Python第三方库使用——splinter
功能:实现与html标签的交互,例如用编程的方式实现对页面中某一按键的点击,实现对文本框的填写。
准备
安装
pip install splinter下载浏览器(推荐使用chrome)驱动
请点击如下网站下载与自己操作系统相匹配的驱动程序。
http://chromedriver.storage.googleapis.com/index.html?path=2.20/
基本用法
如想获得直观的演示效果,推荐使用ipython,实现一种交互式的命令响应。
>>> from splinter.browser import Browser获得网页的“句柄”
>>> b = Browser(driver_name='chrome')
# 此时会打开chrome浏览器,
# b这个Browser对象会持有后续操作的页面
# 可将其理解为页面的句柄
# 也即通过操纵b来实现对页面的操纵访问某一站点
>>> url='https://www.baidu.com'
>>> b.visit(url)
# 会在浏览器中打开百度首页
# 是不是很神奇,通过代码的方式实现以前手动完成的事
# 更神奇的还在后面使用百度进行关键字的检索
为避免中英文编码方式的影响,这里我们统一使用页面标签的id属性而非text属性。
如,我们按如下的方式获取百度输入框的name属性值。
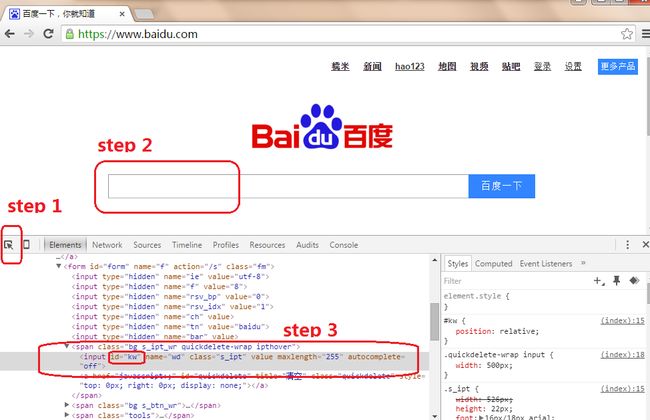
>>> b.fill('wd', 'splinter')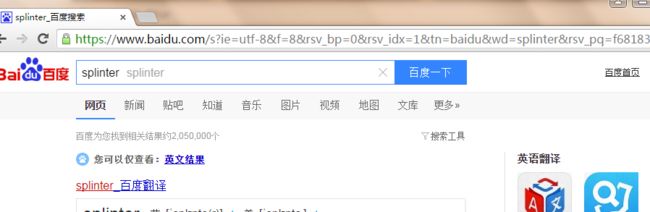
我们可以获得百度一下所标示的按钮,然后通过代码的方式实现对该按钮的点击。
>>> btn = b.find_by_id('kw')
>>> btn.click()或者连写:
>>> b.find_by_id('kw').click()注,因为当前百度搜索填写关键字会触发搜索结果的显示,所以这项演示似乎看起来click和不click影响不大。
杂项
# 判断页面是否存在
>>> b.is_text_present('splinter.cobrateam.info')
True
# 退出
>>> b.quit()一个实例
我们通过如下简单的代码实现对12306网站的相关标签的设置(以代码的形式操纵而非手动):
登录
>>> from splinter.browser import Browser
>>> url = 'https://kyfw.12306.cn/otn/leftTicket/init'
>>> b = Browser(driver_name='chrome')
>>> b.visit(url)
>>> b.find_by_id('login_user').click()
# 点击登录按钮
>>> b.fill('loginUserDTO.user_name', '****@qq.com')
>>> b.fill('userDTO.password', '****')
# 无奈,此时并不能通过简单的设置绕过验证码以cookie的形式设置始发站、终点站以及日期
>>> b.cookie.all()
# 显示当前cookie,并无站点实现信息
2
3
4
{u'BIGipServerotn': u'1977155850.38945.0000',
u'JSESSIONID': u'0A01D97598F459F751C4AE8518DBFB300DA7001B67',
u'__NRF': u'95D48FC2E0E15920BFB61C7A330FF2AE',
u'current_captcha_type': u'Z'}# 然后我们填写出发站,以下信息均需自己事先填写
>>> b.cookies.add({"_jc_save_fromStation":"%u4E0A%u6D77%2CSHH"})
# 添加目的地
>>> b.cookies.add({u'_jc_save_toStation':'%u6C38%u5DDE%2CAOQ'})
# 添加出发日期
>>> b.cookies.add({"_jc_save_fromDate":"2016-01-23"})
# 注,如果需要对相关信息进行修改的话,调用的是add方法,这和字典的操作相兼容
>>> b.cookies.add({u'_jc_save_toStation':'xxxxxx'})>>> b.cookies.all()
{u'BIGipServerotn': u'1977155850.38945.0000',
u'JSESSIONID': u'0A01D97598F459F751C4AE8518DBFB300DA7001B67',
u'__NRF': u'95D48FC2E0E15920BFB61C7A330FF2AE',
u'_jc_save_fromDate': u'2016-01-20',
u'_jc_save_fromStation': u'%u4E0A%u6D77%2CSHH',
u'_jc_save_toStation': u'%u6C38%u5DDE%2CAOQ',
u'current_captcha_type': u'Z'}cookie准备完毕,reload然后开始查询:
>>> b.reload()
>>>