消息中间件ActiveMQ与Kafka对比之Kafka
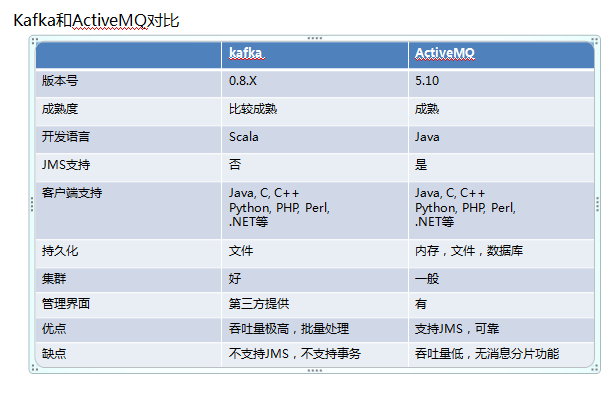
由于消息中间件这块产品非常多,现在只挑选两个我使用过的产品结合使用经验做一些研究,他们是ActiveMQ和Kafka。ActiveMQ 是Apache出品,最流行的、功能强大的即时通讯和集成模式的开源服务器。ActiveMQ 是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,提供客户端支持跨语言和协议,带有易于在充分支持JMS 1.1和1.4使用J2EE企业集成模式和许多先进的功能。Kafka看上去有一些“野路子”,并没有纠结于JMS规范,剑走偏锋的设计了另一套吞吐非常高的分布式发布-订阅消息系统,目前非常流行,Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。接下来我们结合三个点(消息安全性,服务器的稳定性容错性以及吞吐量)来分别谈谈这两个消息中间件。今天我们谈Kafka,ActiveMQ的文章在此。
性能怪兽Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。”Apache Kafka is publish-subscribe messaging rethought as a distributed commit log.”,官网首页的一句话高度概括其职责。Kafka并没有遵守JMS规范,他只用文件系统来管理消息的生命周期。Kafka的设计目标是:
(1)以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
(2)高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
(3)支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
(4)同时支持离线数据处理和实时数据处理。
(5)Scale out:支持在线水平扩展。
所以,不像AMQ,Kafka从设计开始极为高可用为目的,天然HA。broker支持集群,消息亦支持负载均衡,还有副本机制。同样,Kafka也是使用Zookeeper管理集群节点信息,包括consumer的消费信息也是保存在zk中,下面我们分话题来谈:
1)消息的安全性
Kafka集群中的Leader负责某一topic的某一partition的消息的读写,理论上consumer和producer只与该Leader节点打交道,一个集群里的某一broker即是Leader的同时也可以担当某一partition的follower,即Replica。Kafka分配Replica的算法如下:
(1)将所有Broker(假设共n个Broker)和待分配的Partition排序
(2)将第i个Partition分配到第(i mod n)个Broker上
(3)将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
同时,Kafka与Replica既非同步也不是严格意义上的异步。一个典型的Kafka发送-消费消息的过程如下:首先首先Producer消息发送给某Topic的某Partition的Leader,Leader先是将消息写入本地Log,同时follower(如果落后过多将会被踢出出Replica列表)从Leader上pull消息,并且在未写入log的同时即向Leader发送ACK的反馈,所以对于某一条已经算作commit的消息来讲,在某一时刻,其存在于Leader的log中,以及Replica的内存中。这可以算作一个危险的情况(听起来吓人),因为如果此时集群挂了这条消息就算丢失了,但结合producer的属性(request.required.acks=2 当所有follower都收到消息后返回ack)可以保证在绝大多数情况下消息的安全性。当消息算作commit的时候才会暴露给consumer,并保证at-least-once的投递原则。
2)服务的稳定容错性
前面提到过,Kafka天然支持HA,整个leader/follower机制通过zookeeper调度,它在所有broker中选出一个controller,所有Partition的Leader选举都由controller决定,同时controller也负责增删Topic以及Replica的重新分配。如果Leader挂了,集群将在ISR(in-sync replicas)中选出新的Leader,选举基本原则是:新的Leader必须拥有原来的Leader commit过的所有消息。假如所有的follower都挂了,Kafka会选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader,因为如果此时等待ISR中的Replica是有风险的,假如所有的ISR都无法“活”,那此partition将会变成不可用。
3) 吞吐量
Leader节点负责某一topic(可以分成多个partition)的某一partition的消息的读写,任何发布到此partition的消息都会被直接追加到log文件的尾部,因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证),同时通过合理的partition,消息可以均匀的分布在不同的partition里面。Kafka基于时间或者partition的大小来删除消息,同时broker是无状态的,consumer的消费状态(offset)是由consumer自己控制的(每一个consumer实例只会消费某一个或多个特定partition的数据,而某个partition的数据只会被某一个特定的consumer实例所消费),也不需要broker通过锁机制去控制消息的消费,所以吞吐量惊人,这也是Kafka吸引人的地方。
最后说下由于zookeeper引起的脑裂(Split Brain)问题:每个consumer分别单独通过Zookeeper判断哪些partition down了,那么不同consumer从Zookeeper“看”到的view就可能不一样,这就会造成错误的reblance尝试。而且有可能所有的consumer都认为rebalance已经完成了,但实际上可能并非如此。

参考资料:
http://kafka.apache.org
http://www.jasongj.com/2015/03/10/KafkaColumn1/
http://www.jasongj.com/2015/04/24/KafkaColumn2/
https://github.com/alibaba/RocketMQ
http://blog.csdn.net/damacheng/article/details/42846549
性能怪兽Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache定级项目。”Apache Kafka is publish-subscribe messaging rethought as a distributed commit log.”,官网首页的一句话高度概括其职责。Kafka并没有遵守JMS规范,他只用文件系统来管理消息的生命周期。Kafka的设计目标是:
(1)以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能。
(2)高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输。
(3)支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输。
(4)同时支持离线数据处理和实时数据处理。
(5)Scale out:支持在线水平扩展。
所以,不像AMQ,Kafka从设计开始极为高可用为目的,天然HA。broker支持集群,消息亦支持负载均衡,还有副本机制。同样,Kafka也是使用Zookeeper管理集群节点信息,包括consumer的消费信息也是保存在zk中,下面我们分话题来谈:
1)消息的安全性
Kafka集群中的Leader负责某一topic的某一partition的消息的读写,理论上consumer和producer只与该Leader节点打交道,一个集群里的某一broker即是Leader的同时也可以担当某一partition的follower,即Replica。Kafka分配Replica的算法如下:
(1)将所有Broker(假设共n个Broker)和待分配的Partition排序
(2)将第i个Partition分配到第(i mod n)个Broker上
(3)将第i个Partition的第j个Replica分配到第((i + j) mode n)个Broker上
同时,Kafka与Replica既非同步也不是严格意义上的异步。一个典型的Kafka发送-消费消息的过程如下:首先首先Producer消息发送给某Topic的某Partition的Leader,Leader先是将消息写入本地Log,同时follower(如果落后过多将会被踢出出Replica列表)从Leader上pull消息,并且在未写入log的同时即向Leader发送ACK的反馈,所以对于某一条已经算作commit的消息来讲,在某一时刻,其存在于Leader的log中,以及Replica的内存中。这可以算作一个危险的情况(听起来吓人),因为如果此时集群挂了这条消息就算丢失了,但结合producer的属性(request.required.acks=2 当所有follower都收到消息后返回ack)可以保证在绝大多数情况下消息的安全性。当消息算作commit的时候才会暴露给consumer,并保证at-least-once的投递原则。
2)服务的稳定容错性
前面提到过,Kafka天然支持HA,整个leader/follower机制通过zookeeper调度,它在所有broker中选出一个controller,所有Partition的Leader选举都由controller决定,同时controller也负责增删Topic以及Replica的重新分配。如果Leader挂了,集群将在ISR(in-sync replicas)中选出新的Leader,选举基本原则是:新的Leader必须拥有原来的Leader commit过的所有消息。假如所有的follower都挂了,Kafka会选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader,因为如果此时等待ISR中的Replica是有风险的,假如所有的ISR都无法“活”,那此partition将会变成不可用。
3) 吞吐量
Leader节点负责某一topic(可以分成多个partition)的某一partition的消息的读写,任何发布到此partition的消息都会被直接追加到log文件的尾部,因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证),同时通过合理的partition,消息可以均匀的分布在不同的partition里面。Kafka基于时间或者partition的大小来删除消息,同时broker是无状态的,consumer的消费状态(offset)是由consumer自己控制的(每一个consumer实例只会消费某一个或多个特定partition的数据,而某个partition的数据只会被某一个特定的consumer实例所消费),也不需要broker通过锁机制去控制消息的消费,所以吞吐量惊人,这也是Kafka吸引人的地方。
最后说下由于zookeeper引起的脑裂(Split Brain)问题:每个consumer分别单独通过Zookeeper判断哪些partition down了,那么不同consumer从Zookeeper“看”到的view就可能不一样,这就会造成错误的reblance尝试。而且有可能所有的consumer都认为rebalance已经完成了,但实际上可能并非如此。
参考资料:
http://kafka.apache.org
http://www.jasongj.com/2015/03/10/KafkaColumn1/
http://www.jasongj.com/2015/04/24/KafkaColumn2/
https://github.com/alibaba/RocketMQ
http://blog.csdn.net/damacheng/article/details/42846549