HOG+SVM做行人检测,是非常经典的做法,但是真正使用过的人可以发现,就OpenCV提供的检测算算法而言,其实时性是非常差的。事实上,OpenCV中还做了一定的优化,比如利用CPU对多尺度行人检测进行一个并行计算,但是,在我笔记本上运行一次完整的检测过程需要1~2秒不等,这种检测速度,若是应用到无人驾驶技术上,检测到人估计那人已经撞飞了。。。为了提高检测速度,利用GPU并行计算是非常合适是解决办法之一。
研究了CUDA、HOG,SVM有一阵子了,甚至已经着手开始并行计算的任务,但是,却忽略了一个很重要、很关键的问题-------这些大量的检测时间都耗费在哪里了?
感谢老师的指点,让我重新思考这个问题,虽然可能在之前我有简单的考虑过这个问题,但是,工程上是不相信简单的思考的,需要的应该是实实在在的数据!
时间到底消耗在哪了?是HOG计算?是多尺度检测?是SVM计算?····还是?
只有真正搞清楚了这个问题,才能对症下药!
于是,我开始重新温故整个行人检测的过程。很容易,我们发现,去除模板训练的过程(因为这个可以是离线操作,线上不需要做),最主要的操作函数是detectMultiScale函数,这是一个多尺度行人检测的函数!
那什么是多尺度行人检测?这里感谢钱师兄给我的解释,简单明了
模板的大小往往是确定的,用得比较多的模板(好吧,我用得比较多)是(128,64)的模板,那么模板中人的大小实际上就有了一个限制。而我们处理的待检测图片的大小是不一定的,可能是640*480,可能是1280*760,这些完全取决于你使用的硬件分辨的支持程度,大小不一带来的问题就是人的大小和模板可能相去甚远,这些大小上的差别很可能就会让算法漏检!为了解决这个问题,其中一个解决办法,也正是detectMultiScale函数中使用的办法就是,将待检测图片缩小成很多个尺寸的图片,那么这些图片中人的大小总会有一个尺寸是适合(其实也不一定,我觉得受到了图片层数的限制)模板的大小的,这样就能够检测出来了。一般默认的是64层,这就是多尺度检测!
我们可以看看detectMultiScale函数的源码
void HOGDescriptor::detectMultiScale(
const Mat& img, vector<Rect>& foundLocations, vector<double>& foundWeights,
double hitThreshold, Size winStride, Size padding,
double scale0, double finalThreshold, bool useMeanshiftGrouping) const
{
double scale = 1.;
int levels = 0;
//******************第一部分******************
vector<double> levelScale;
for( levels = 0; levels < nlevels; levels++ )
{
levelScale.push_back(scale);
if( cvRound(img.cols/scale) < winSize.width ||
cvRound(img.rows/scale) < winSize.height ||
scale0 <= 1 )
break;
scale *= scale0;
}
levels = std::max(levels, 1);
levelScale.resize(levels);
//*********************************************
std::vector<Rect> allCandidates;
std::vector<double> tempScales;
std::vector<double> tempWeights;
std::vector<double> foundScales;
Mutex mtx;
//****************第二部分************************
parallel_for_(Range(0, (int)levelScale.size()),
HOGInvoker(this, img, hitThreshold, winStride, padding, &levelScale[0], &allCandidates, &mtx, &tempWeights, &tempScales));
//**********************************************
std::copy(tempScales.begin(), tempScales.end(), back_inserter(foundScales));
foundLocations.clear();
std::copy(allCandidates.begin(), allCandidates.end(), back_inserter(foundLocations));
foundWeights.clear();
std::copy(tempWeights.begin(), tempWeights.end(), back_inserter(foundWeights));
//********************第三部分***********************
if ( useMeanshiftGrouping )
{
groupRectangles_meanshift(foundLocations, foundWeights, foundScales, finalThreshold, winSize);
}
else
{
groupRectangles(foundLocations, foundWeights, (int)finalThreshold, 0.2);
}
}
经时间测算,第一部分和第三部分时间大概只耗费很短的时间,98%以上的时间都耗费在了第二部分。看到
parallel_for_函数,自然而然地想到了平行计算!是的CPU也是可以有线程的,但是显然相比于GPU,CPU不是很擅长这个活(就计算而言,CPU很多线程都用来执行各种进程了)。
parallel_for_这个函数要搞明白我认为尚需时日,但或许不需要先了解那么清楚这个函数的的细节,先搞清楚一下这个函数是对什么进行并行计算的! 实际上,这是开辟Range(0, (int)levelScale.size())个线程来完成HOGInvoker(···)函数的计算。我们找到
HOGInvoker这个类别,可能乍一看,这个函数不就是个赋值的函数么?
class HOGInvoker : public ParallelLoopBody
{
public:
HOGInvoker( const HOGDescriptor* _hog, const Mat& _img,
double _hitThreshold, Size _winStride, Size _padding,
const double* _levelScale, std::vector<Rect> * _vec, Mutex* _mtx,
std::vector<double>* _weights=0, std::vector<double>* _scales=0 )
{
hog = _hog;
img = _img;
hitThreshold = _hitThreshold;
winStride = _winStride;
padding = _padding;
levelScale = _levelScale;
vec = _vec;
weights = _weights;
scales = _scales;
mtx = _mtx;
}
void operator()( const Range& range ) const
{
int i, i1 = range.start, i2 = range.end;
double minScale = i1 > 0 ? levelScale[i1] : i2 > 1 ? levelScale[i1+1] : std::max(img.cols, img.rows);
Size maxSz(cvCeil(img.cols/minScale), cvCeil(img.rows/minScale));
Mat smallerImgBuf(maxSz, img.type());
vector<Point> locations;
vector<double> hitsWeights;
for( i = i1; i < i2; i++ )
{
double scale = levelScale[i];
Size sz(cvRound(img.cols/scale), cvRound(img.rows/scale));
Mat smallerImg(sz, img.type(), smallerImgBuf.data);
if( sz == img.size() )
smallerImg = Mat(sz, img.type(), img.data, img.step);
else
resize(img, smallerImg, sz);
hog->detect(smallerImg, locations, hitsWeights, hitThreshold, winStride, padding);
Size scaledWinSize = Size(cvRound(hog->winSize.width*scale), cvRound(hog->winSize.height*scale));
mtx->lock();
for( size_t j = 0; j < locations.size(); j++ )
{
vec->push_back(Rect(cvRound(locations[j].x*scale),
cvRound(locations[j].y*scale),
scaledWinSize.width, scaledWinSize.height));
if (scales)
{
scales->push_back(scale);
}
}
mtx->unlock();
if (weights && (!hitsWeights.empty()))
{
mtx->lock();
for (size_t j = 0; j < locations.size(); j++)
{
weights->push_back(hitsWeights[j]);
}
mtx->unlock();
}
}
}
const HOGDescriptor* hog;
Mat img;
double hitThreshold;
Size winStride;
Size padding;
const double* levelScale;
std::vector<Rect>* vec;
std::vector<double>* weights;
std::vector<double>* scales;
Mutex* mtx;
};
其实学过C++的人就明白,operator函数就是一个运算符重载函数,它对“()”进行重载。而其中最主要的,也是最耗时的一步,我想大家一眼就看到了,经过时间测算,也的确是它--------detect!
我们再看到detect的源码
void HOGDescriptor::detect(const Mat& img,
vector<Point>& hits, vector<double>& weights, double hitThreshold,
Size winStride, Size padding, const vector<Point>& locations) const
{
hits.clear();
if( svmDetector.empty() )
return;
if( winStride == Size() )
winStride = cellSize;
Size cacheStride(gcd(winStride.width, blockStride.width),
gcd(winStride.height, blockStride.height));
size_t nwindows = locations.size();
padding.width = (int)alignSize(std::max(padding.width, 0), cacheStride.width);
padding.height = (int)alignSize(std::max(padding.height, 0), cacheStride.height);
Size paddedImgSize(img.cols + padding.width*2, img.rows + padding.height*2);
//***************************第一部分**************************
HOGCache cache(this, img, padding, padding, nwindows == 0, cacheStride);
//************************************************************
if( !nwindows )
nwindows = cache.windowsInImage(paddedImgSize, winStride).area();
const HOGCache::BlockData* blockData = &cache.blockData[0];
int nblocks = cache.nblocks.area();
int blockHistogramSize = cache.blockHistogramSize;
size_t dsize = getDescriptorSize();
double rho = svmDetector.size() > dsize ? svmDetector[dsize] : 0;
vector<float> blockHist(blockHistogramSize);
//*******************第二部分***********************
for( size_t i = 0; i < nwindows; i++ )
{
//********************一次for循环**********************
Point pt0;
if( !locations.empty() )
{
pt0 = locations[i];
if( pt0.x < -padding.width || pt0.x > img.cols + padding.width - winSize.width ||
pt0.y < -padding.height || pt0.y > img.rows + padding.height - winSize.height )
continue;
}
else
{
pt0 = cache.getWindow(paddedImgSize, winStride, (int)i).tl() - Point(padding);
CV_Assert(pt0.x % cacheStride.width == 0 && pt0.y % cacheStride.height == 0);
}
double s = rho;
const float* svmVec = &svmDetector[0];
#ifdef HAVE_IPP
int j;
#else
int j, k;
#endif
for( j = 0; j < nblocks; j++, svmVec += blockHistogramSize )
{
const HOGCache::BlockData& bj = blockData[j];
Point pt = pt0 + bj.imgOffset;
const float* vec = cache.getBlock(pt, &blockHist[0]);
#ifdef HAVE_IPP
Ipp32f partSum;
ippsDotProd_32f(vec,svmVec,blockHistogramSize,&partSum);
s += (double)partSum;
#else
for( k = 0; k <= blockHistogramSize - 4; k += 4 )
s += vec[k]*svmVec[k] + vec[k+1]*svmVec[k+1] +
vec[k+2]*svmVec[k+2] + vec[k+3]*svmVec[k+3];
for( ; k < blockHistogramSize; k++ )
s += vec[k]*svmVec[k];
#endif
}
if( s >= hitThreshold )
{
hits.push_back(pt0);
weights.push_back(s);
}
//*************************************************
}
//************************************************
}
对上述几个关键的部分进行时间测试:
第一部分: 20%的时间
第二部分: 80%的时间
一次for循环: 0.1ms左右
所以,时间消耗的地方我们终于找到了!20%的时间我们耗费在了HOG算子计算的前部分,80%的时间是HOG算子的计算以及处理。
针对上述结果,我及时调整了并行计算的改写方案:
第一阶段: 改写detect函数中的第二部分!也就是nwindows的那个for循环,每一个for循环开一个线程,一共开nwindows个线程。理由很显而易见,for循环整个时间占用很多,但是每次循环的时间却很短,这说明运行次数非常之多!这非常适合并行处理!
第二阶段: 改写detect函数的第一部分,正如(七)中的computeGradient函数改写一样,使其也并行计算!
其他不变,仍利用CPU的并行计算对64个尺度的图片进行并行处理!
下图为第一方案简单示意图:
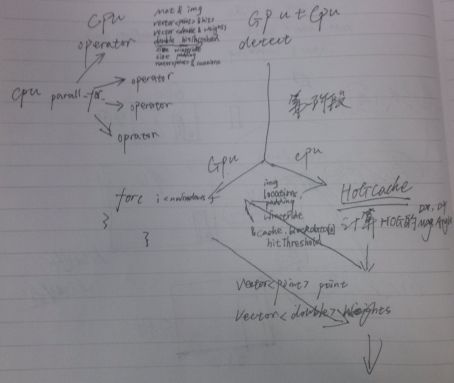
方案准备:
改写CUDA最主要的是数据交换,所以这里要搞清楚要输入什么数据,要输出什么数据
输入数据: 改写方案:
Mat& img ptrstep<uchar>, int img_h, int img_w
double hitThreshold
size winstride int winstride_w, int winstride_h
size padding int padding_w, int padding_h
BlockData* blockdata ptrstepsz<uchar3>
输出数据:
vector<point> point ptrstepsz<uchar3>
vector<double> weight ptrstep<uchar>
注:1.Mat img我计划输入的灰度图像,所以只能用ptrstep<uchar>类型承接,但是这个类型没有长度成员,所以只能将宽度和长度信息输入进去!
2.BlockData结构体包括了一个int和一个point类型,所以用三通道分别承接x,y和int;