更好的使用Java集合(二)
散列集(HashSet)与树集(TreeSet)
常用的集合类型
| 常用集合类型 |
描述 |
| ArrayList |
一种可以动态增长和缩减的索引序列 |
| LinkedList |
一种可以在任何位置进行高效地插入和删除操作的有序序列 |
| ArrayDeque |
一种循环数组实现的双端队列 |
| HashSet |
一种没有重复元素的无序集合 |
| TreeSet |
一种有序集 |
| EnumSet |
一种包含枚举类型值的集 |
| LinkedHashSet |
一种可以记住元素插入次序的集 |
| PriorityQueue |
一种允许高效删除最小元素的集合 |
| HashMap |
一种存储健值关联的数据结构 |
| TreeMap |
一种健值有序排列的映射表 |
| LinkedHashMap |
一种可以记住健值项添加次序的映射表 |
| WeakHashMap |
一种其值无用武之地后可以被垃圾回收器回收的映射表 |
| IdentityHashMap | 一种用==,而不使用equals比较健值的映射 |
链表和数组可以按意愿排列元素的次序,但是如果想要查看某个元素,又不知道或者忘记了它的位置,就需要访问所有元素,直到找到为止。如果集合中包含的元素 很多,将会消耗很多时间。如果不在意元素的次序,可以有几种能够快速查找元素的数据结构。其缺点就是无法控制元素的出现次序,因为这些数据结构会按照有利 于其操作目的的原则组织数据。
有一种数据结构可以快速的查找所有需要的对象,就是散列表(hashtable)。散列表为每个对象计算一个整数,称为散列码(hashcode)。散列码是由对象的实例域产生的一个整数。更准确地说,具有不同数据域的对象将产生不同的散列码。
上图列出了几个String对象散列码的实例,如果是自定义的类,就要负责实现这个类的hashCode方法。hashCode方法应该与equals方法兼容,即如果a.equals(b)为true,那么a与b必须有相同的散列码。
在 java中,散列表用链表数组实现。每个列表被称为桶(bucket)。想要查找表中对象的位置,需要用对象的散列码与桶的总数取余,例如上图对象str 的散列码是3179,加入集合的桶数是128,那么str将在(3179除以128余107)107号桶中。有时桶已经被占满,也是不可避免的。这种情况 被称之为散列冲突(hash collision)。这时,需要用新对象与桶中的所有对象进行比较,查看这个对象是否已经存在。如果散列码是合理且随机分布的,桶的数目也足够大,需要 比较的次数就会很少。
如果想要更多地控制散列表的运行性能,可以指定一个初始的桶数。通常,将桶数设置为预计元素个数的75%~150%。有些研究人员认为:尽管还没有确凿的证据,但最好将桶数设置为一个素数,以防键的聚集。
当 然,并不是总能知道需要存储多少个元素,也有可能最初的估计过低。如果散列表太满,就需要再散列(rehashed)。如果对散列表再散列,就需要创建一 个新的桶数更多的散列表,并将所有元素插入到这个新表中,然后丢弃原来的表。填装因子(load factor)决定何时对散列表进行再散列。例如,如果填装因子是0.75(默认值),而散列表中超过75%的位置已经填入元素,这个散列表就会用双倍的 桶数自动地进行再散列。对于大多数程序来说,75%是比较合理的填装因子数。
Java提供了一个HashSet类,它基于的就是散 列表的集。可以用add方法添加元素,如果元素不存在,就可以添加到集合。同时,contains方法已经被重新定义,用来快速地查看是否某个元素已经出 现在集中。它只根据桶来查找元素,不必查看集合中所有的元素。
散列集迭代器将依次访问所有的桶。由于散列将元素分散在表的各个位置上,所以访问它们的顺序几乎是随机的。只有不关心集合中元素的顺序时才应该使用hashset类。
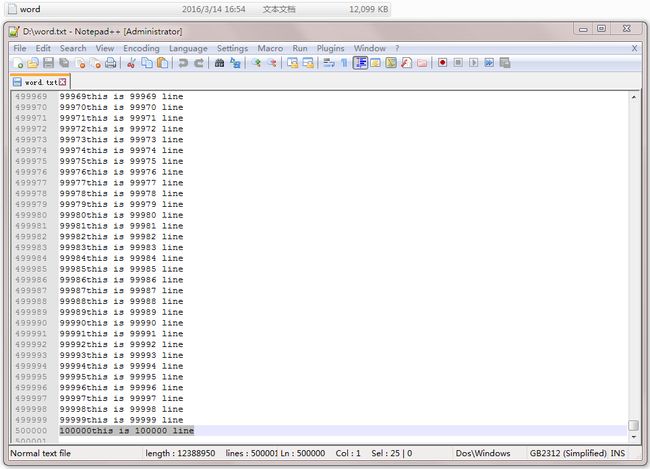
下面做一个测试,从50万行数据中读取每一行并保存到hashset中,文件中每行会重复5次,最终会得到一个有10万个元素的hashset:
@Test
public void SetTest() throws Exception {
HashSet<String> words = new HashSet<String>();
// 从文件中读取每一行,添加到hashset中。
String encoding = "GBK";
int maxline = 0;
File file = new File("D://word.txt");
if (file.isFile() && file.exists()) {
InputStreamReader read = new InputStreamReader(new FileInputStream(
file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTxt = null;
while ((lineTxt = bufferedReader.readLine()) != null) {
words.add(lineTxt);
maxline++;
}
read.close();
}
else System.out.println("no file");
System.out.println("word.txt文档一共有行数:" + maxline);
System.out.println("========================");
// 访问hashset中的数据。
int sum = 0;
Iterator<String> iterator = words.iterator();
while (iterator.hasNext()) {
String str = iterator.next();
if(sum < 20) {
System.out.println(str);
}
sum++;
}
System.out.println(". . . ");
System.out.println("hashset中共有元素" + sum + "个");
}
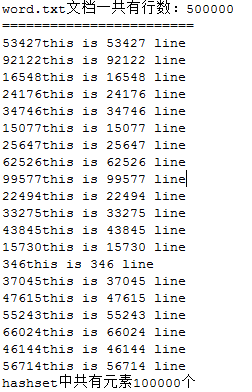
可以看到重复的数据并没有保存到hashset中,而且元素的位置是随机的。在更改集中的元素时要格外小心。如果元素的散列码发生了变化,元素在数据结构中的位置也会发生改变。
TreeSet类与散列集十分类似,不过它比散列集有所改进。TreeSet是一个有序集合(sorted collection)。可以以任意顺序将元素插入到集合中。在对集合进行便利时,每个值将自动按照排序后的顺序呈现。
@Test
public void TreeSetTest()
{
TreeSet<String> treeSet = new TreeSet<String>();
treeSet.add("Bob");
treeSet.add("Amy");
treeSet.add("Carl");
for(String s : treeSet)
System.out.println(s);
}
/**
* output
* Amy
* Bob
* Carl
* */
可以看到将字符串添加到treeset中,输出时按照字符串的排序进行了打印,字母A在B之前。TreeSet类的排序是用树结构完成的(当前实现使用的是红黑树red - black - tree)。每次将一个元素添加到树中,都会被放置在正确的排序位置上。因此,迭代器总是以排好序的顺序访问每个元素。
讲一个元素添加到树中要比添加到散列表中慢,但是,与元素添加到数组或链表的正确位置上相比还是要快很多的。如果树中包涵n个元素,查找新元素的正确位置平均要log2n次比较。例如一棵树包含了1000个元素,添加一个新元素大约需要比较10次。
TreeSet在默认情况下,假定插入的元素实现了Comparable接口。也就是说,如果a与b相等,调用a.compareTo(b)一定返回0;如果a排序在b之前,则返回负数;如果a位于b之后,则返回正值。具体返回什么值并不重要,关键是符号(>0、0或<0)。
然而,使用Comparable接口定义排序显然尤其局限性。对于一个给定的类,只能够实现这个接口一次。如果在一个集合中需要通过一个优先级字段排序,而在另一个集合中却要按照名称排序该怎么办呢?另外,如果需要对一个类的对象进行排序,而这个累的创建者又没有实现Comparable接口,又该怎么办呢?
这种情况下,可以通过将Comparator对象传递给TreeSet构造器来告诉TreeSet使用不同的比较方法。
写一段代码来测试一下:
public class Task implements Comparable<Task> {
public Task() {
}
public Task(String name, int priority) {
super();
this.name = name;
this.priority = priority;
}
@Override
public int hashCode() {
return 13 * name.hashCode() + 17 * priority;
}
@Override
public boolean equals(Object obj) {
if(this == obj) return true;
if(obj == null) return false;
if(getClass() != obj.getClass()) return false;
Task t = (Task)obj;
return name.equals(t.getName()) && priority == t.getPriority();
}
public int compareTo(Task t) {
return priority - t.priority;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getPriority() {
return priority;
}
public void setPriority(int priority) {
this.priority = priority;
}
private String name;
private int priority;
}
上面这个类实现了Comparator接口,使用的是对象的优先级字段进行排序。下面将这个对象放到TreeSet中。
@Test
public void TreeSetTest() throws Exception {
// 通过对象实现的compareTo方法进行排序。
TreeSet<Task> treeSet = new TreeSet<Task>();
treeSet.add(new Task("task3", 2));
treeSet.add(new Task("task1", 3));
treeSet.add(new Task("task2", 1));
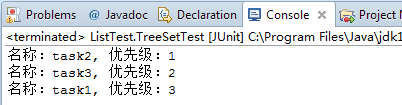
for (Task t : treeSet)
System.out.println(t.getName() + "," + t.getPriority());
// 还可以通过创建集合时指定的方式进行排序。
TreeSet<Task> treeSetByName = new TreeSet<Task>(new Comparator<Task>(){
@Override
public int compare(Task o1, Task o2) {
return o1.getName().compareTo(o2.getName());
}
});
System.out.println();
treeSetByName.addAll(treeSet);
for (Task t : treeSetByName)
System.out.println(t.getName() + "," + t.getPriority());
}
第一个treeSet对象使用Task对象实现的比较方法进行排序,输出如下:
而第二个treeSetByName对象使用了在构造时传入的比较方法去进行排序,传入了通过名称来排序,输入结果如下:
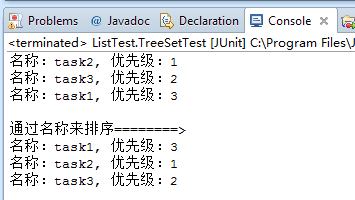
现在考虑一个问题,是否总是应该用treeset取代hashset呢?毕竟,treeset添加一个元素所花费的时候看上去并不长,而且元素是自动排序的。
到底应该怎样做将取决于索要收集的数据。
如果不需要对数据进行排序,就没有必要付出排序的开销。更重要的是,对于某些数据来说,对其排序要比散列函数更加困难。散列函数只是将对象适当地打乱顺序存放,而比较却要精确地判别每个对象。
另外,如果使用TreeSet,在集合中存放矩形(rectangle),该如何比较两个矩形呢?比较面积行不通,可能有两个长宽不等的矩形,他们的坐标不同,但面积却相同。
树的排序必须是整体排序,也就是说,任意两个元素必须是可比的,并且只有在两个元素相等时结果才为0。