Lex使用指南
Lex使用指南
Lex是由美国Bell实验室M.Lesk等人用C语言开发的一种词法分析器自动生成工具,它提供一种供开发者编写词法规则(正规式等)的语言(Lex语言)以及这种语言的翻译器(这种翻译器将Lex语言编写的规则翻译成为C语言程序)。
Lex是linux下的工具,本实验使用的编译工具是cygwin(cygwin在windows下模拟一个linux环境)下的flex,它与lex的使用方法基本相同,只有很少的差别。
一、Lex的基本原理和使用方法
Lex的基本工作原理为:由正规式生成NFA,将NFA变换成DFA,DFA经化简后,模拟生成词法分析器。
其中正规式由开发者使用Lex语言编写,其余部分由Lex翻译器完成.翻译器将Lex源程序翻译成一个名为lex.yy.c的C语言源文件,此文件含有两部分内容:一部分是根据正规式所构造的DFA状态转移表,另一部分是用来驱动该表的总控程序yylex()。当主程序需要从输入字符流中识别一个记号时,只需要调用一次yylex()就可以了。为了使用Lex所生成的词法分析器,我们需要将lex.yy.c程序用C编译器进行编译,并将相关支持库函数连入目标代码。Lex的使用步骤可如下图所示:
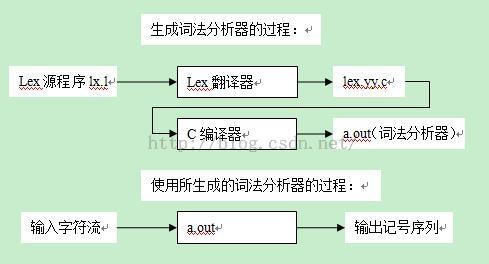
二、lex源程序的写法:
Lex源程序必须按照Lex语言的规范来写,其核心是一组词法规则(正规式)。一般而言,一个Lex源程序分为三部分,三部分之间以符号%%分隔。
[第一部分:定义段]
%%
第二部分:词法规则段
[%%
第三部分:辅助函数段]
其中,第一部分及第三部分和第三部分之上的%%都可以省略(即上述方括号括起的部分可以省略)。以%开头的符号和关键字,或者是词法规则段的各个规则一般顶着行首来写,前面没有空格。
Lex源程序中可以有注释,注释由/*和*/括起,但是请注意,注释的行首需要有前导空白。
1. 第一部分定义段的写法:
定义段可以分为两部分:
第一部分以符号%{和%}包裹,里面为以C语法写的一些定义和声明:例如,文件包含,宏定义,常数定义,全局变量及外部变量定义,函数声明等。这一部分被Lex翻译器处理后会全部拷贝到文件lex.yy.c中。注意,特殊括号%{和%}都必须顶着行首写。例如:
%{
#define LT 1
intyylval;
%}
第二部分是一组正规定义和状态定义。正规定义是为了简化后面的词法规则而给部分正规式定义了名字。每条正规定义也都要顶着行首写。例如下面这组正规定义分别定义了letter,digit和id所表示的正规式:
letter [A-Za-z]
digit [0-9]
id {letter}({letter}|{digit})*
注意:上面正规定义中出现的小括号表示分组,而不是被匹配的字符。而大括号括起的部分表示正规定义名。
状态定义也叫环境定义,它定义了匹配正规式时所处的状态的名字。状态定义以%s开始,后跟所定义的状态的名字,注意%s也要顶行首写,例如下面一行就定义了一个名为COMMENT的状态和一个名为BAD的状态,状态名之间用空白分隔:
%s COMMENT BAD
2. 第二部分词法规则段的写法:
词法规则段列出的是词法分析器需要匹配的正规式,以及匹配该正规式后需要进行的相关动作。其例子如下:
while {return (WHILE);}
do {return (DO);}
{id} {yylval = installID (); return (ID);}
每行都是一条规则,该规则的前一部分是正规式,需要顶行首写,后一部分是匹配该正规式后需要进行的动作,这个动作是用C语法来写的,被包裹在{}之内,被Lex翻译器翻译后会被直接拷贝进lex.yy.c。正规式和语义动作之间要有空白隔开。其中用{}扩住的正规式表示正规定义的名字。
也可以若干个正规式匹配同一条语义动作,此时正规式之间要用 | 分隔。
3. 第三部分辅助函数段的写法:
辅助函数段用C语言语法来写,辅助函数一般是在词法规则段中用到的函数。这一部分一般会被直接拷贝到lex.yy.c中。
4. Lex源程序中词法规则(即正规式)的相关规定:
元字符:元字符是lex语言中作特殊用途的一些字符,包括:* + ? | { } [ ] ( ). ^ $ “ \ - / < >。
正文字符:除元字符以外的其他字符,这些字符在正规式中可以被匹配。若单个正文字符c作为正规式,则可与字符c匹配,元字符无法被匹配,如果元字符想要被匹配,则需要通过“转义”的方式,即用” ”包括住元字符,或在元字符前加\。例如”+”和\+都表示加号。C语言中的一些转义字符也可以出现在正规式中,例如\t \n \b等。
部分元字符在lex语言中的特殊含义:
^表示补集:[^…]表示补集,即匹配除^之后所列字符以外的任何字符。如[^0-9]表示匹配除数字字符0-9以外的任意字符。除^ - \以外,任何元字符在方括号内失去其特殊含义。如果要在方括号内表示负号-,则要将其至于方括号内的第一个字符位置或者最后一个字符位置,例如[-+0-9][+0-9-]都匹配数字及+ - 号。
. ^$ /:
点运算符 . 匹配除换行之外的任何字符,一般可作为最后一条翻译规则。
^匹配行首字符。如:^begin匹配出现在行首的begin
$匹配行末字符。如:end$ 匹配出现在行末的end
R1/R2(R1和R2是正规式)表示超前搜索:若要匹配R1,则必须先看紧跟其后的超前搜索部分是否与R2匹配。
如:DO/{alnum}*={alnum}*,表示如果想匹配DO,则必须先在DO后面找到形式为{alnum}*={alnum}*的串,才能确定匹配DO。
5. Lex源程序中常用到的变量及函数:
yyin和yyout:这是Lex中本身已定义的输入和输出文件指针。这两个变量指明了lex生成的词法分析器从哪里获得输入和输出到哪里。默认:键盘输入,屏幕输出。
yytext和yyleng:这也是lex中已定义的变量,直接用就可以了。
yytext:指向当前识别的词法单元(词文)的指针
yyleng:当前词法单元的长度。
ECHO:Lex中预定义的宏,可以出现在动作中,相当于fprintf(yyout, “%s”,yytext),即输出当前匹配的词法单元。
yylex():词法分析器驱动程序,用Lex翻译器生成的lex.yy.c内必然含有这个函数。
yywrap():词法分析器遇到文件结尾时会调用yywrap()来决定下一步怎么做:
若yywrap()返回0,则继续扫描
若返回1,则返回报告文件结尾的0标记。
由于词法分析器总会调用yywrap,因此辅助函数中最好提供yywrap,如果不提供,则在用C编译器编译lex.yy.c时,需要链接相应的库,库中会给出标准的yywrap函数(标准函数返回1)。
6. 词法分析器的状态(环境):
词法分析器在匹配正规式时,可以在不同状态(或环境)下进行。我们可以规定在不同的状态下有不同的匹配方式。每个词法分析器都至少有一个状态,这个状态叫做初始状态,可以用INITIAL或0来表示,如果还需要使用其他状态,可以在定义段用%s 来定义。
使用状态时,可以用如下方式写词法规则:
<state1, state2> p0 {action0;}
<state1> p1 {action1;}
这两行词法规则表示:在状态state1和state2下,匹配正规式p0后执行动作action0,而只有在状态state1下,才可以匹配正规式p1后执行动作action1。如果不指明状态,默认情况下处于初始状态INITIAL。
要想进入某个特定状态,可以在动作中写上这样一句: BEGINstate; 执行这个动作后,就进入状态state。
下面是一段处理C语言注释的例子,里面用到了状态的转换,在这个例子里,使用不同的状态,可以让词法分析器在处于注释中和处于注释外时使用不同的匹配规则:
…
%s c_comment
…
%%
<INITIAL>“/*” {BEGIN c_comment;}
…
<c_comment>“*/” {BEGIN 0;}
<c_comment>. {;}
7. Lex的匹配策略:
(1) 按最长匹配原则确定被选中的单词
(2) 如果一个字符串能被若干正规式匹配,则先匹配排在前面的正规式。
三、Lex生成的词法分析器如何使用:
lex常常与语法分析器的生成工具yacc(第三章会讲到)同时使用。此时,一般来说,语法分析器每次都调用一次 yylex()获取一个记号。如果想自己写一个程序使用lex生成的词法分析器,则只需要在自己的程序中按需要调用yylex()函数即可。
请注意:yylex()调用结束后,输入缓冲区并不会被重置,而是仍然停留在刚才读到的地方。并且,词法分析器当前所处的状态(%s定义的那些状态)也不会改变。
完整的Lex源程序例子请见exam1.l和exam2.l。
exam1.l
/* 这是注释的形式,与C中的/*...* /注释相同。 */
/* 第一部分是定义、声明部分。这部分内容可以为空。*/
%{
/* 写在 %{...%}这对特殊括号内的内容会被直接拷贝到C文件中。
*
* 这部分通常进行一些头文件声明,变量(全局,外部)、常量
* 的定义,用C语法。
*
* %{和%}两个符号都必须位于行首
*/
/* 下面定义了需要识别的记号名,如果和yacc联合使用,这些记号名都应该在yacc中定义 */
#include <stdio.h>
#define LT 1
#define LE 2
#define GT 3
#define GE 4
#define EQ 5
#define NE 6
#define WHILE 18
#define DO 19
#define ID 20
#define NUMBER 21
#define RELOP 22
#define NEWLINE 23
#define ERRORCHAR 24
int yylval;
/* yylval 是yacc中定义的变量,用来保存记号的属性值,默认是int类型。
* 在用lex实现的词法分析器中可以使用这个变量将记号的属性传递给用
* yacc实现的语法分析器。
*
* 注意:该变量只有在联合使用lex和yacc编写词法和语法分析器时才可在lex
* 中使用,此时该变量不需要定义即可使用。
* 单独使用lex时,编译器找不到这个变量。这里定义该变量为了“欺骗”编译器。
*/
%}
/* 这里进行正规定义和状态定义。
* 下面就是正规定义,注意,正规定义和状态定义都要顶着行首写。
*/
delim [ \t \n]
/* \用来表示转义,例如\t表示制表符,\n表示换行符。*/
ws {delim}+
letter [A-Za-z_]
digit [0-9]
id {letter}({letter}|{digit})*
/* 注意:上面正规定义中出现的小括号表示分组,而不是被匹配的字符。
* 而大括号括起的部分表示正规定义名。
*/
number {digit}+(\.{digit}+)?(E[+-]?{digit}+)?
/* %%作为lex文件三个部分的分割符,必须位于行首 */
/* 下面这个%%不能省略 */
%%
/* 第二部分是翻译规则部分。 */
/* 写在这一部分的注释要有前导空格,否则lex编译出错。*/
/* 翻译规则的形式是:正规式 {动作}
* 其中,正规式要顶行首写,动作要以C语法写(动作会被拷贝到yylex()函数中,),\
* 正规式和动作之间要用空白分割。
*/
{ws} {;/* 此时词法分析器没有动作,也不返回,而是继续分析。 */}
/* 正规式部分用大括号扩住的表示正规定义名,例如{ws}。
* 没有扩住的直接表示正规式本身。
* 一些元字符没办法表示它本身,此时可以用转义字符或
* 用双引号括起来,例如"<"
*/
while {return (WHILE);}
do {return (DO);}
{id} {yylval = installID (); return (ID);}
{number} {yylval = installNum (); return (NUMBER);}
"<" {yylval = LT; return (RELOP);}
"<=" {yylval = LE; return (RELOP);}
"=" {yylval = EQ; return (RELOP);}
"<>" {yylval = NE; return (RELOP);}
">" {yylval = GT; return (RELOP);}
">=" {yylval = GE; return (RELOP);}
. {yylval = ERRORCHAR; return ERRORCHAR;}
/*.匹配除换行之外的任何字符,一般可作为最后一条翻译规则。*/
%%
/* 第三部分是辅助函数部分,这部分内容以及前面的%%都可以省略 */
/* 辅助函数可以定义“动作”中使用的一些函数。这些函数
* 使用C语言编写,并会直接被拷贝到lex.yy.c中。
*/
int installID () {
/* 把词法单元装入符号表并返回指针。*/
return ID;
}
int installNum () {
/* 类似上面的过程,但词法单元不是标识符而是数 */
return NUMBER;
}
/* yywrap这个辅助函数是词法分析器遇到输入文件结尾时会调用的,用来决定下一步怎么做:
* 若yywrap返回0,则继续扫描;返回1,则词法分析器返回报告文件已结束的0。
* lex库中的标准yywrap程序就是返回1,你也可以定义自己的yywrap。
*/
int yywrap (){
return 1;
}
void writeout(int c){
switch(c){
case ERRORCHAR: fprintf(yyout, "(ERRORCHAR, \"%s\") ", yytext);break;
case RELOP: fprintf(yyout, "(RELOP, \"%s\") ", yytext);break;
case WHILE: fprintf(yyout, "(WHILE, \"%s\") ", yytext);break;
case DO: fprintf(yyout, "(DO, \"%s\") ", yytext);break;
case NUMBER: fprintf(yyout, "(NUM, \"%s\") ", yytext);break;
case ID: fprintf(yyout, "(ID, \"%s\") ", yytext);break;
case NEWLINE: fprintf(yyout, "\n");break;
default:break;
}
return;
}
/* 辅助函数里可以使用yytext和yyleng这些外部定义的变量。
* yytext指向输入缓冲区当前词法单元(lexeme)的第一个字符,
* yyleng给出该词法单元的长度 */
/* 如果你的词法分析器并不是作为语法分析器的子程序,
* 而是有自己的输入输出,你可以在这里定义你的词法
* 分析器的main函数,main函数里可以调用yylex()
*/
int main (int argc, char ** argv){
int c,j=0;
if (argc>=2){
if ((yyin = fopen(argv[1], "r")) == NULL){
printf("Can't open file %s\n", argv[1]);
return 1;
}
if (argc>=3){
yyout=fopen(argv[2], "w");
}
}
/* yyin和yyout是lex中定义的输入输出文件指针,它们指明了
* lex生成的词法分析器从哪里获得输入和输出到哪里。
* 默认:键盘输入,屏幕输出。
*/
while (c = yylex()){
writeout(c);
j++;
if (j%5 == 0) writeout(NEWLINE);
}
if(argc>=2){
fclose(yyin);
if (argc>=3) fclose(yyout);
}
return 0;
}
exam2.l
/* 把注释去掉 */
%{
#include <stdio.h>
#define LT 1
#define LE 2
#define GT 3
#define GE 4
#define EQ 5
#define NE 6
#define LLK 7
#define RLK 8
#define LBK 9
#define RBK 10
#define IF 11
#define ELSE 12
#define EQU 13
#define SEM 14
#define WHILE 18
#define DO 19
#define ID 20
#define NUMBER 21
#define RELOP 22
#define NEWLINE 23
#define ERRORCHAR 24
#define ADD 25
#define DEC 26
#define MUL 27
#define DIV 28
%}
delim [ \t \n]
ws {delim}+
letter [A-Za-z_]
digit [0-9]
id {letter}({letter}|{digit})*
number {digit}+(\.{digit}+)?(E[+-]?{digit}+)?
/* 状态(或条件)定义可以定义在这里
* INITIAL是一个默认的状态,不需要定义
*/
%s COMMENT
%s COMMENT2
%%
<INITIAL>"/*" {BEGIN COMMENT;}
<COMMENT>"*/" {BEGIN INITIAL;}
<COMMENT>.|\n {;}
<INITIAL>"//" {BEGIN COMMENT2;}
<COMMENT2>\n {BEGIN INITIAL;}
<COMMENT2>. {;}
/* ECHO是一个宏,相当于 fprintf(yyout, "%s", yytext)*/
<INITIAL>{ws} {;}
<INITIAL>while {return (WHILE);}
<INITIAL>do {return (DO);}
<INITIAL>if {return (IF);}
<INITIAL>else {return (ELSE);}
<INITIAL>{id} {return (ID);}
<INITIAL>{number} {return (NUMBER);}
<INITIAL>"<" {return (RELOP);}
<INITIAL>"<=" {return (RELOP);}
<INITIAL>"=" {return (RELOP);}
<INITIAL>"!=" {return (RELOP);}
<INITIAL>">" {return (RELOP);}
<INITIAL>">=" {return (RELOP);}
<INITIAL>"(" {return (RELOP);}
<INITIAL>")" {return (RELOP);}
<INITIAL>"{" {return (RELOP);}
<INITIAL>"}" {return (RELOP);}
<INITIAL>"+" {return (RELOP);}
<INITIAL>"-" {return (RELOP);}
<INITIAL>"*" {return (RELOP);}
<INITIAL>"/" {return (RELOP);}
<INITIAL>";" {return (RELOP);}
<INITIAL>. {return ERRORCHAR;}
%%
int yywrap (){
return 1;
}
void writeout(int c){
switch(c){
case ERRORCHAR: fprintf(yyout, "(ERRORCHAR, \"%s\") ", yytext);break;
case RELOP: fprintf(yyout, "(RELOP, \"%s\") ", yytext);break;
case WHILE: fprintf(yyout, "(WHILE, \"%s\") ", yytext);break;
case DO: fprintf(yyout, "(DO, \"%s\") ", yytext);break;
case IF: fprintf(yyout, "(IF, \"%s\") ", yytext);break;
case ELSE: fprintf(yyout, "(ELSE, \"%s\") ", yytext);break;
case NUMBER: fprintf(yyout, "(NUM, \"%s\") ", yytext);break;
case ID: fprintf(yyout, "(ID, \"%s\") ", yytext);break;
case NEWLINE: fprintf(yyout, "\n");break;
default:break;
}
return;
}
int main (int argc, char ** argv){
int c,j=0;
if (argc>=2){
if ((yyin = fopen(argv[1], "r")) == NULL){
printf("Can't open file %s\n", argv[1]);
return 1;
}
if (argc>=3){
yyout=fopen(argv[2], "w");
}
}
while (c = yylex()){
writeout(c);
j++;
if (j%5 == 0) writeout(NEWLINE);
}
if(argc>=2){
fclose(yyin);
if (argc>=3) fclose(yyout);
}
return 0;
}
test1.p:
while a >= -1.2E-2 do b<=2
test2.p:
while a >= -1.2E-2
do b<=2
if else
+
-
*
/
; //的发生过
/* 请注意:测试文件的格式必须符合要求,
比如,该文件要求的格式是UNIX格式。*/
四、cygwin下编译连接lex源程序的命令:
1. 用lex翻译器编译lex源程序命令(假设filename.l是lex源程序名):
flex filename.l
2. 用gcc编译器编译lex翻译器生成的c源程序(lex翻译器生成的c源程序名固定为lex.yy.c):
gcc [-o outfile] lex.yy.c –lfl
其中,-lfl是链接flex的库函数的,库函数中可能包含类似yywrap一类的标准函数。-o outfile是可选编译选项,该选项可将编译生成的可执行程序命名为outfile,如果不写该编译选项,默认情况下生成的可执行程序名为a.exe(linux下实际为a.out)。
3. 调用词法分析器yylex()的main函数可以写在lex源程序的辅助函数部分,也可以写在其他的c文件中。如果main函数写在main.c中,则编译时需要和lex.yy.c一起编译链接,即编译链接命令为:
gcc [-o outfile] lex.yy.cmain.c –lfl
4.运行可执行文件a.exe的命令(假设a.exe处于当前目录下,且忽略运行参数的情况):
./a.exe
其中,./表示当前目录。如果a.exe处于其他路径,则运行时请给出完整路径名。
五、关于cygwin
1. 网址:www.cygwin.com 是cygwin的官方网站,可以从上面下载安装cygwin。
2. 下载和安装:从上述网址下载setup.exe运行,即可选择从网络上安装cygwin,也可选择下载到本地,然后再从本地安装。
本地安装的过程:
1)将setup.exe及安装包下载到本地
2)运行setup.exe à 选择Install fromLocal Directory à 选一个root directory(例如可以选D:\cygwin,不要选中文路径名) à选一个Local Package Directory(选择存放安装包的那个目录)àselectpackages(其它都可以default,重要的是选中Devel下的bison,flex,gcc-core,gcc-g++, make,vim)
3. 使用cygwin:
安装完成后,检查环境变量中有没有HOME变量,如果有,先将HOME变量改名(方法:右键我的电脑à属性à高级à环境变量,在你自己的用户变量列表中找到HOME变量,改名)。
运行安装目录(root directory)下的cygwin.bat启动cygwin。第一次运行cygwin会生成home目录,如果home目录创建不成功,则很可能是HOME环境变量的缘故,先将这个变量改名,再运行cygwin.bat。
第一次运行成功后,所在目录应该是/home/your-user-name,请把你的文件存于该目录下。其中home目录实际上是在你选择的root directory下。