镜像信息以及中间文件存在状态,采取合理的策略恢复元数据信息,并生成新的元数据镜像。
KFS在本地存有不同版本的镜像和操作日志,并通过一个硬链接指向最新的镜像信息。启动时,加载硬链接指向的镜像文件,以及镜像中存有的操作日志及其之后的所有的操作日志,恢复元数据。
8、HDFS和KFS MetaServer实现的比较(5)
Lease的管理和维护-1
HDFS和KFS的锁管理通过Lease方式来实现,并且都在Chunk级别加锁。
HDFS仅对正在创建中文件拥有的Chunk加锁,即只有写锁。并且文件删除过程中,直接清除该文件上所有的锁,使Lease renew操作失败,中断用户的写操作。
KFS实现了读和写两种锁机制,可以多用户并发读,单用户独占写,读写互斥。已加锁的文件删除时,将文件移动到Namespace的dumpster目录,待有锁清除操作时,检查相关文件的锁信息,将无锁的文件彻底删除。
HDFS实现的是实名锁,记录了客户端信息;KFS采用的是匿名锁,仅记录了分配的Lease ID。
Lease的管理和维护-2
HDFS中ChunkServer没有锁标志,MetaServer将写锁分配给Client,由Client刷新;
KFS的实现相对复杂些。
写操作,MetaServer分配Chunk时,给Main ChunkServer分配writer-Lease,ChunkServer接收到Client的写操作时检查并Renew该Lease;
读操作,MetaServer给Client分配Reader-Lease,由Client根据读的进度进行Lease的Renew操作;
Lease的销毁有两种方式:
定时器
特定的操作关联删除
锁机制实现上,KFS相对完善些,但其匿名锁方式也可能存在隐患。
9、HDFS和KFS ChunkServer实现的比较(1)
ChunkServer上Chunk的存储组织:
l HDFS和KFS都可以配置多个存储目录;
l 在存储目录存储空间配额允许的情况下,HDFS按照轮转的方式将Chunk均匀的放置到各存储目录;KFS按照ChunkId和存储目录个数的模运算选择存放目录。
l ChunkId由MetaServer统一分配,HDFS的放置方式较KFS均匀,chunk维护的过程中,要维护chunk到文件的映射。KFS的放置策略简单,Chunk和文件之间的映射关系直接,但弊端也十分明显,配置文件中的存储目录数目不能修改,否则系统将无法正常运作。KFS0.2.2中似乎并没有解决这个问题。
l 在同一个存储目录中,HDFS每级目录最多64个Chunk和64个子目录,组成层次结构。存放时Chunk时,要求嵌套目录的深度尽量小。KFS采用平面结构,所有Chunk存放在一个目录下。根据底层文件系统实现机制,HDFS Chunk文件的定位速度较KFS快。
l HDFS各工作目录有文件锁,避免多网元共享存储目录引发错误;KFS没有该保护机制。
10、HDFS和KFS ChunkServer实现的比较(2)
ChunkServer上Chunk存储:
l HDFS中,每个Chunk存放两个文件,实体数据和Meta数据;KFS存放为一份文件,Meta数据存放在前16K文件头区域,实体数据存放在16k之后。
l HDFS和KFS默认的Chunk大小为64M。Meta校验码部分均采用Adler_32算法。 HDFS根据配置,决定是否计算校验码,以及校验块的大小。 KFS每16K数据计算一个32位校验码,存放在对应的Meta数据区域。
l KFS有16K的文件头,在实现Truncate操作时,KFS0.2.2版本中似乎忽略了这部分数据,Bug or not?
11、HDFS和KFS ChunkServer实现的比较(3)
本地Chunk 信息的重建:
l HDFS和KFS均通过扫描本地工作目录,重建内存中的Chunk管理数据;
l HDFS在ChunkServer中没有Chunk镜像和操作日志记录;KFS中有这部分实现,在ChunkServer上存储Chunk镜像信息和操作日志,并实现了启动时对镜像和操作日志的加载功能。但是这部分代码没有调用,也许废弃了。
12、HDFS和KFS ChunkServer实现的比较(4)
Chunk失效处理
l HDFS:ChunkServer通过定期的Heartbeat向MetaServer汇报本地Chunk列表,或者完成Chunk写操作后,向MetaServer汇报新写入的Chunk信息。MetaServer根据状态,向ChunkServer分发Chunk复制任务或者Chunk失效信息等。HDFS接收到失效信息后,删除Chunk文件;
l KFS:启动时或者在读操作ChunkSum错误时,向MetaServer汇报Chunk信息。MetaServer删除Chunk有两类操作:Delete和Stale。前者由Client触发,后者由ChunkServer汇报错误触发。Delete操作下,ChunkServer直接删除chunk文件;Stale操作下,ChunkServer将Chunk转移到./lost+found目录下。但KFS0.2.2中没有对./lost+found目录中的文件做进一步处理,也许改进版本中会用到。
13、HDFS和KFS Chunk写流程上的区别(1)
HDFS Chunk 写流程,如图3
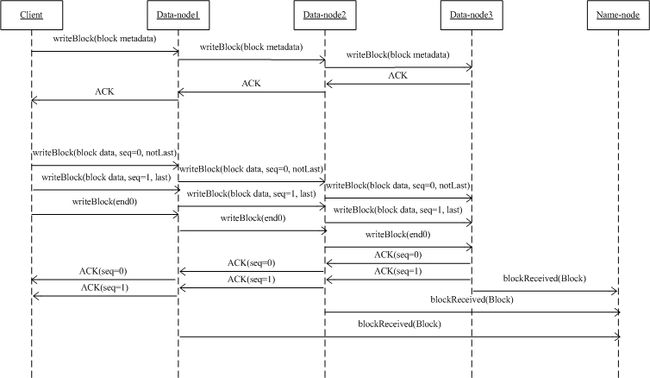
图3 HDFS Chunk 写流程
14、HDFS和KFS Chunk写流程上的区别(2)
KFS Chunk 写流程,如图4

图4 KFS Chunk 写流程
from: http://blog.csdn.net/Cloudeep/article/details/4467238